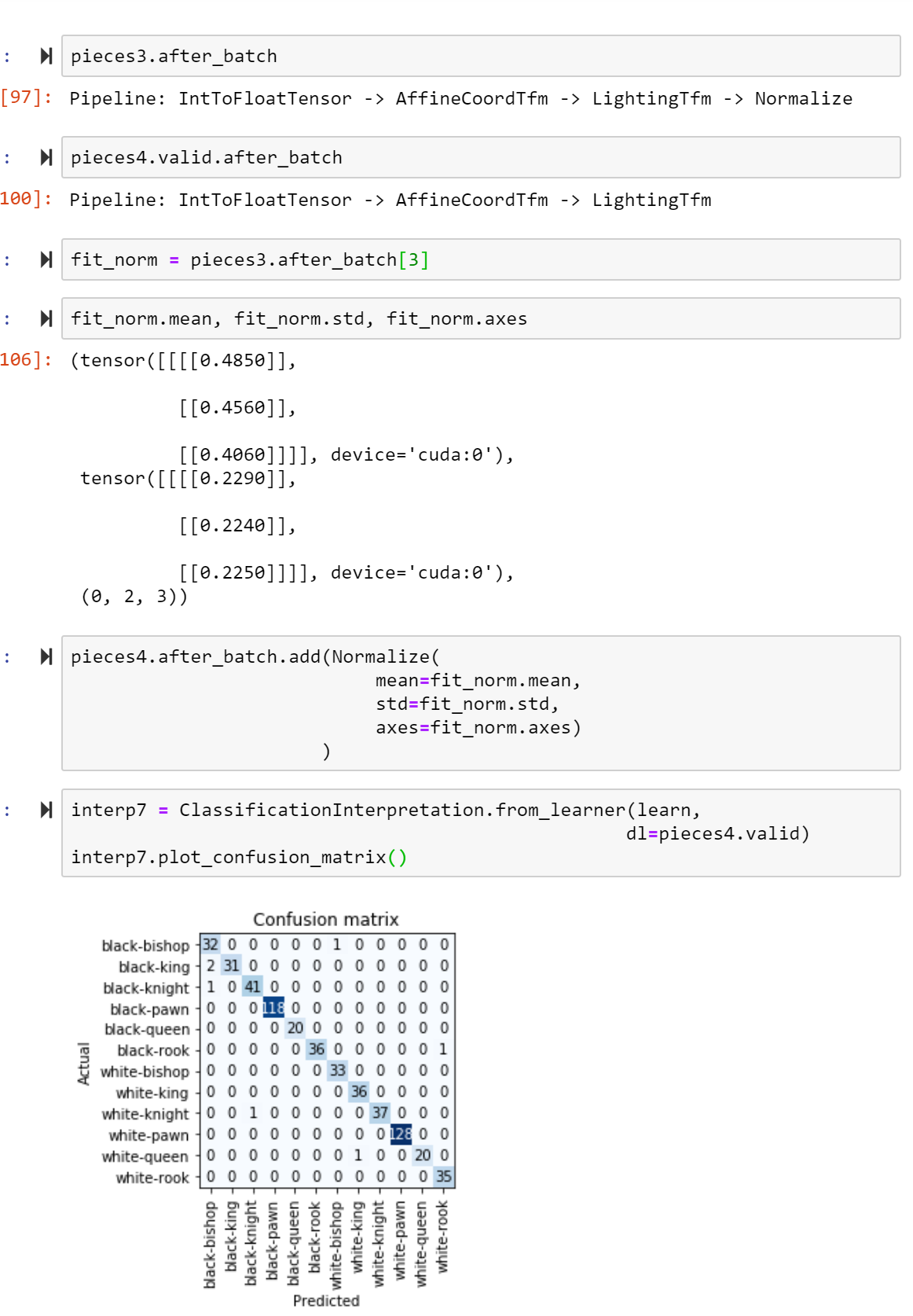
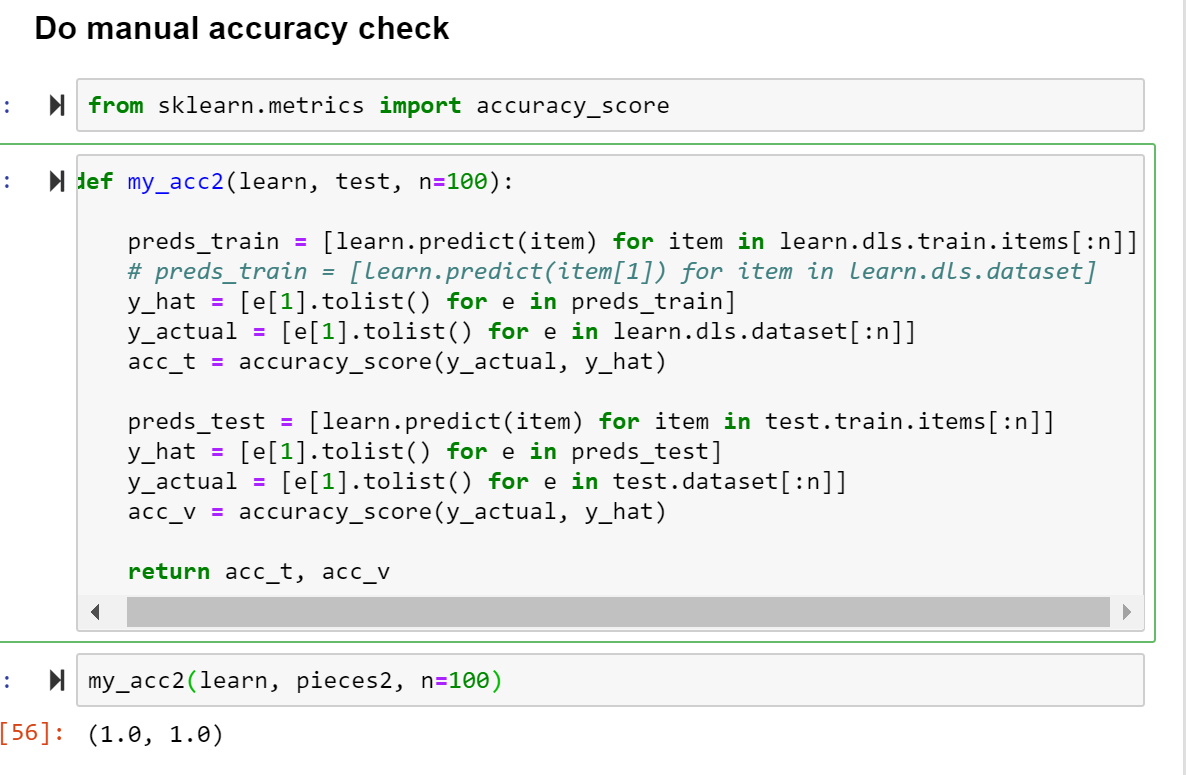
Good news, I’m able to get the same accuracy (~99%) when I manually* calculate for each item. Why this isn’t reflected in ClassificationInterpretation remains to be seen.
*:
The trick is to build the input to ClassificationInterpretation with learn.dls.test_dl(items, with_labels=True) instead of as it’s own dataloader. See below:
According to the documentation, using "validation transforms of dls". But I’m not able to tell where/why or how these transforms are different Full notebook here
Starting to make sense. Do you know which properties of the TfmDl’s would show the diff?
I’ve checked .after_item and .tfms of the respective dls and they look the same. (All attr’s look the same that I’ve checked.)
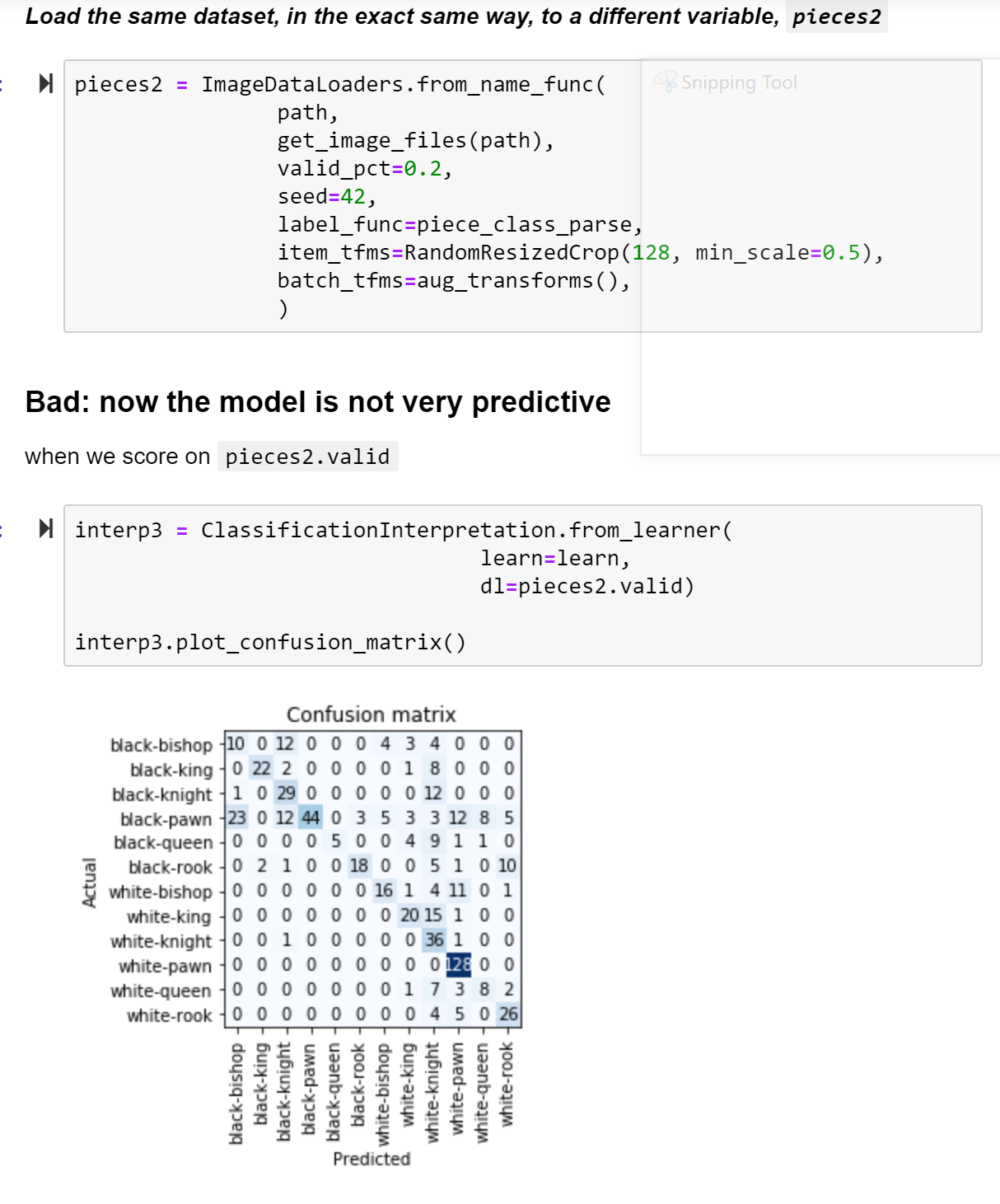
Also I thought I account for the train/valid diff in my experiments by using pieces2.valid as the targets, not pieces2.train
It’s properties of the transforms themselves. Each have a split_idx which if it’s 0 it’ll be on all of them, else it’ll be on the training set only IIRC
Turns out it was lacking Normalize in the .after_batch. From what I understand, this Normalization step also needs* parameters that get fit in train…and I was able to extract some from the learner.
*: not sure if it “needs” them, but it doesn’t work for me without them
If you don’t pass in statistics for Normalize it’ll use the first batch of data you use. Now one more thing is you used cnn_learner. Normalize was being used actually since you forgot it. And it was using imagenet_stats for the actual data statistics. So if you’re wanting to use that you should add a call to Normalize in your batch transforms to either imagenet_stats or your own data (but if you’re using a pre-trained model you should use imagenet_stats), as I think the Normalize that was there was only used during training (But I am not 100% sure here, just going off of you not finding it in after_batch, also the fact it’s in training and not validation is probably a bug)

 Full notebook
Full notebook