Hey Everyone!
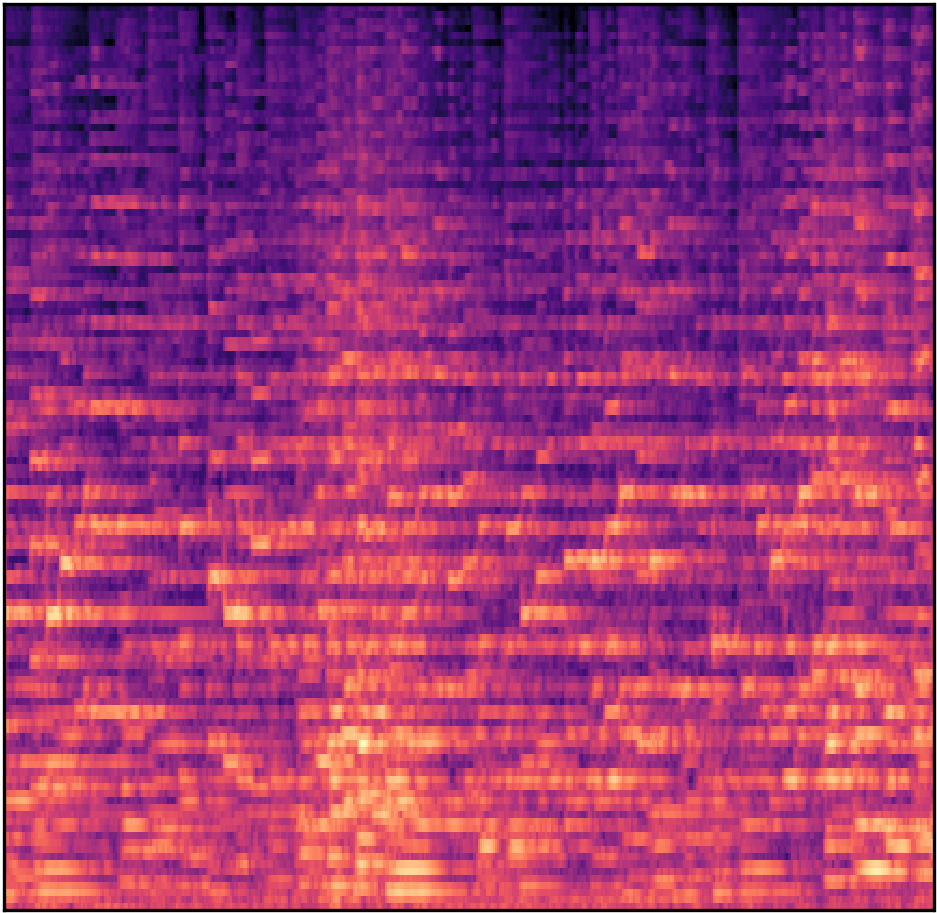
I am working on a music genre classifier where I’m converting an audio file into a spectrogram (image representing frequency vs time graph) image and train a CNN model.
The spectrogram of a 10 sec file looks like this:
I used the resnet34 architecture that was taught in Lesson 1 and 2 for cats and dogs classifier by @jeremy . I’m getting an accuracy of 55-60% from resnet34 model.
I wanted to know how can I improve the accuracy. BTW I provided 200/300 Images for each genre of 10 Genres from GTZAN Library for training.
Can anyone let me know that which lesson will help me in this scenario, and suggestions are also appreciated.
Are you using Fourier transform on the entire 10 sec window, or chunking it into 10 msec windows and using STFT? If the former, then you’re losing important spectral information by averaging over the sound wave, since sound is not a stationary signal.
Also, you might want to look at dense representation of audio like MFCCs, and model it using an RNN, rather than as an image classification problem. Maybe someone more experienced could help you out.
I’m still working through the first two lessons, but one thing that you could look at is fine-tuning more layers of the resnet34 model.
The model is trained on the ImageNet dataset, meaning that the last layers have features useful for classifying natural images - think cats, dogs, people, plants. Those features are things like eyes, textures, poses. See this part of lesson 1 for the visualisation of the features.
To classify the spectrogram, you would need to use more basic features (such as edges), meaning you will have to retrain deeper layers. The “Fine-tuning and differential learning rate annealing” section of lesson 1 has an example of doing this for cats vs dogs.
Thanks for info.
My senior also suggested to generate mfcc and then pass it to RNNs and LSTMs. I guess the image classifier approach is not right here.