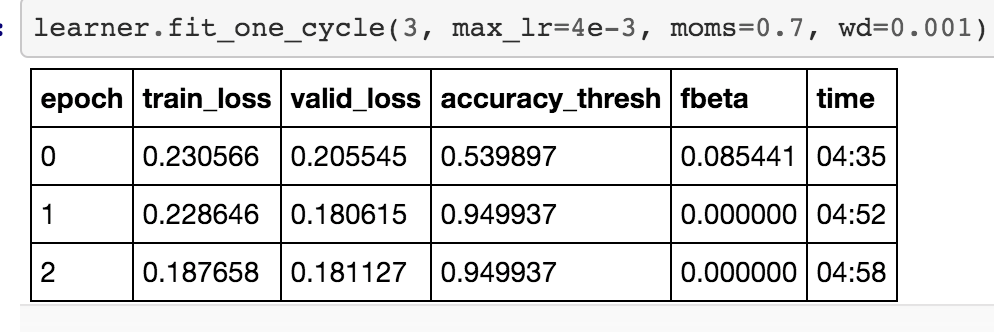
I was able to get this work. For now, running with one classification column, but this should be adaptable.
class Config(dict):
def __init__(self, **kwargs):
super().__init__(**kwargs)
for k, v in kwargs.items():
setattr(self, k, v)
def set(self, key, val):
self[key] = val
setattr(self, key, val)
config = Config(
bert_model_name="bert-base-uncased",
num_labels=2, # 0 or 1
max_lr=2e-5,
epochs=3,
batch_size=8,
max_seq_len=500
)
Tokenizers
class FastAITokenizer():
def __init__(self, model_name: str, max_seq_len: int=128, do_lower_case: bool=True, **kwargs):
self.bert_tok = BertTokenizer.from_pretrained(model_name, do_lower_case=do_lower_case)
self.max_seq_len=max_seq_len
def bert_tokenizer(self, pre_rules=[], post_rules=[]):
return Tokenizer(tok_func=FastAIBertTokenizer(self.bert_tok, max_seq_len=self.max_seq_len), pre_rules=[], post_rules=[])
def fastai_bert_vocab(self):
return Vocab(list(self.bert_tok.vocab.keys()))
class FastAIBertTokenizer(BaseTokenizer):
"""Wrapper around BertTokenizer to be compatible with fast.ai"""
def __init__(self, tokenizer: BertTokenizer, max_seq_len: int=128, **kwargs):
self._pretrained_tokenizer = tokenizer
self.max_seq_len = max_seq_len
def __call__(self, *args, **kwargs):
return self
def tokenizer(self, t:str) -> List[str]:
"""Limits the maximum sequence length"""
return ["[CLS]"] + self._pretrained_tokenizer.tokenize(t)[:self.max_seq_len - 2] + ["[SEP]"]
class BertLearner(Learner):
# https://github.com/huggingface/pytorch-pretrained-BERT/issues/95
def unfreeze_all_layers(self)->None:
for name, param in self.model.named_parameters():
param.requires_grad = True
def freeze_embeddings(self)->None:
for name, param in self.model.named_parameters():
# FIXME: check if any batchnorm layer present, set to False
if ('embeddings' in name) or ('LayerNorm' in name):
param.requires_grad = False
else:
param.requires_grad = True
def freeze_encoders_to(self, n=12)->None:
for name, param in self.model.named_parameters():
index=100000
if 'encoder' in name:
index=[int(s) for s in name.split(".") if s.isdigit()][0]
if ('embeddings' in name) or ('LayerNorm' in name) or index < n:
param.requires_grad = False
else:
param.requires_grad = True
def freeze_all_layers(self):
for name, param in self.model.bert.named_parameters():
param.requires_grad = False
def print_trainable_layers(self):
for name, param in self.model.named_parameters():
if param.requires_grad: print(name)
def get_ordered_preds(self, ds_type:DatasetType=DatasetType.Valid, with_loss:bool=False, n_batch:Optional[int]=None, pbar:Optional[PBar]=None,
ordered:bool=True) -> List[Tensor]:
"Return predictions and targets on the valid, train, or test set, depending on `ds_type`."
#FIXME: check if this is required. reset is done in fastai. implement if require for BERT also
#learner.model.reset()
self.model.eval()
if ordered: np.random.seed(42)
preds = self.get_preds(ds_type=ds_type, with_loss=with_loss, n_batch=n_batch, pbar=pbar)
if ordered and hasattr(self.dl(ds_type), 'sampler'):
np.random.seed(42)
sampler = [i for i in self.dl(ds_type).sampler]
reverse_sampler = np.argsort(sampler)
preds = [p[reverse_sampler] for p in preds]
return(preds)
def get_predictions(self, ds_type:DatasetType=DatasetType.Valid, with_loss:bool=False, n_batch:Optional[int]=None, pbar:Optional[PBar]=None,
ordered:bool=True):
preds, true_labels = self.get_ordered_preds(ds_type=ds_type, with_loss=with_loss, n_batch=n_batch, pbar=pbar, ordered=ordered)
pred_values = np.argmax(preds, axis=1)
return preds, pred_values, true_labels
def print_metrics(self, preds, pred_values, true_labels):
acc = accuracy(preds, true_labels)
f1s = f1_score(true_labels, pred_values)
print(f"Accuracy={acc}, f1_score={f1s}")
def load_best_model(self, model_name="bestmodel"):
try:
self.load(model_name, purge=False)
print(f"Loading {model_name}")
except:
print(f"Failed to load {model_name}")
def similar(self, text):
cls, _, _ = self.predict(text)
return cls.obj == 1
Databunch
databunch = TextDataBunch.from_df(".", train_df=train,valid_df=val,
tokenizer=fastai_tokenizer.bert_tokenizer(),
vocab=fastai_tokenizer.fastai_bert_vocab(),
include_bos=False,
include_eos=False,
text_cols=text_col,
label_cols=label_col,
bs=config.batch_size,
collate_fn=partial(pad_collate, pad_first=False, pad_idx=0),
)
Model
bert_model = BertForSequenceClassification.from_pretrained(
config.bert_model_name, num_labels=config.num_labels)
learner = BertLearner(databunch, bert_model,
metrics=[accuracy])
learner.callbacks.append(ShowGraph(learner))
learner.fit_one_cycle(config.epochs, max_lr=config.max_lr)
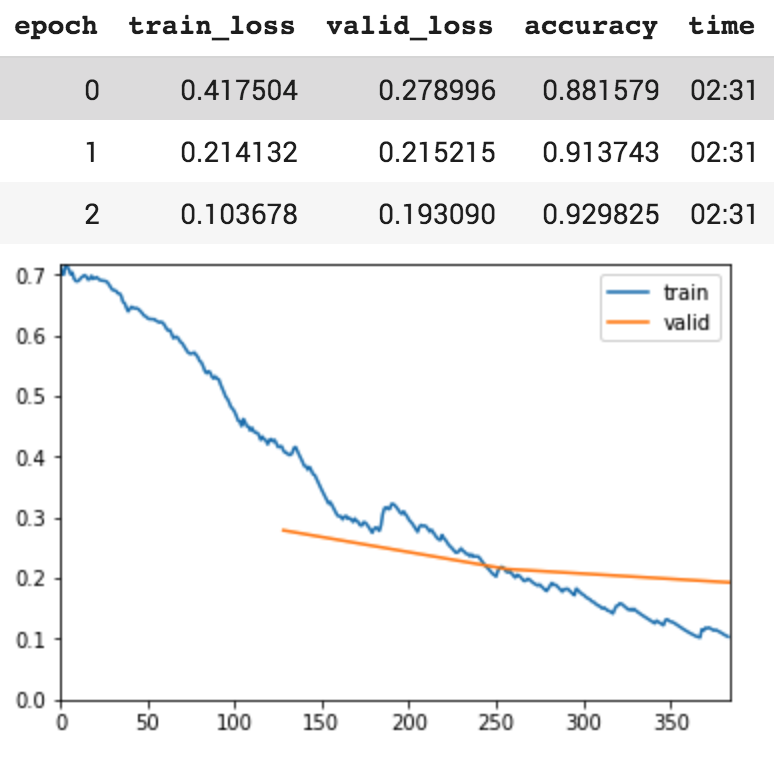
It mostly follows this tutorial.
Model is learning well before layer freezing.