When I asked you I hadn’t tried yet and after you replied to me, I changed the batch_tfms I had on the DataBlock object for the following:
batch_tfms= [*aug_transforms(do_flip=False, size=(120,160)), Normalize.from_stats(*imagenet_stats), BBoxReshape]. I didn’t get any error.
I inform you I managed to solve the error of show_batch function. As I told you I changed the batch_tfms function and also I changed the custom_bb_pad function I had created. Next, I post the current state of the custom_bb_pad function:
def custom_bb_pad(samples, pad_idx=0):
"Function that collect `samples` of bboxes and adds padding with `pad_idx`."
#samples = [(s[0], *clip_remove_empty(*s[1:])) for s in samples] # s[0] is a tuple of TensorImage & TensorBbox, TensorBbox size is (2,4)
max_len = max([len(s[1]) for s in samples]) # equals to 4 (number of bbox coordinates)
def _f(img,bbox):
bbox = torch.cat([bbox,bbox.new_zeros(max_len-bbox.shape[0], 4)])
return img,bbox
return [_f(*s) for s in samples]
Due to the fact that you told me to keep the bbox shape at 2x4 on the bb_pad_function I added the line “bbox = torch.cat([bbox,bbox.new_zeros(max_len-bbox.shape[0], 4)])” of the original function (bb_pad function) that I had removed.
Now I can run the notebook with no errors until the line “learn.export(‘trained_roi_detetor_resnet_export.pkl’)” where I get the error: “PicklingError: Can’t pickle <function at 0x0000020C8F432708>: attribute lookup on main failed”.
I’ve made research about this error and from what I’ve understood it’s produced because the learn.export function isn’t compatible with the use of lambda functions in the code.
I tried the solution proposed by user asoellinger on the topic:
Learn.export() failing "PicklingError: Can't pickle <function <lambda> at 0x7f60e83e6bf8>: attribute lookup <lambda> on __main__ failed" - #3 by andandandand.
I installed “dill” package, added the line “import dill” and converted the export function to: learn.export(‘trained_roi_detetor_resnet_export.pkl’, pickle_protocol=dill).
I got an error saying “TypeError: an integer is required (got type module)”.
As this solution didn’t worked for me, I tried to find an alternative to the use of lambda. The line that is causing the error of the export function is “get_y=[lambda o: get_bboxes(o.name)]” from the DataBlock object.
So, I changed “get_y=[lambda o: get_bboxes(o.name)]” to “get_y=[get_bboxes(o.name) for o in get_image_files]” but I got an error saying “TypeError: ‘function’ object is not iterable”.
I don’t know how to solve the error associated to the learn.export() function.
Plus, I want to ask you if it’s normal that the status bar of the epochs completed shown as output to the learn.lr_find doesn’t reach the 100% when the execution of the lr_find function ends.
It happens only on the second time I use learn.lr_find, it’s after calling learn.unfreeze(). The first time I use learn.lr_find() it’s after calling learn.freeze(-1) and in this time the output at the end of lr_find execution doesn’t show any status bar.
The following image I post shows the issue of the status bar I mentioned before:
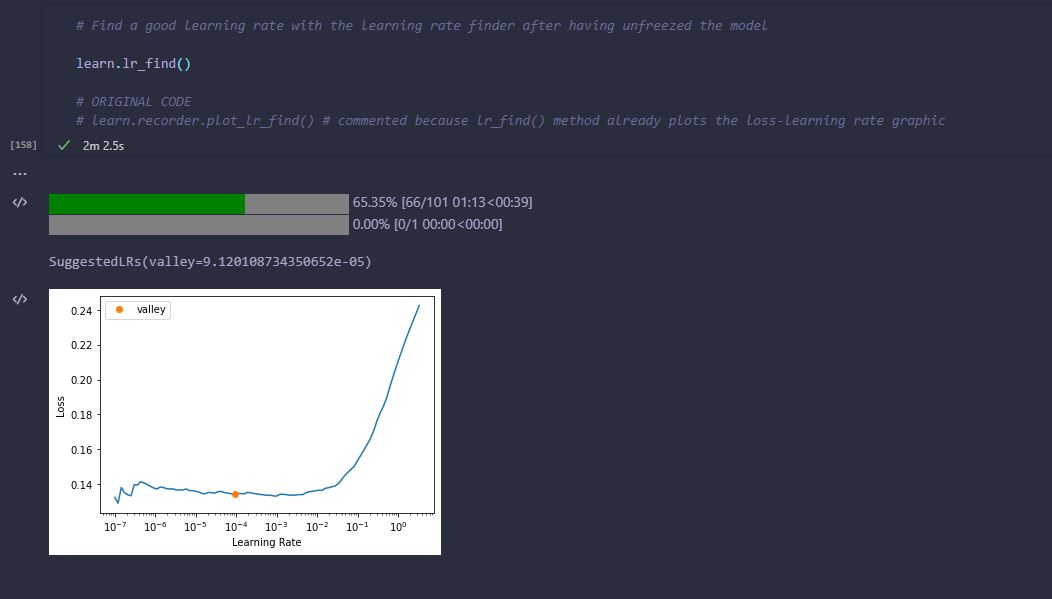
But I’ve to say that in both learn.lr_find() calls the tables shown as output to fit_one_cycle are full. On the first part that is after freezing the model, when I call fit_one_cycle(n_epochs=100) the table has 100 entries and on the second part that is after unfreezing the model I call fit_one_cycle(n_epochs=200) and the output’s table has 200 entries. I say this because I thought that on the second part if the status bar of the epochs completed didn’t reached the 100% maybe the output’s table of fit_one_cycle wouldn’t be full, but it’s not the case.
I hope you know how I can solve the error of learn.export() function and I hope you can also help me understand if it’s a problem that the status bar of the epochs completed doesn’t reach the 100% or if it’s normal.
Thank you so much for all your help. I’m glad that at least today the error of the show_batch function got fixed, although as you can notice I’m dealing with a lot of errors due to the fact that I’m adapting the notebook of my professors that was done to create just one 1 bbox for each image whereas for my project I need to create 2 bboxes for each image. Hopefully I can make the whole notebook functional soon.