I’m trying to wrap my head around intuition and math of how does RMSProp and momentum actually work and I’m having one heck of a time
From a high level I understand that we use these two techniques to “speed” up good old gradient descent.
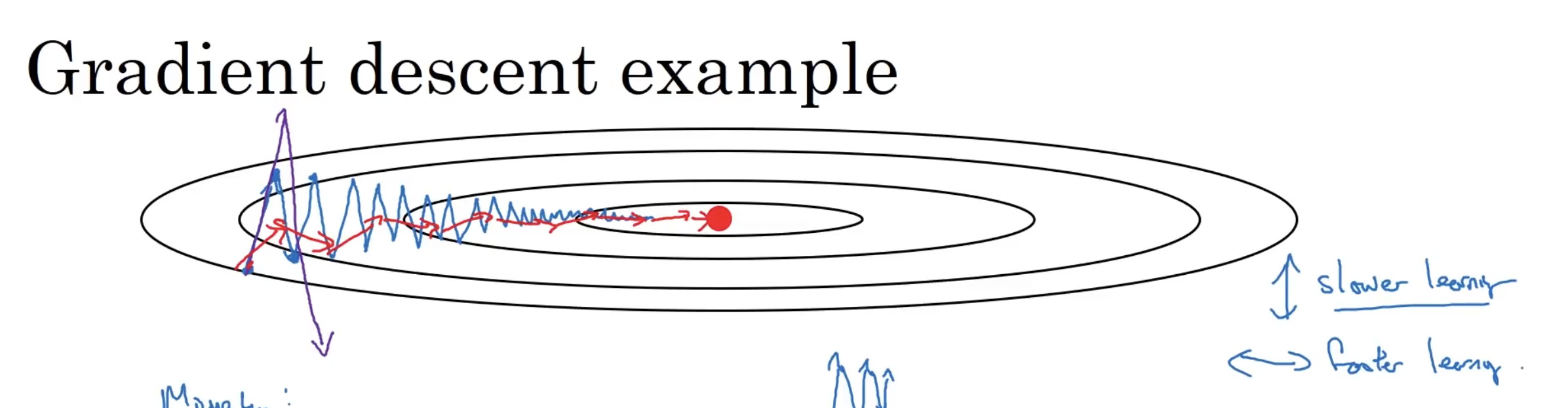
For momentum my understanding is that it basically calculates an exponentially weighted moving average of gradients and uses that to calculate the weight as opposed to just using the gradient. What that does is that “direction” to local optima becomes “steeper” (pic below for illustration)
Does that explanation sound right? I think where I get confused the most is how does exponentially weighted moving average of gradients actually result in having a steeper path towards local optima.
For RMSProp, how does having a exponentially weighted moving average of gradients squared help with moving “faster”/steeper? Is it because it’s squared?
Sorry if these questions don’t make any sense, I’m just trying to understand how this works epoch by epoch and there’s quite a few of moving parts
With SGD, we don’t compute the exact derivative of the loss function. We estimate it on a small batch which results in noisy derivatives and we don’t head towards an optimal direction. So, exponentially weighted averages can provide us a better estimate which is closer to the actual derivative than our noisy calculations. Also as we iterate more and more towards the goal, old terms in this exponentially weighted average become less significant.
RMSProp is just a less aggressive version of Adagrad.
With high gradients, the effective learning rate gets reduced and with low gradients, the effective learning rate gets increased. The squared gradients are just used to update the learning rate as per the current gradient.