Hi
I’m training a multilabel classifier with metrics as accuracy_thresh and fbeta score.
However, the following is happening
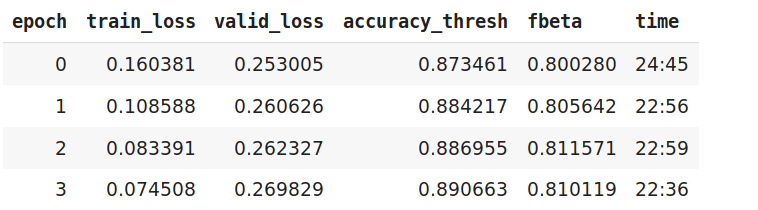
The valid loss is increasing, however the metrics are improving.
Any idea what is happening here?
Hi
I’m training a multilabel classifier with metrics as accuracy_thresh and fbeta score.
However, the following is happening
The valid loss is increasing, however the metrics are improving.
Any idea what is happening here?
can you share code?
That can happen theoretically at least
It would mean that the model is getting more certain about the correct results and at the same time making more mistakes
EDIT: Everything I said but the other way around lol
Accuracy doesn’t care how certain are the results, right? It’s either right or wrong (this is why it’s not a great loss function). The loss function on the other hand cares about the certainty
Should I chose a threshold in a way that loss decreases with metrics increasing?
its the standard code shown in the lesson.
In my work, I generally take the halt of validation loss to mean that further epochs aren’t really improving anything - an increase in metrics is likely a coincidence from this point forward, and fitting further will actually decrease the performance of ensemble models (very common in my field) that use the current model’s predictions as an output.
you mean to say that I should chose a model with lowest valid_loss even though it might not have the best fbeta?
No, I’m not saying that, I was just trying to say that the results you’re getting are theoretically possible and it’s not a bug
This happens a lot, as long as the metric you care about increases you don’t need to worry about the loss, if both goes in the wrong direction then the model is overfitting. Jeremy explained this in one of the videos I will link it if I find it.
@vijayabhaskar that’ll be helpful if you can share the link 
I don’t agree with @vijayabhaskar about “as long as the metric you care about increases you don’t need to worry about the loss”.
There should be some other things to be checked.
I think that models is slightly overfitting and this is why validation loss is increasing. Even if it returns a high accuracy, I don’t say that it will generalize unseen scenarios better. Btw, I can say that it isn’t a severe overfitting issue (that’s why I say slightly).
Yeah, you’re right. Past me is wrong.