I've been reading books of old legends and myth.
s gon na be a man who s gon na be a man who s gon na be a man who s gon na be a man who s gon na be a man who s gon na be a man who s gon na be a man who s ...
The words keep repeating themselves.
My repository: https://github.com/init27/LyricGenerator
Can someone please help me find the fault in this model? @Jeremy Is the problem because I’m using just two .txt files inside the test and train paths?
At first glance, it does not look like you are iterating when you are looping. My guess is you are feeding the same values into the model over and over while you loop instead of feeding in the previous output.
Because of an ASCII code issue, I had moved all the lyrics into a single .txt file and then converted the encoding to ASCII via a text editor. So I’m using a single file as the Path to Test and train set.
This is a common problem with text generation networks which is compounded when songs have a lot of repeating chorus. One non machine learning way of solving this issue is picking the top 5 most probable word instead of the top one which keeps the song from repeating.
I’m curious if there are a lot (more than prose) of unique/ different words…Perhaps remove a larger fraction of them?
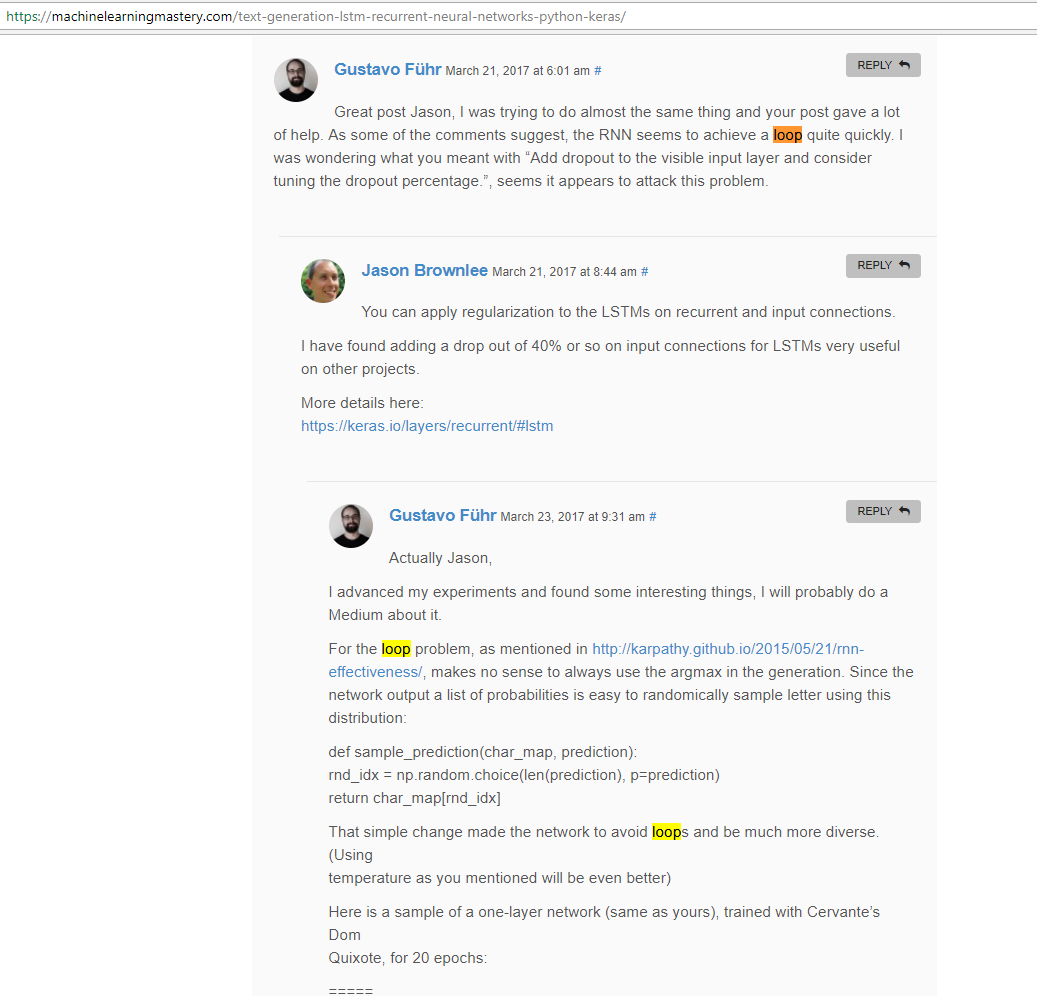
I had seen a similar ‘looping’ of characters while trying out Karpathy’s Char-RNN model, he mentions it briefly. Some people have observed better ways to come out of loops by
Not using the topmost choice for next word, but randomly sample from a top N list (increase N to make it more diverse)
Using better regularization and dropout choices.
I haven’t tried this lesson assignment fully so maybe you’re already doing these
Wouldn’t removing the unique words re-enforce the problem by increasing the probability of repetitive ones? Since most songs have tremendous repetitions (Particularly the old songs-which I realised after going through the data).
I’m trying the 2nd approach by tweaking the parameters, still no luck yet
@init_27 Hi Sanyam, I am interested in NLP as well. I found a blog post (with a paper) below. I think the " Eliminating Repetition with Coverage" session may help your problem conceptually. The interactive example is very cool. But, the system is not perfect yet.
Here a few ‘Lyrics’ generated from the model.
The starting word was ‘all’ and the rest are generated from the model. I’ve randomly picked a word for the next word in sequence from the top 3, as suggested by @lgvaz
all i ve seen a little i m not gon you go and be my you know i ve never seen the way to be a you know you got ta make you feel i got you like a i do you want me and i m not the same i do you want a girl and i do i know you want me you need me baby i love me i want you baby baby do me baby i love my do nt want you to do i need to do i want to…
I had used the US Top 100 songs of the past 50 years minus a few that I manually removed that were not in English.
So, about 4000 Songs (80-20 Train-Test split).