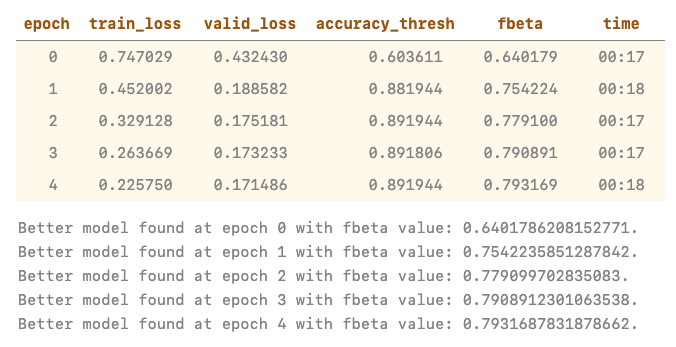
I’ve setup multi-label classification on a private dataset. While the learning rate finder and the metrics show that the model is training well, the confusion matrix tells a different story (as do qualitative checks on model performance).
Dataset Summary
Constructing the DataBunch
I’ve removed the code that constructs the DataFrame with the filenames with classs for brevity.
lls = LabelLists(path = '/',
train = ImageList.from_df(df_train, path='/'),
valid = ImageList.from_df(df_valid, path='/'))
data_lighting = (lls
.label_from_df(label_delim='_')
.transform(tfms=get_transforms(),
size=(224,224),
resize_method=ResizeMethod.SQUISH)
.databunch(bs=64)
.normalize(imagenet_stats))
Train + Val Distribution
data_lighting.c # == 8
len(data_lighting.train_ds) # == 3660
len(data_lighting.valid_ds) # == 900
vc = pd.value_counts(data_lighting.train_ds.y)
pd.DataFrame(vc, columns=['Frequency'])

vc = pd.value_counts(data_lighting.valid_ds.y)
pd.DataFrame(vc, columns=['Frequency'])

Training
Model Setup
acc_02 = partial(accuracy_thresh, thresh=0.2)
f_score = partial(fbeta, thresh=0.2)
learn = cnn_learner(data_lighting, models.mobilenet_v2,
metrics=[acc_02, f_score],
path = 'home/rahul/tmp',
callback_fns=partial(SaveModelCallback, monitor='fbeta'))
LR Find + One Cycle Training
learn.lr_find()
learn.recorder.plot()

learn.fit_one_cycle(5, slice(1e-2))
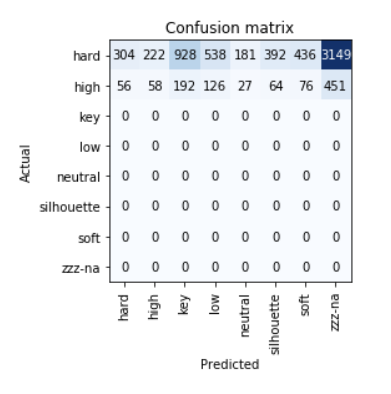
Confusion Matrix
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()
Questions
-
The model is predicting everything as
hardorhighwhile the metrics tell a very different story. Is this because of thethreshvalues? (I think not) -
The number of validation samples is 900 and training samples 3660. As per the confusion matrix, there’s way more samples than both of these combined. What’s going on here?
-
When training using the exact same data as a single-class classification problem, which reduces the no. of labels from 8 to 7, the model trains as expected and the confusion matrix makes sense too
(PS – the label names are different because of how I constructed the dataset, but the dataset is the same)

Thank you!
