This thread is to discuss changes and updates for training ULMFiT models on multiple languages. The idea is twofold:
We want to make it easy for people to download and train models on Wikipedia (or potentially CommonCrawl in the future) in any language.
We want to provide a model zoo consisting of pretrained language models in many languages that people can then simply fine-tune for their own applications.
The previous ULMFiT scripts consisted of multiple steps (and separate preprocessing), so we’d also like to streamline the process of training and fine-tuning a language model as much as possible.
The LM pretraining script (see here): I think we should keep the script to pretrain the language model as simple as possible. As the Wikipedia datasets are already tokenized using Moses, we don’t need to tokenize in this script. It also seemed cleaner to build the vocabulary and convert the tokens to ids directly in the script.
The classifier training script (see here): I’m not really sure what’s the best way to preprocess this. I’ve now added the option to do a manual preprocessing like before so that we use the same tokenizer. Ideally, I’d like to use the fast.ai methods for building the vocabulary and preprocessing, but there are some unclear issues (see below).
Config file: I think it’d be a good idea to save the hyperparameter settings of the trained model to a config file, in order to avoid a parameter mismatch between the saved and loaded model.
Suggestions:
The LM pretraining (see here): Using the TextLMDataBunch.from_ids method does not work as BaseTextDataset has no attribute loss_func, which is required during training. I instead created a placeholder class DataStump as a work around. It would be nice if this could be handled directly in the method. This could be done with LanguageModelData in the previous version, which no longer exists.
The classifier training script (see here): What I find unintuitive when using the fast.ai methods is that when tokenization is used, the special field identifier is automatically prepended to the input (see here). People who are not familiar with fast.ai will probably miss this, which can lead to confusion. It would be good if all the preprocessing and special rules was specified in the tokenizer. The same applies to the vocabulary: The token for unknown words is <unk> by default in the WikiText datasets and in a lot of datasets, so it’d be nice to keep using this. The fast.ai Vocab currently hardcodes the UNK value (see here).
RNNLearner.language_model and RNNLearner.classifier should allow to set the dropout values rather than hard-coding them. For QRNNs, I’d have to use the more verbose formulation of get_language_model, RNNLearner, which is even more code for defining the classifier.
After pulling the last changes, I get the following error: File "/home/ubuntu/fastai/fastai/basic_train.py", line 216, in on_train_begin self.pbar.write(' '.join(self.names), table=True) TypeError: write() got an unexpected keyword argument 'table', which seems related to drawing the progress bar.
Big remaining todos:
QRNN training is still slow/defective since some recent update. Need to look into that.
Add subword tokenization and support training with subword units.
Do you mean you get an error later? I can certainly put a default there of F.cross_entropy.
We can certainly add a parameter to not put those field tags, but it would still be the default since the fastai pretrained model is trained on a corpus that has been processed like this. Note that the two unknown tokens were already present in the pretrained model of fastai v.07 ( and xunk IIRC). I’m guessing we could add a default rule that maps to UNK. Note that you can add all the custom rules you like very easily.
That was a discussion with Jeremy and we felt that for beginners, it was easier to just have one hyper-parameter to set, the multiplicator of those dropouts, and hard-code values we know work well. A more advanced user can easily copy the constructions functions to create his customized model. That being said, we can make it easy by having global constants contain those arrays of dropouts, for easier modifications.
@sebastianruder , it is exactly what we planned to do with @mkardas , we have quite a few changes and fixes thrown in many places in the Poleval repository and ULMFi-de. The plan was to move our changes to fastai-v1 and get the ulmfit scripts updated. I would be happy to contribute.
I’ve merged @sebastianruder changes with master branch and created a new branch ulmfit_multilingual in my fastai fork.
While I was adopting the code to recent changes I’ve noticed that fastai.text has some type warnings and inconsistencies so I think it is still a work in progress. Which means that we should have a way to smoothly pull changes from master and propose PR with our fixes to the master branch of fastai. I see two options to do so:
start development of ulmfit in a fork of master branch and occasionally create pull request with fixes and our changes to ulmfit
extract ulmfit code to a separate repo.
Initially, I was for 1, but after some thoughts 2 sounds like a better alternative as we will have quite a few changes to the ulmfit:
new tests to the ULMFiT scripts to be able to quickly check if they work after each refactoring of fastai
scripts to run ulmfit on XNLI
language-specific scripts to play and test with different classification datasets.
notebooks to test BERT against ULMFiT on text classification etc.
It seems to work okey I’m training LM on WT-2 as follows:
$ python -m ulmfit.pretrain_lm data/en/wikitext-2 --qrnn=False --name=wt-2
And we indeed have a memory issue in fastai,
First epoch started with 7GB after 8th it consumed 10.3G
@sebastianruder, @sgugger I can still see the issue with qrnn even though I’m on the fresh copy of master branch. Could you point me to some configuration where qrnn was working fine?
I don’t see pretrain_lm in the old fastai branch (I’ve checked my old branch and ulmfit_cleanup
QRNN works just fine if you run lr_find before hand. If you don’t it does not coverage. So it has to be due to some hooks that are getting installed when lr_find() is executed. I will have a look later I need get some sleep before the lecture.
@sebastianruder@sgugger the issue with qrnn disappears after the second run to fit, this could be a workaround for the scripts until we find out why this is happening.
I’ve found the issue and it is quite odd it might be caused by different cuda version or different pytorch version on Monday I can make a sample test case to double check this.
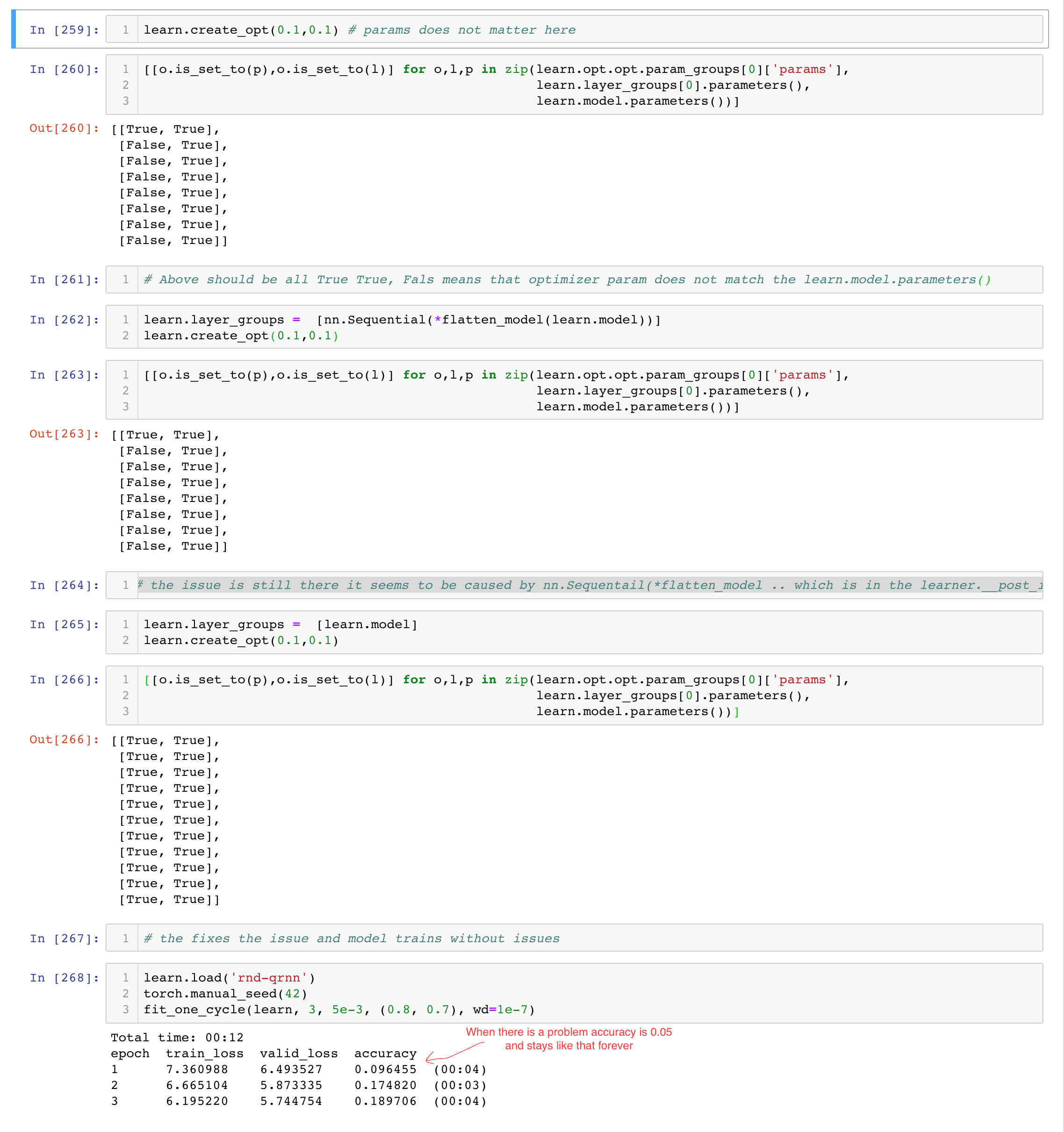
What was causing the issue on my side was that learn.opt is getting copies of the parameters of the model during first fit, during second execution the issue disappears.
To fix the issue without running fit I had to overwrite
if not self.layer_groups: self.layer_groups = [nn.Sequential(*flatten_model(self.model))]
but apparently, it does make copy (see screenshot in the next post).
Moreover, if this is the copy why normal LSTM works at all, That is why I think this might be caused by some miss match between cupy / cuda / pytorch versions. It would also explain why you don’t see the issue.
The issue disappear for fit but not for fit_one_cycle , but fortunately running lr_find() fixes it for both functions so this will be our workaround until we manage to pinpoint the issue. @sebastianruder If you want to play with QRNN over the weekend I’ve pushed the changes, I will be back on Monday.
Btw. @sgugger I’ve read through large chunk of fastai v1 today, and I’m full of respect to how well though and nicely it is written!
First thing I did, after you suggested it. Don’t worry I like this kind of challange. Besides I’m super close to getting that fixed :), and we have a workaround.
I am working on hindi language model and text classification ,as i followed the steps on ulmfit-multilingual repo , i was unable to find some files create_toks.py, ‘tok2id.py’,‘finetune_lm.py’,‘eval_clas.py’,‘predict_with_classifier.py’.
This are old steps.
Now we need text tokenized using Moses, selsforce wikitext is already tokenized this way, you might find other Wikipedia’s as well prepared like that, I think @sebastianruder was mentioning that.
Then in such text you can just directly use the pretrain_lm no need to create nymphs with tokens.
If this is not ready it could be your contribution to the repo. Make the wikidump preparation a one command line script that takes the language argument and fetched the data (do tokenization using Moses if necessary, and stores it in a folder ‘data//<size 2, 100, all>’.Then update the readme.md. How does it sounds?
There are already scripts to tokenize the Wikipedia files. We now just need the same tokenization when fine-tuning the LM. I’m traveling today, so will only have access to email again on Monday.
 (I’ve checked my old branch and ulmfit_cleanup
(I’ve checked my old branch and ulmfit_cleanup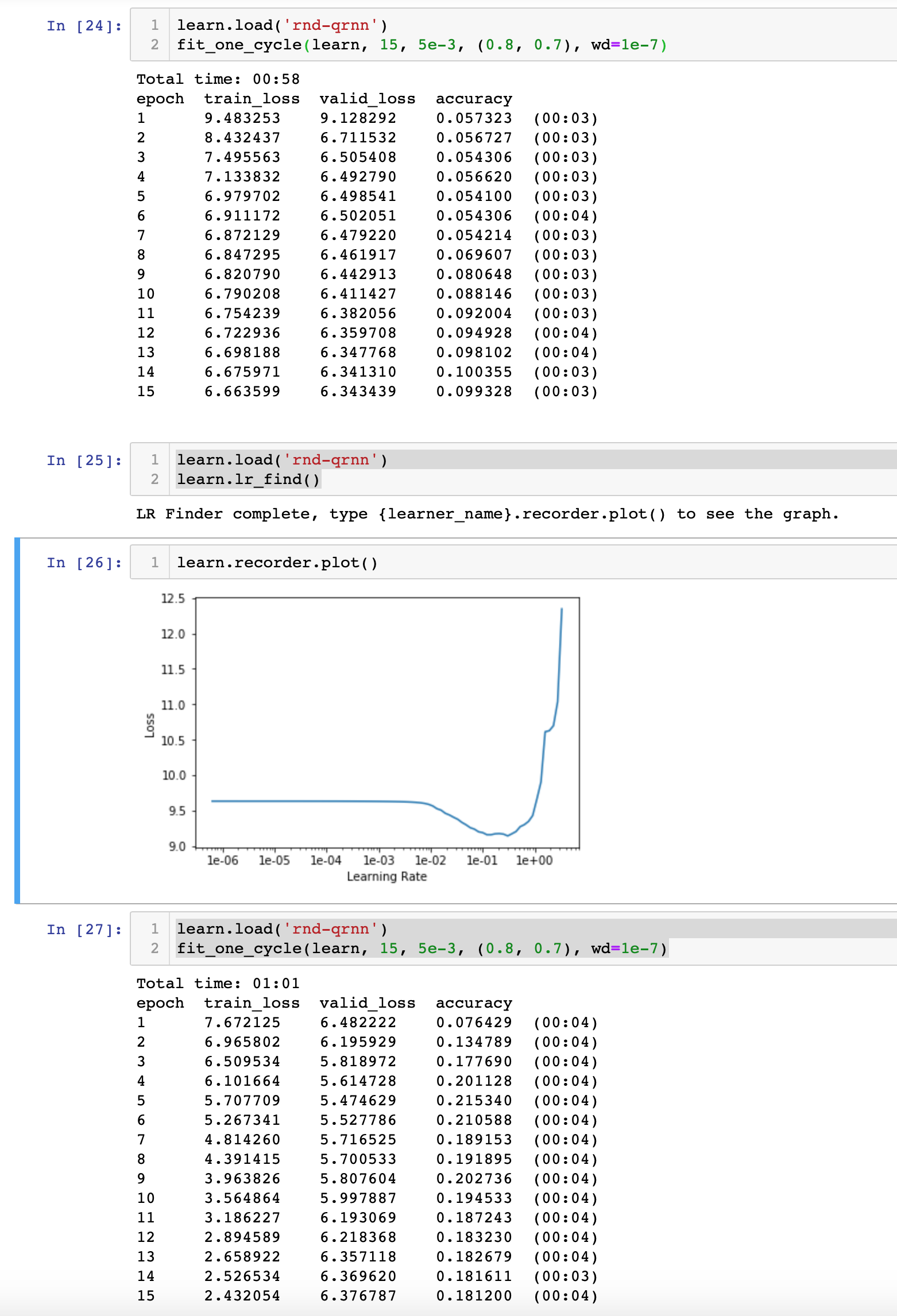
 , but fortunately running lr_find() fixes it for both functions so this will be our workaround until we manage to pinpoint the issue.
, but fortunately running lr_find() fixes it for both functions so this will be our workaround until we manage to pinpoint the issue.