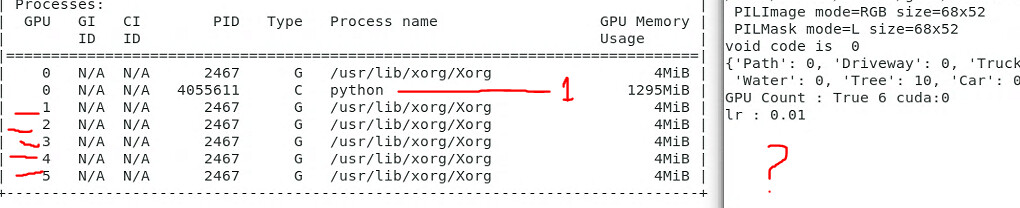
I have been able to use 6 multiple GPU’s for training an image classification model cnn_learner by using the torch DataParallel command:
learn = cnn_learner(training_images, model, metrics=[F1,accuracy]).to_fp16()
learn.model = nn.DataParallel(learn.model)
However, on our segmentation model unet_learner, it does not work. After research I found out it needs the distributed data parallel such as in:
learn = unet_learner(dls, model_type, metrics=[foreground_acc, IoU], self_attention=True, act_cls=Mish, opt_func=opt).to_fp16()
learn.model = nn.parallel.DistributedDataParallel(learn.model)
learn.fit(epochs, lr=lr, cbs=[SaveModelCallback(monitor="foreground_acc", comp=np.greater)])
That has caused errors such
RuntimeError: Default process group has not been initialized, please make sure to call init_process_group.
Then I tried to initialize the distrib:
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group("nccl", rank=0, world_size=6)
learn.model = nn.parallel.DistributedDataParallel(learn.model)
learn.fit(epochs, lr=lr, cbs=[SaveModelCallback(monitor="foreground_acc", comp=np.greater)])
This spawns one GPU, seems to work but it hangs when fit happens.
Also tried removing the callbacks from the fit function, it didn’t work either.
Then I tried a different approach with:
gpu = None
n_gpu = torch.cuda.device_count()
ctx = learn.parallel_ctx if gpu is None and n_gpu else learn.distrib_ctx
with partial(ctx, gpu)():
print(f"Training in {ctx.__name__} context on GPU {gpu if gpu is not None else list(range(n_gpu))}")
learn.fit(epochs, lr=lr, cbs=[SaveModelCallback(monitor="foreground_acc", comp=np.greater)])
Finally multiple GPUs start working as expected!
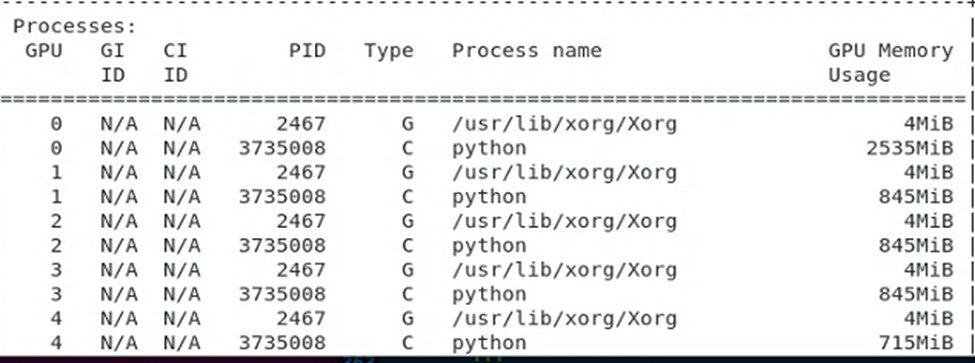
But it throws an error after all 6 GPU’s start working in parallel:
RuntimeError: Expected tensor for argument #1 ‘input’ to have the same device as tensor for argument #2 ‘weight’; but device 1 does not equal 0 (while checking arguments for cudnn_batch_norm)
I’ve looked at other topics but none of them seem to address the case with unet_learner and this specific configuration.
How do I make sure inputs and weights are available on all gpus? or wherever they need to be?
Any help is very very much appreciated!!