Hello Fastai community! ![]() I’m new to neural networks, so please forgive me if my terminology is not on spot.
I’m new to neural networks, so please forgive me if my terminology is not on spot.
So, after completing some image categorization exercises, I wanted to challenge myself with training a multi_category on a big, complex, real dataset. The training seems to go well, with low loss and high accuracy, but when I test it on real images, it results in very low confidence score and weird behavior.
Here’s in detail what I did, and what the problem is.
So first of all, the database has:
- 320,000 images
- 1,800 unique tags
Given the size of the database, I’m using resnet152: I tried training with every resnet, but 152 is giving the lower loss.
First, the database. I import everything:
total_files = 0
for root, dirs, files in os.walk(folder):
total_files += len(files)
total_files
319422
Then it’s time to process the database. First, I load the df and clean it up from the images that failed to download:
df = pd.read_csv(f"{folder}/info.csv")
df['file_exists'] = df['filename'].apply(lambda x: os.path.isfile(os.path.join(folder, x)))
df = df[df['file_exists']].drop(columns=['file_exists'])
df.head()
Each picture has A LOT of tags. So I start by removing all the rare tags that don’t occur at least 500 times in the database, to avoid training for tags that don’t appear enough to train the model reliably:
MIN_OCC = 500
all_tags = [tag for sublist in df['tags'].str.split() for tag in sublist]
tag_counts = Counter(all_tags)
common_tags = {tag for tag, count in tag_counts.items() if count > MIN_OCC}
def filter_tags(tag_string):
tags = tag_string.split()
return ' '.join([tag for tag in tags if tag in common_tags])
df['tags'] = df['tags'].apply(filter_tags)
first_row = df.iloc[0]
first_row['tags']
This still leaves me with a lot of unique tags:
all_tags = [tag for sublist in df['tags'].str.split() for tag in sublist]
unique_tags = set(all_tags)
number_of_unique_tags = len(unique_tags)
print(f"Number of unique tags: {number_of_unique_tags}")
Number of unique tags: 1811
And a lot of tags per picture:
def count_unique_tags(tag_string):
tags = tag_string.split(" ")
unique_tags = set(tags)
return len(unique_tags)
tag_counts_first_10 = df['tags'].head(10).apply(count_unique_tags)
print(tag_counts_first_10)
0 69
1 58
2 84
3 31
4 31
5 50
6 50
7 94
8 38
9 49
So, this is the dataset I’m working with. Now, to load it into the DataBlock:
def get_x(row): return f"workspace/db/{row['filename']}"
def get_y(row): return row['tags'].split(' ')
# Create a MultiLabelBinarizer to get all possible labels
mlb = MultiLabelBinarizer()
all_labels = mlb.fit_transform(df['tags'].apply(lambda x: x.split(' ')))
# Define the stratify function for multi-label
def stratify_func(x):
return mlb.transform([get_y(x)])[0]
seed = random.randint(42, 69420)
dls = DataBlock(
blocks=(ImageBlock, MultiCategoryBlock),
get_x=get_x,
get_y=get_y,
splitter=RandomSplitter(valid_pct=0.02, seed=seed),
item_tfms=[Resize(360, method='squish')],
batch_tfms=aug_transforms(do_flip=False),
).dataloaders(df, bs=32, num_workers=16)
dls.show_batch(max_n=12)
Not sure if aug_transforms is appropriate here, but from all my other tests, it never hurts. So I put it there. I exclude do_flip because it can screw up some of the pics.
learn_rs152 = vision_learner(dls, resnet152, metrics=partial(accuracy_multi, thresh=0.5))
And to find the lear rate:
learn_rs152.lr_find()
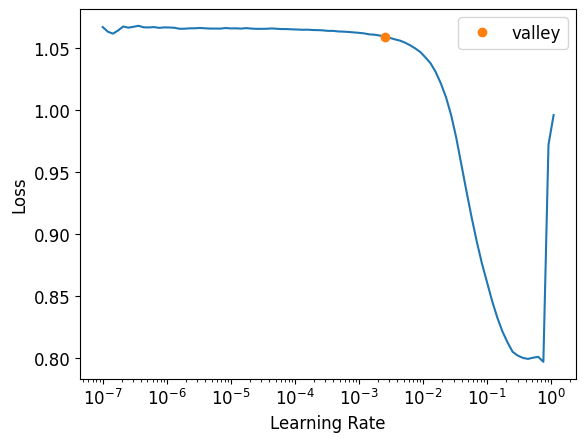
SuggestedLRs(valley=0.002511886414140463)
I go for a conservative lr:
learn_rs152.fine_tune(16, 2e-3)
After a few tries, 16 epochs seems to give the best results (low loss and high accuracy).
Loss and accuracy are encouraging after training:
epoch train_loss valid_loss accuracy_multi time
0 0.079134 0.074353 0.978075 23:39
1 0.074174 0.070600 0.978730 23:40
2 0.071222 0.067656 0.979351 23:41
3 0.070364 0.065794 0.979700 23:41
4 0.068029 0.064353 0.980004 23:42
5 0.066757 0.063149 0.980255 23:41
6 0.065673 0.062209 0.980447 23:39
7 0.064395 0.061489 0.980570 23:42
8 0.062352 0.060821 0.980736 23:42
9 0.062011 0.060221 0.980870 23:42
10 0.060972 0.059858 0.980974 23:42
11 0.059531 0.059520 0.981049 23:42
12 0.058714 0.059326 0.981075 23:43
13 0.057879 0.059260 0.981144 23:46
14 0.057848 0.059215 0.981144 23:42
15 0.057059 0.059159 0.981141 23:43
Even when I increase the threshold to 0.9, accuracy remains high:
learn_rs152.metrics = partial(accuracy_multi, thresh=0.9)
learn_rs152.validate()
(#2) [0.0591593012213707,0.9779587388038635]
Which means, I imagine, that the model is very confident in what it is predicting. Wonderful! Now, it’s time to test the model on the “secret set”, a set I randomly split from the original dataset before training, so it was not in the training set or in the validation set. And this is where the probelms begin…
I load the model:
def get_x(row): return f"workspace/db/{row['filename']}"
def get_y(row): return row['tags'].split(' ')
model_path = '/workspace/model.pkl'
learn = load_learner(model_path)
Then I load the test image:
img_path = '/workspace/yy.jpg'
img = PILImage.create(img_path)
img.resize(size = (512, 512))
I resized it to (512, 512) because in order to save disk space, I resized all the images in the training and validation datasets to 512x512 before fine tuning resnet, but the secret set is not resized.
Then I call the model:
pred, pred_idx, probs = learn.predict(img)
predictions_with_probs = list(zip(pred, pred_idx, probs))
sorted_predictions = sorted(predictions_with_probs, key=lambda x: x[2], reverse=True)
for category, idx, probability in sorted_predictions:
print(f'{category}: {probability.item() * 100:.2f}% | {idx}')
But this is where the problems start, because this is what I get:
tag_1: 17.12% | False
tag_2: 6.98% | False
tag_3: 4.14% | False
tag_4: 3.66% | False
tag_5: 1.60% | False
tag_6: 1.38% | False
tag_7: 1.07% | False
tag_8: 0.96% | False
tag_9: 0.71% | False
tag_10: 0.58% | False
tag_11: 0.44% | False
tag_12: 0.37% | False
tag_13: 0.35% | False
tag_14: 0.33% | False
tag_15: 0.20% | False
tag_16: 0.09% | False
tag_17: 0.04% | False
tag_18: 0.04% | False
tag_19: 0.02% | False
tag_20: 0.02% | False
There are only 20 tags, and with very low confidence. So low in fact, that none of them go above the threshold.
I try with another one, same story:
tag_1: 46.11% | False
tag_2: 10.19% | False
tag_3: 9.96% | False
tag_4: 5.27% | False
tag_5: 4.65% | False
tag_6: 3.31% | False
tag_7: 2.03% | False
tag_8: 1.27% | False
tag_9: 0.86% | False
tag_10: 0.84% | False
tag_11: 0.83% | False
tag_12: 0.71% | False
tag_13: 0.67% | False
tag_14: 0.65% | False
tag_15: 0.58% | False
tag_16: 0.39% | False
tag_17: 0.37% | False
tag_18: 0.22% | False
tag_19: 0.19% | False
tag_20: 0.14% | False
tag_21: 0.10% | False
tag_22: 0.10% | False
tag_23: 0.01% | False
tag_24: 0.00% | False
tag_25: 0.00% | False
Only 25 tags, low confidence. The only one that approaches 50% thresholds, tag_1, was EXTREMELY easy to guess. It was the easiest tag of the easiest and clearest image I could find in the secret set.
Third image, same story:
tag_1: 18.81% | False
tag_2: 8.01% | False
tag_3: 7.54% | False
tag_4: 4.10% | False
tag_5: 2.35% | False
tag_6: 1.03% | False
tag_7: 1.02% | False
tag_8: 0.69% | False
tag_9: 0.49% | False
tag_10: 0.45% | False
tag_11: 0.40% | False
tag_12: 0.38% | False
tag_13: 0.30% | False
tag_14: 0.29% | False
tag_15: 0.20% | False
tag_16: 0.19% | False
tag_17: 0.16% | False
tag_18: 0.13% | False
tag_19: 0.11% | False
tag_20: 0.09% | False
tag_21: 0.04% | False
tag_22: 0.00% | False
tag_23: 0.00% | False
More images, more of the same.
After looking at the tags, I can say with confidence that the tags ARE correct. More than that, in fact: they’re perfect.
Even those with less than 1% confidence are spot-on. Zero false positives among all the pictures in the secret set.
These are very uncommon tags, so there’s no way resnet could have known them without fine tuning. So the model has clearly learned from the training set, but the confidence remains low. And because of that (I think), there are a lot of false negative: many of the tags that should have been assigned, are not there. Not even at a 0.01% confidence.
I have absolutely no idea why this is happening. Got any insights? Thanks! ![]()