I am performing multi-class image segmentation where the features overlap. Therefore I am stacking the masks so that the label in the dataset is formatted as [N_features, sz, sz]. Pasted below is my subclassed SegmentationLabelList. When I try to train the dynamic unet, I receive a runtime error: RuntimeError: grid_sampler(): expected input and grid to have same dtype, but input has long and grid has float. The Fastai library function open_mask treats pixels as longs rather than floats. Is that the issue? Subclassing the ImageSegment class and making data() return a tensor as a type .float() instead of .long() resulted in the same runtime error.
Yes the ImageSegment return tensors with ints so that the loss function for single classification segmentation works properly. In your case, you need to subclass ImageSegment so that its data attribute returns a float tensor and not an int tensor, then use that classin your custom SegmentationLabelList.
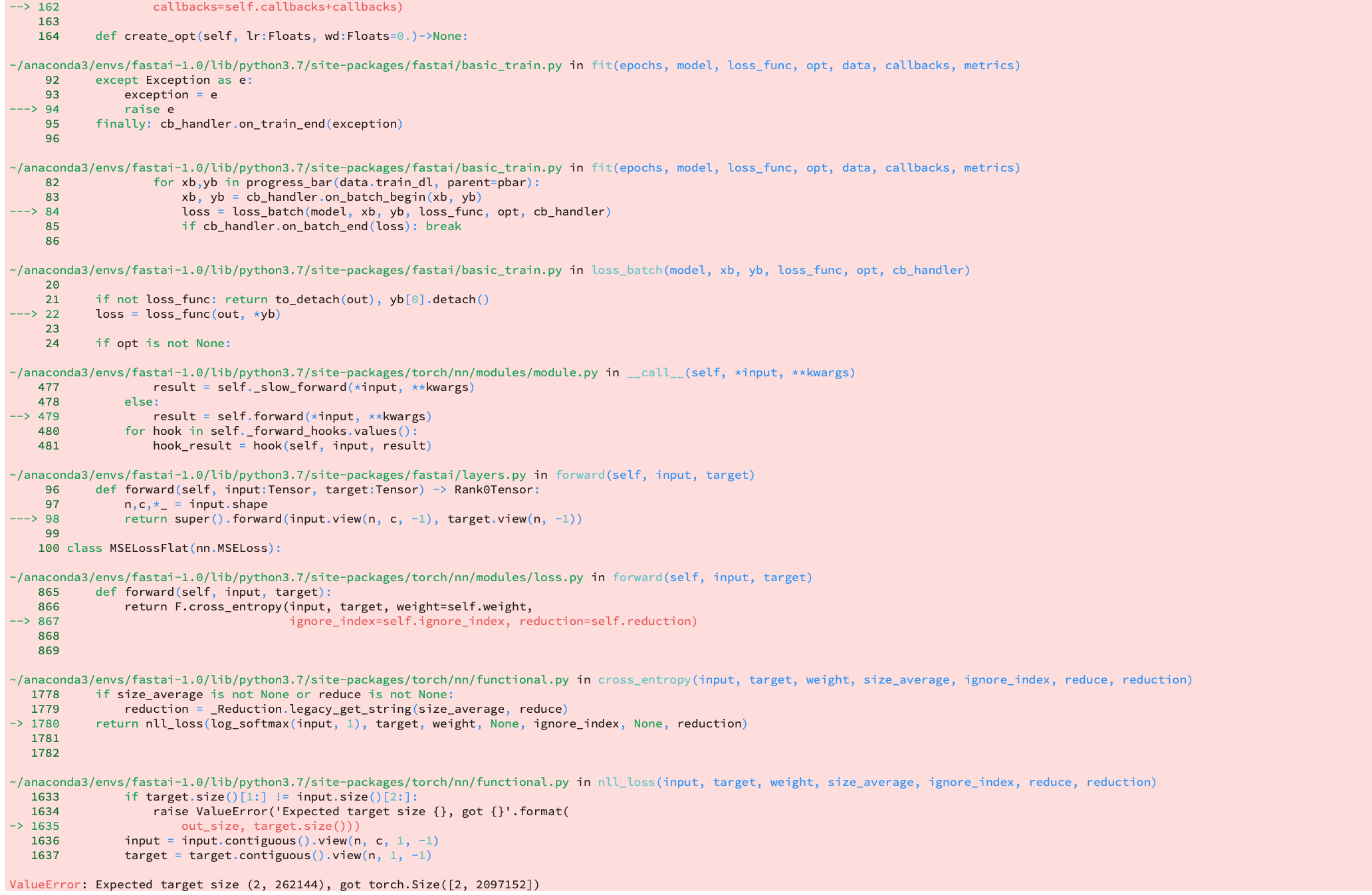
Thank you for your quick reply and help! So I already subclassed ImageSegment so that calling data returns a float tensor instead of a long tensor, yet I still received the same runtime error. I also just altered the constructor to see if casting the ._px value as a FloatTensor would fix the problem. Doing that seems to have broken the loss function. I can paste the full error stack below. The runtime error changed to ValueError: Expected target size (3, 262144), got torch.Size([3, 1835008]).
> class ImageSegment2(ImageSegment):
> def __init__(self, px:Tensor):
> "Create from raw tensor image data `px`."
> self._px = px.type(torch.FloatTensor)
> self._logit_px=None
> self._flow=None
> self._affine_mat=None
> self.sample_kwargs = {}
>
>
> @property
> def data(self)->TensorImage:
> "Return this image pixels as a `FloatTensor`."
> return self.px.float()
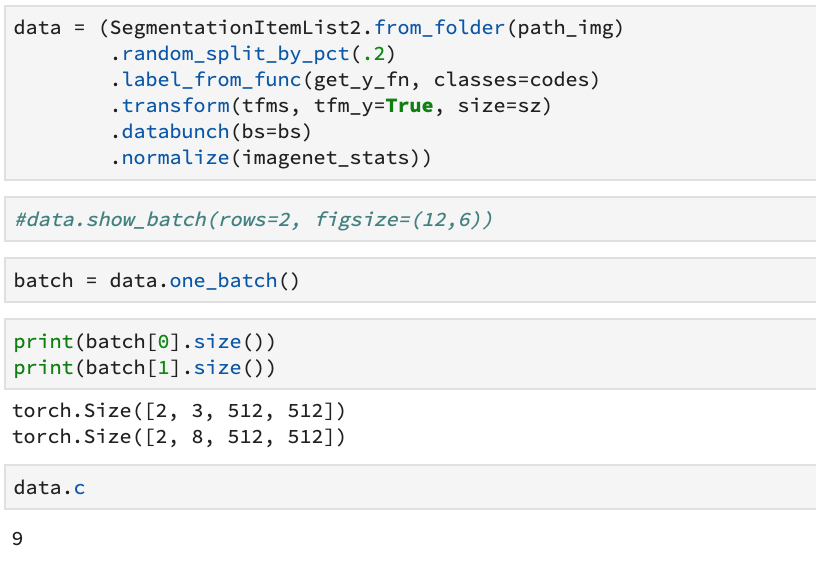
Did you check the size of an output too? What’s the value of data.c? This is what will be used to dertermine the number of channels of the output and from your error message, given your input size, it looks like it’s 1 right now, instead of 8.
It’s taking it from the ys in the training set, which is inferred from your data normally. So if data.c is 9, your output should be bs by 9 by 512 by 512 which is inconsistent with your error message. Also it’s weird if your target has 8 channels.
When I removed “Background” as one of the classes to predict, data.c became 8. Yet when I run the model the same runtime error occurs. Including “Background” as a class worked when segmenting binary masks.