Please correct me if I’m wrong, but my understanding (according to this) is that in the fastai tabular API, the parameter bs refers to batch size of the mini batch for the training. The default is set to 64.
My first question is:
Is the number 64 refers to the number of rows, i.e., take 64 samples each time, or does the entire dataset is divided into 64 mini-batches (which means different number of rows for each problem we are trying to solve).
My understanding is that the idea behind mini batches is that instead of taking the whole training set into consideration while updating the weights (which can take a huge amount of space for each update), we update the weights based on mini-batches (small subsets of the training). However, I assume this tactic is adequate for tabular data with millions of rows. I have a case with tabular data containing ~70k rows (which is probably the size of a mini batch in “normal” datasets). My concern is that due to my relatively small data, each mini batch is extremely small, and thus the NN does not give me optimal results, i.e., small mini batches does not represent the entire data and thus each mini batch changes completely the weights instead of slightly improve them.
My second question:
2) Should I change the bs parameter, so it will include much more data in each mini batch
My last question… for now…
3) How mini-batches are chosen? is it randomly? is it according to the sorting order of the dataframe?
I haven’t used the Tabular features of the FastAI library but I went to this page : https://docs.fast.ai/tabular.html
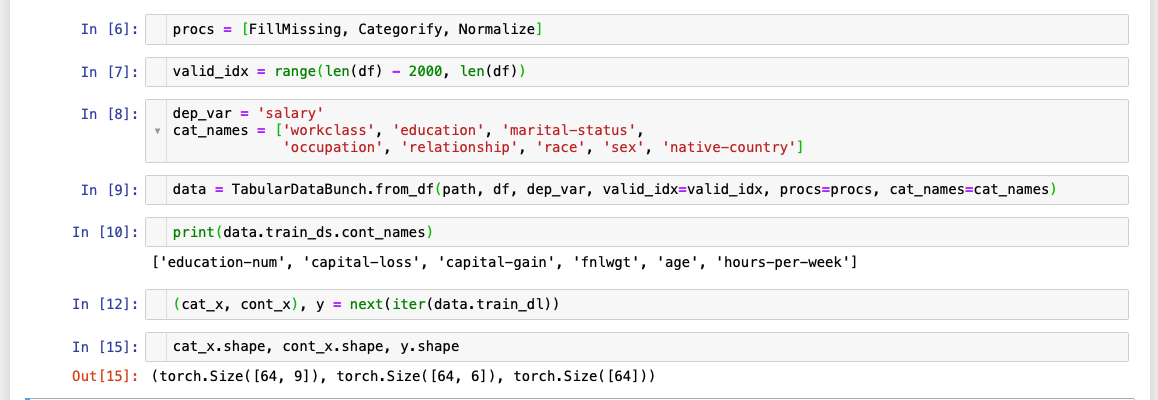
Ran all of the code just as given in the documentation and here’s what I found:
The last line of the screenshot surely means that the bs parameter in this case refers to the number of rows that are being passed in each batch.
For your second question: I think this is subject to experimentation. You can keep experimenting with increasing batch sizes until your model gives you desired results.
For your third question: Yes, the rows passed to your model are chosen and grouped randomly by default.
Hope this helps you. Although I realize that it’s been 3 months since you asked this question so I do not know how helpful this is.
I do a lot of work with tabular data, and my batch size depends on my total number of rows along with how much GPU memory I have. Some cases my batch size will be a thousand or two, or a few hundred depending. It’s all about what can fit efficiently into your GPU
I change it to let it run faster (ie load more onto the GPU at one time). It doesn’t drastically affect my results I’ve seen, and I’d rather have decent results after 5-10 minutes vs 30-45 minutes for almost the same if not the off chance of slightly better.