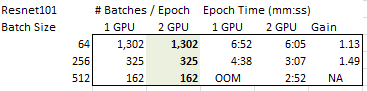
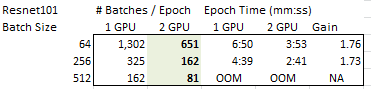
There seems to be some confusion on various forum posts about potential gains around using to_distributed and speeding up model training. I ran an experiment so that the results that can hopefully shed some light on the matter and help guide where it makes sense to try and use more than one GPU.
Starting with the documentation about launch a distributed model I setup a small script and then also a small bash shell script to launch the models. Scripts and results all posted here for others to replicate as they wish (and to replicate on machines with more than 2 GPUs to confirm that you can get further speed up in those cases.)
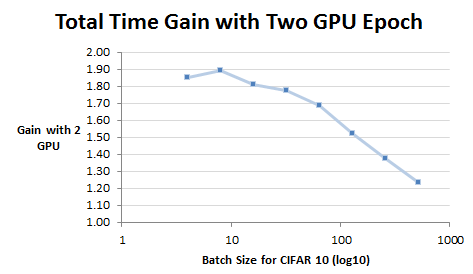
# Batch/Epoch Epoch Time (mm:ss)
bs 1 GPU 2 GPU 1 GPU 2 GPU Gain
4 12,500 6,250 15:17 8:16 1.85
8 6,250 3,125 8:02 4:15 1.89
16 3,125 1,562 3:48 2:06 1.81
32 1,562 781 1:59 1:07 1.78
64 781 390 1:04 0:38 1.68
128 390 195 0:35 0:23 1.52
256 195 97 0:22 0:16 1.38
512 97 48 0:21 0:17 1.24
From this data, I believe you get the biggest gains when you have small batches. If your batch size is large (64 in this case) you get very little gain for the extra hardware. I believe this is because as your batch size gets larger the number of batches per epoch goes down and you get less and less gain of running in parallel on two separate GPU cards.
So, I think that if you have a problem where you cannot load much on the GPU (either your model is large, your data is large or both) then going to more than a single GPU should help you reduce the time-per-epoch.
I am very curious if others have similar results/experience with this kind of test.
from fastai.vision import *
from fastai.callbacks.mem import PeakMemMetric
from fastai.distributed import *
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank",type=int)
parser.add_argument("--bs",type=int)
args = parser.parse_args()
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(backend='nccl',init_method='env://')
batch_size = args.bs
path = untar_data(URLs.CIFAR)
ds_tfms = ([*rand_pad(4,32),flip_lr(p=0.5)],[])
data = ImageDataBunch.from_folder(path,valid='test',ds_tfms=ds_tfms,bs=batch_size).normalize(cifar_stats)
print(f'bs: {batch_size}, num_batches:{len(data.train_dl)}')
learn = cnn_learner(data,models.resnet50,metrics=accuracy,callback_fns=PeakMemMetric).to_distributed(args.local_rank)
learn.unfreeze()
learn.fit_one_cycle(1,3e-3,wd=0.5,div_factor=10,pct_start=0.5)
Bash script for experiments:
#!/bin/bash
for bs in 4 8 16 32 64 128 256 512
do for gpus in 1 2
do
python -m torch.distributed.launch --nproc_per_node=$gpus time_distributed.py --bs=$bs
done
done