Hello,
[EDIT: I found a way to made the code work in the doc, namely:
dls0 = ImageDataLoaders.from_df(df, path, folder='train', valid_col='is_valid', label_delim=' ',
item_tfms=Resize(460), batch_tfms=aug_transforms(size=224))
but this doesn’t explain why the code below should fail. Not sure if should open an issue]
I’m doing a walk through on Chapter 6 with Kaggle (having no possibility to run fastai code locally)
It turns out that, for now, the code is bugging as soon as I specify that my datablocks handle MutliCategory problems. I made a https://www.kaggle.com/pierrevial/multicategory-attempt with a minimal example. I give the whole code below this post because I may remove this notebook in the future.
As you may see, strange errors appear whether multicategory is specified (files not found), or not specified (maximum recursion depth when calling show_batch)
So, I would really appreciate if someone could tell me what’s going wrong here!
Best,
Pierre
!pip install -Uqq fastbook
import fastbook
fastbook.setup_book()
from fastbook import *
from fastai.vision.all import *
path = untar_data(URLs.PASCAL_2007)
df = pd.read_csv(path/'train.csv')
df.head()
def splitter(df):
train = df.index[~df['is_valid']].tolist()
valid = df.index[df['is_valid']].tolist()
return train,valid
dblock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
get_x = lambda r: r['fname'],
get_y = lambda r: r['labels'],
splitter=splitter)
# Note: If [blocks=(ImageBlock, MultiCategoryBlock)] is commented,
# then the variables [dsets] and [dls] below are well-defined (in the sense
# they do not cause an error)
dsets = dblock.datasets(df)
# error: file not found
dls = dblock.dataloaders(df)
# error: file not found
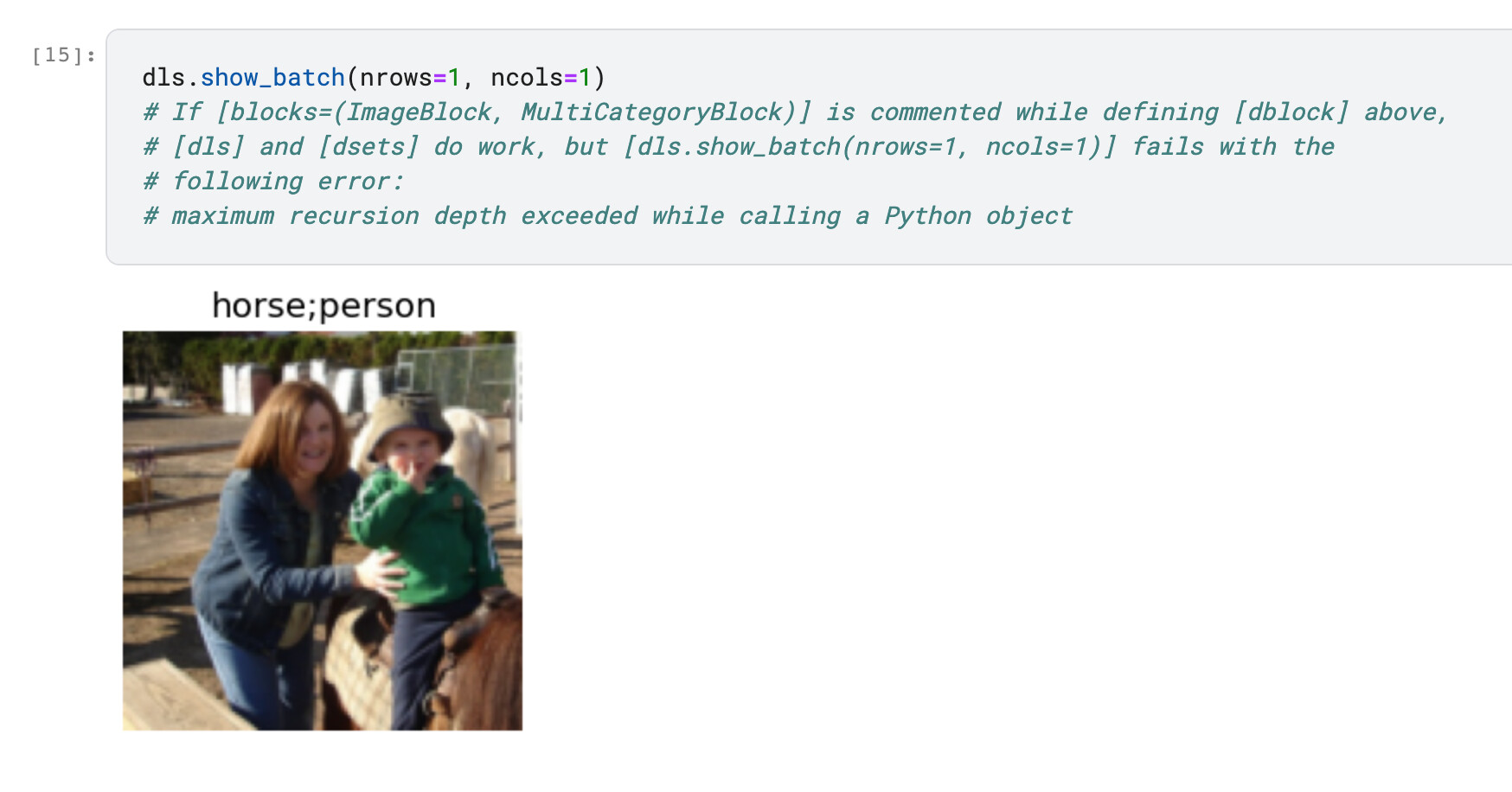
dls.show_batch(nrows=1, ncols=1)
# If [blocks=(ImageBlock, MultiCategoryBlock)] is commented while defining [dblock] above,
# [dls] and [dsets] do work, but [dls.show_batch(nrows=1, ncols=1)] fails with the
# following error:
# maximum recursion depth exceeded while calling a Python object