@piotr.czapla
Thank you for the quick and helpful reply.
I installed the fast.ai library from the master branch of fast.ai GitHub site. The version must be around v1.0.28.
I guess I can create your suggested scripts within a week or so.
Will let you know when I’m done.
@piotr.czapla i have finally train a french lm using sentencepiece and fastai 1.0.37.dev0 using codesnippets from you, @sgugger, @tomsthom .
The results are very preliminary: epoch, train error, valid-erros, accuracy 10 3.117836 3.239415 0.366795
there are still issues with the control tokens in fastai vs sentencepiece
Creating the databunch i had to scale down on the number of sentence due to the hugh memory consumption in TextLMDataBunch.from_csv/TextLMDataBunch.from_df etc. This could be reduced but i wonder what is the status of the merge of fastai with the version at "n-waves/ulmfit-multilingual"
For xnli, I am trying to take the lang filtered from xnli.dev.tsv (apparently for train) and corresponding test set and check the model against gold_label. The multinli.train.[lang].tsv is for translation baseline, so if I am not mistaken, the train_clas code (xnli) needs adjustments.
Buffer truncation is jut memory limitation error on colab.
@piotr.czapla, @eisenjulian
Hi how are you handling then tokenization/encoding with sentencepiece (SP)
Background:
I made a run with the following argument for SP:
special_cases=[
text.transform.TK_MAJ,
text.transform.TK_UP,
text.transform.TK_REP,
text.transform.TK_WREP,
text.transform.FLD ]
sp_params = f"–input={pathSrc_list} "
f"–eos_id=-1 "
f"–control_symbols={str_specialcases} "
f"–character_coverage=1.0 "
f"–model_prefix={model_prefix} "
f"–vocab_size={self.vocab_size} "
f"–model_type={self.model_type} "
I idea was to reserve ids for the special symbols. However, this does not work because fastai inserts BOS, FLD in the _join_texts i the Tokenizerprocessor before the tokenization. Sentenpiece will therefore ignore the symbols in order to prevent the user from manipulation the tokenizer. ie BOS and FLD gets decoded to something like x x b s and x x fld. Decoding BOS and FLD in this way will confuse rather than help a classifier
In order to preserve the symbols i am currently making a new run with
special_cases=[
text.transform.BOS,
text.transform.PAD,
text.transform.TK_MAJ,
text.transform.TK_UP,
text.transform.TK_REP,
text.transform.TK_WREP,
text.transform.FLD ]
sp_params = f"–input={pathSrc_list} "
f"–bos_id=-1 "
f"–eos_id=-1 "
f"–pad_id=-1 "
f"–user_defined_symbols={str_specialcases} "
f"–character_coverage=1.0 "
f"–model_prefix={model_prefix} "
f"–vocab_size={self.vocab_size} "
f"–model_type={self.model_type} "
This seems to works because now the tokenized cell start with. ▁ xxbos ▁ xxfld ▁1 ▁entre ▁1945 ▁et ▁1948,
Also what is the purpose of inserting BOS and FLD in _join_texts. Your copetion went well even with this confusing tokenization of BOS and FLD as above ?
Is it possible to resume language model training (from wiki tokens) if it stops after epoch n where n < num_epochs? I am training a language model and get buffer truncation error after which kernel stops but there are cls-history.csv, lm_1.pth, lm_2.pth in the model folder (it died in 3rd epoch).
It is awesome to hear that you managed to get a french language model. Have you used Sylvain code to split wikipedia by articles to train? It is super important as without it Language model train to some low perplexity but it fails on the downstream task. This is small bug was causing all the troubles with training classification on imdb to high values. (without the fixt I was getting ~80% accuracy up to 92%, with the fix I’m getting 94.5%)
The refactoring branch is compatible with the latest fastai
I haven’t played with the Sentence Piece yet, and the code is a bit outdated but I see your point. Maybe you can create the issue in the ulmfit-multilingual repo and we discuss there?
Your approach seems to make sense although let’s get it incorporated.
Kaspar, for the competition we used old fastai that didn’t have so many layers of abstraction, which gave us greater control over the tokenization we didn’t add “xxfld 1” as it would break the perplexity calculation. These fields are inserted by Fastai, I haven’t remove them yet as I was first focusing on getting good accuracy and I figured that a text that is added to every training example won’t cause issues. But I’m intending to get some more control over the tokens that are inserted to the text to clean this up and make it more standardized.
I do that from jupyter notebook where I can experiment with the learning rate. But I dont’ have example at hand. Simply create LMHyperParams object with all the paramters you put on command line, the create dataset and learn object and run learn.load(“lm_2”), then learn.lr_find() …
Thanks. Not sure if I am doing it right, but at first run the accuracy went down a lot (higher losses) at next epoch (ran 1, loaded lm_1 and ran another one epoch). Loss vs lr was flat on the left side (so bad output expected). On 2nd run (loaded lm_1 again), there was nice drop at 1e-5 - 1e-3. Does lm_1 get overwritten when I run fit_one_cycle? Here’s my code:
expm = pretrain_lm.LMHyperParams(dataset_path='/content/data/wiki/unknew',
base_lm_path=None, bidir=False,
qrnn=False, tokenizer='v', max_vocab=30000,
emb_sz=400, nh=1150, nl=3, clip=0.2,
bptt=70, lang='ar', name='Arabic')
learn = expm.train_lm(num_epochs=1, drop_mult=0.3)
learn.load('lm_1')
learn.lr_find()
learn.recorder.plot()
learn.fit_one_cycle(1, slice(1e-5))
first epoch (expm.train_lm(num_epochs=1, drop_mult=0.3)):
|epoch |train_loss |valid_loss |accuracy|
|1 |4.278293 |4.236993 |0.334256|
I am accounting for wiki articles issues by sampling the all wiki tokens.
Yep in the pretrain_lm. (Look for code that search for ‘=‘. Im away from pc.)But it works only with Wikitext-103 as our post processing does not separate articles.
I does get overwritten when you don’t remove callbacks. I would use create_lm_learner to get the learner so that you can work with it freely, train_lm may run some fitting.
yes i am cleaning the wiki article like you and sylvain. I will make an english model and verify accuracy of the sentencepiece <=> fastai integration using the imdb-notebook.
In train_clas.py, there is this property:
@property
def need_fine_tune_lm(self): return not (self.model_dir/f"enc_best.pth").exists()
so, I guess if the enc_best is absent, it’ll fine-tune.
I can see some impressive work being done in ulmfit-multilingual. Thanks a lot to everyone involved!
I would like to use it and contribute, but I find some things quite confusing.
Starting at the beginning - what is that repo meant to be?
- the code has to be adapted for languages where spacy tokenization is not an option, training scripts and results have to be stored etc. Hence the “-multilingual” in the name.
- I also see more development of code and ideas: bi-directional language models, qrnn fix, etc. Will most development of ULMFiT-related ideas be happening there? (I am trying out some tweaks to this approach, not sure where could I discuss & possibly share them)
- If I am not mistaken, reproduction of the original ULMFiT paper results (including language model training from wikitext) is not really possible using fastai v1 and https://github.com/fastai/fastai/tree/master/courses/dl2/imdb_scripts Is the
refactorbranch ofulmfit-multilinguala better option to try?
@piotr.czapla I already have some very small things to contribute to ulmfit-multilingual, could I get write permissions, or do you prefer pull requests from forks? my handle: tpietruszka
I tried my Arabic model on a sample of 5k of Yelp reviews - Polarity machine translated En2Ar (4k train, 1k valid). The notebook shows reasonable results (~88%) using the recipe from https://docs.fast.ai/text.html but very poor using the inference tutorial with notebook here. I must be doing something wrong in the 2nd approach.
Anyone did comparable work on non English language model using V1 and @piotr.czapla 's refactor work?
Got 96% accuracy on Arabic sentiment polarity classification (compared to 94.4 current bench mark).
5 Likes
Hi @AbuFadl , I had a look at your kernel and I have a question. I assume that the last thing you show there is the test set, then I’ve noticed some text is written in english rather than arabic. Is your dataset occasionally bilingual ?
Thanks for asking. Yes, some reviews had mixed text and I left the dataset as provided by the original authors to compare performance (see 1st cell in the kernel for citation).
Attention folks working on NLP: starting with 1.0.38 fastai now assumes batch is the first dimension everywhere (it helps us in terms of API behind the scenes) which means text too. So some scripts might need a bit of adjustment (everything in fastai has been updated for that change).
This should be the last breaking change and you can expect a more stable API now.
6 Likes
I looked at the paper you cited no mentions about the amount of english text in the dataset. What makes me a bit confused are the reviews, like the ones in the photo below, that your model correctly classifies.
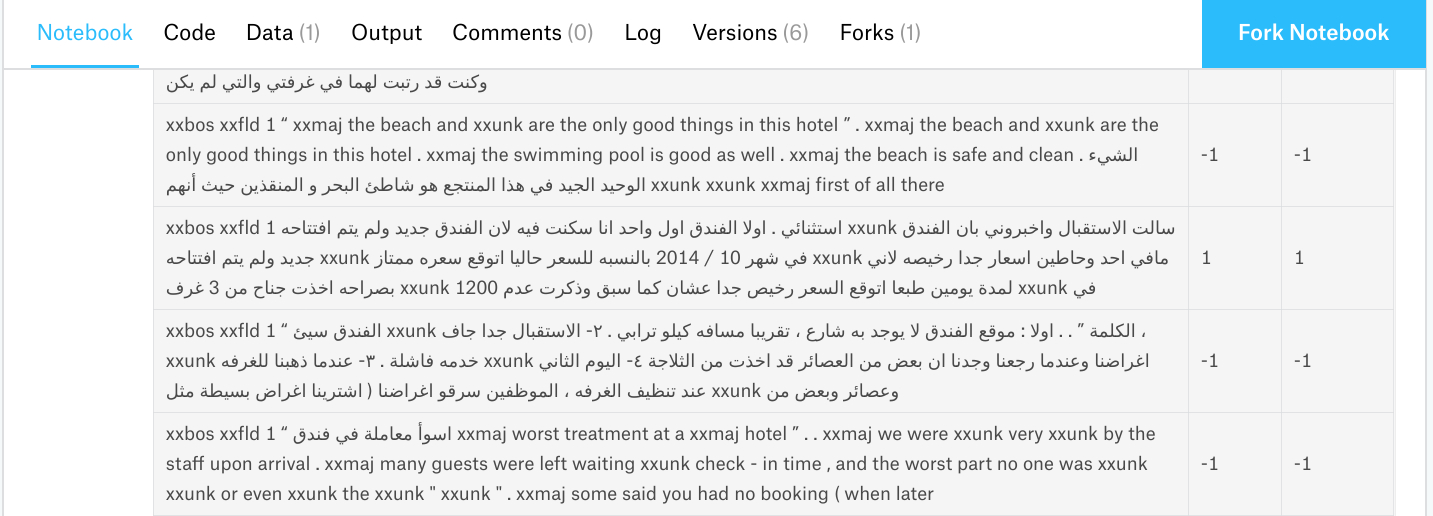
As you can see, very small signal, in terms of arabic words under the assumption that english words are oov terms, is present in there. which corpus did you use to train your lm on ?
Model was trained on part of Arabic Wikipedia dump. The articles contain some English (and less of other languages). If you look at the text that has “are the only good things in this hotel”, this review is around 400 words long, 170 are Arabic and the rest English, so most likely class is determined by the Arabic part.