Hi everyone,
I just completed the fourth chapter of the book and tried to train my model on the full MNIST dataset. I managed to train my model but am not able to perform prediction on it accurately. Below is my complete code:
# ! [ -e /content ] && pip install -Uqq fastbook
import fastbook
fastbook.setup_book()
from fastai.vision.all import *
from fastbook import *
path = untar_data(URLs.MNIST)
train = path/'training'
test = path/'testing'
train_x_unedited=torch.cat([torch.stack([tensor(Image.open(o)).float()/255 for o in p.ls()]) for p in train.ls()])
train_x = train_x_unedited.view(-1, 28*28)
train_y= torch.cat((
tensor([0]*len(train.ls()[0].ls())),
tensor([1]*len(train.ls()[1].ls())),
tensor([2]*len(train.ls()[2].ls())),
tensor([3]*len(train.ls()[3].ls())),
tensor([4]*len(train.ls()[4].ls())),
tensor([5]*len(train.ls()[5].ls())),
tensor([6]*len(train.ls()[6].ls())),
tensor([7]*len(train.ls()[7].ls())),
tensor([8]*len(train.ls()[8].ls())),
tensor([9]*len(train.ls()[9].ls()))))
test_x_unedited = torch.cat([torch.stack([tensor(Image.open(o)).float()/255 for o in p.ls()]) for p in test.ls()])
test_x = test_x_unedited.view(-1, 28*28)
test_y= torch.cat((
tensor([0]*len(test.ls()[0].ls())),
tensor([1]*len(test.ls()[1].ls())),
tensor([2]*len(test.ls()[2].ls())),
tensor([3]*len(test.ls()[3].ls())),
tensor([4]*len(test.ls()[4].ls())),
tensor([5]*len(test.ls()[5].ls())),
tensor([6]*len(test.ls()[6].ls())),
tensor([7]*len(test.ls()[7].ls())),
tensor([8]*len(test.ls()[8].ls())),
tensor([9]*len(test.ls()[9].ls()))))
train_dl = DataLoader(list(zip(train_x, train_y)), batch_size=256)
test_dl = DataLoader(list(zip(test_x, test_y)), batch_size=256)
dls = DataLoaders(train_dl, test_dl)
learn = Learner(
dls = dls,
model = nn.Sequential(
nn.Linear(28*28, 30),
nn.ReLU(),
nn.Linear(30,10)
),
loss_func = nn.CrossEntropyLoss(),
metrics = accuracy,
opt_func = SGD
)
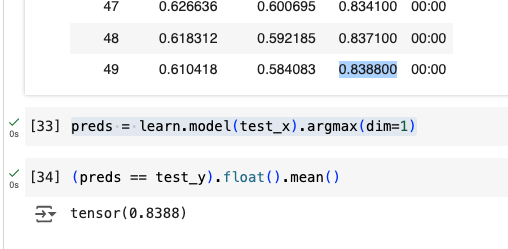
learn.fit(50)
When I perform learn.predict on this using a sample image I get the following error:
new_image_path = Path("/Users/hamza/Downloads")
img = tensor(Image.open(new_image_path/'img.png').resize((28,28)).convert('L')).float().view(-1,28*28)/255
learn.predict(img)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[105], line 1
----> 1 learn.predict(img)
File /opt/miniconda3/envs/ML/lib/python3.10/site-packages/fastai/learner.py:326, in Learner.predict(self, item, rm_type_tfms, with_input)
324 i = getattr(self.dls, 'n_inp', -1)
325 inp = (inp,) if i==1 else tuplify(inp)
--> 326 dec = self.dls.decode_batch(inp + tuplify(dec_preds))[0]
327 dec_inp,dec_targ = map(detuplify, [dec[:i],dec[i:]])
328 res = dec_targ,dec_preds[0],preds[0]
File /opt/miniconda3/envs/ML/lib/python3.10/site-packages/fastcore/basics.py:535, in GetAttr.__getattr__(self, k)
533 if self._component_attr_filter(k):
534 attr = getattr(self,self._default,None)
--> 535 if attr is not None: return getattr(attr,k)
536 raise AttributeError(k)
File /opt/miniconda3/envs/ML/lib/python3.10/site-packages/fastcore/basics.py:535, in GetAttr.__getattr__(self, k)
533 if self._component_attr_filter(k):
534 attr = getattr(self,self._default,None)
--> 535 if attr is not None: return getattr(attr,k)
536 raise AttributeError(k)
AttributeError: 'list' object has no attribute 'decode_batch'
I did read some suggestions on other posts that said I should run learn.model(img) instead which returns the following tensor:
tensor([[-1.6100, 3.0257, -4.1946, 0.2365, -7.3085, 3.4658, -2.9552, 2.8572, 4.5256, 3.9757]], grad_fn=<AddmmBackward0>)
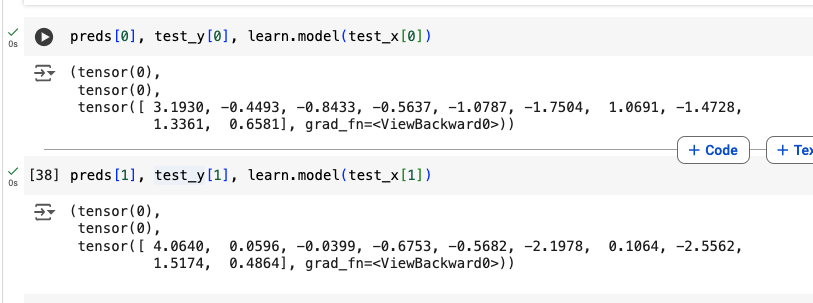
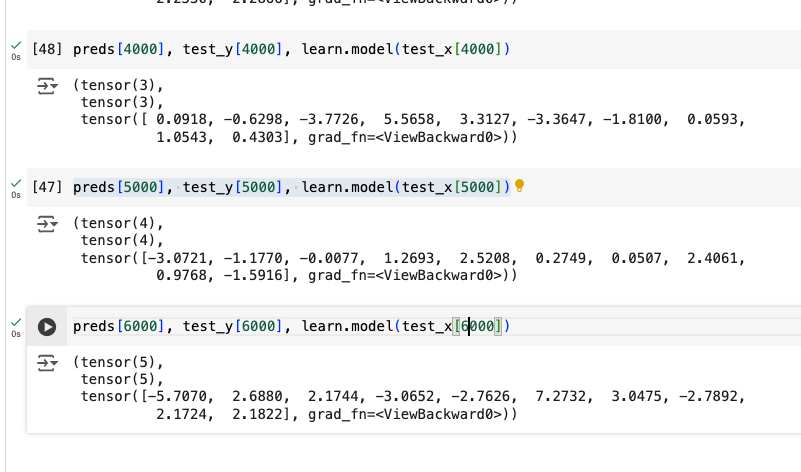
My main area of confusion is that I cannot tell which number in this tensor relates to which number label from the dataset (numbers 0 to 9). I would have assumed that the index of the biggest number in the tensor would be the prediction (in this case 8), but this cannot be as the sample image I am using is 5. I am consistently getting incorrect predictions with different images if I go by this thinking.
Also, if I increase the number of outputs on the last layer of my model (e.g. to 11 outputs), it returns a tensor of length 11 so I’m not even sure if these numbers are related to my labels.
Any help would be greatly appreciated as I am quite lost here!