Hi all,
As I’ve referenced a few times before, I’m excited about the new MixNet architecture that Google Brain released. MixNet is a new state of the art Mobile AI architecture (top 1% ImageNet accuracy).
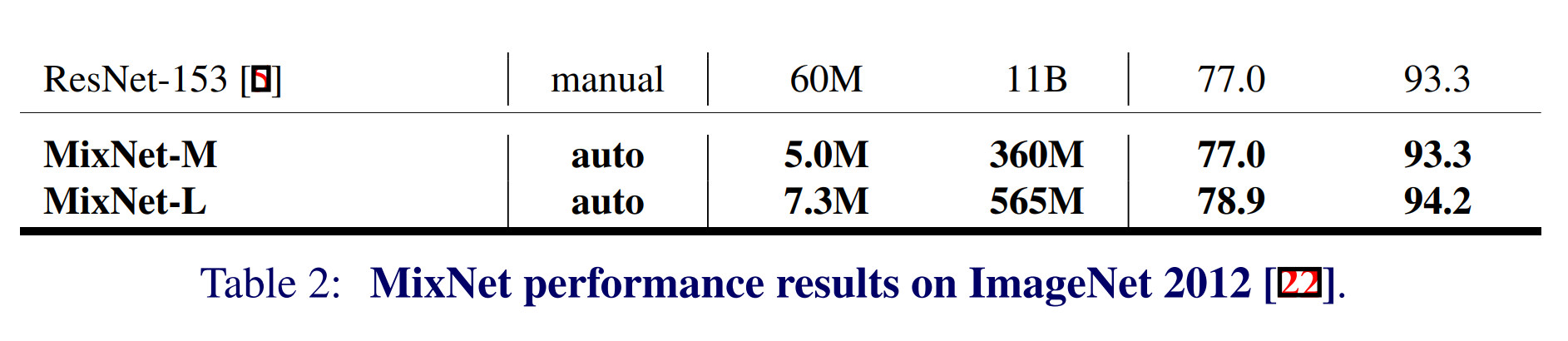
By blending a range of kernels from 3x3 - 9x9 in the same block, MixNet set’s a new accuracy and efficiency record. (MixNet-L outperforms ResNet-153 with 8x fewer params, and MixNet-M matches it exactly but with 12x fewer params and 31x fewer FLOPS.)
I wrote a summary article explaining the MixConv architecture and the MixNet layout. TF and PyTorch code is linked. I’m hoping to make some adjustments to the PyTorch code and leverage it inside of the FastAI framework.
and full paper is here:
I’m hoping to put MixNet to use on a new contract I’m working on and will post the updated code once I’ve tested it out.
Best regards,
Less
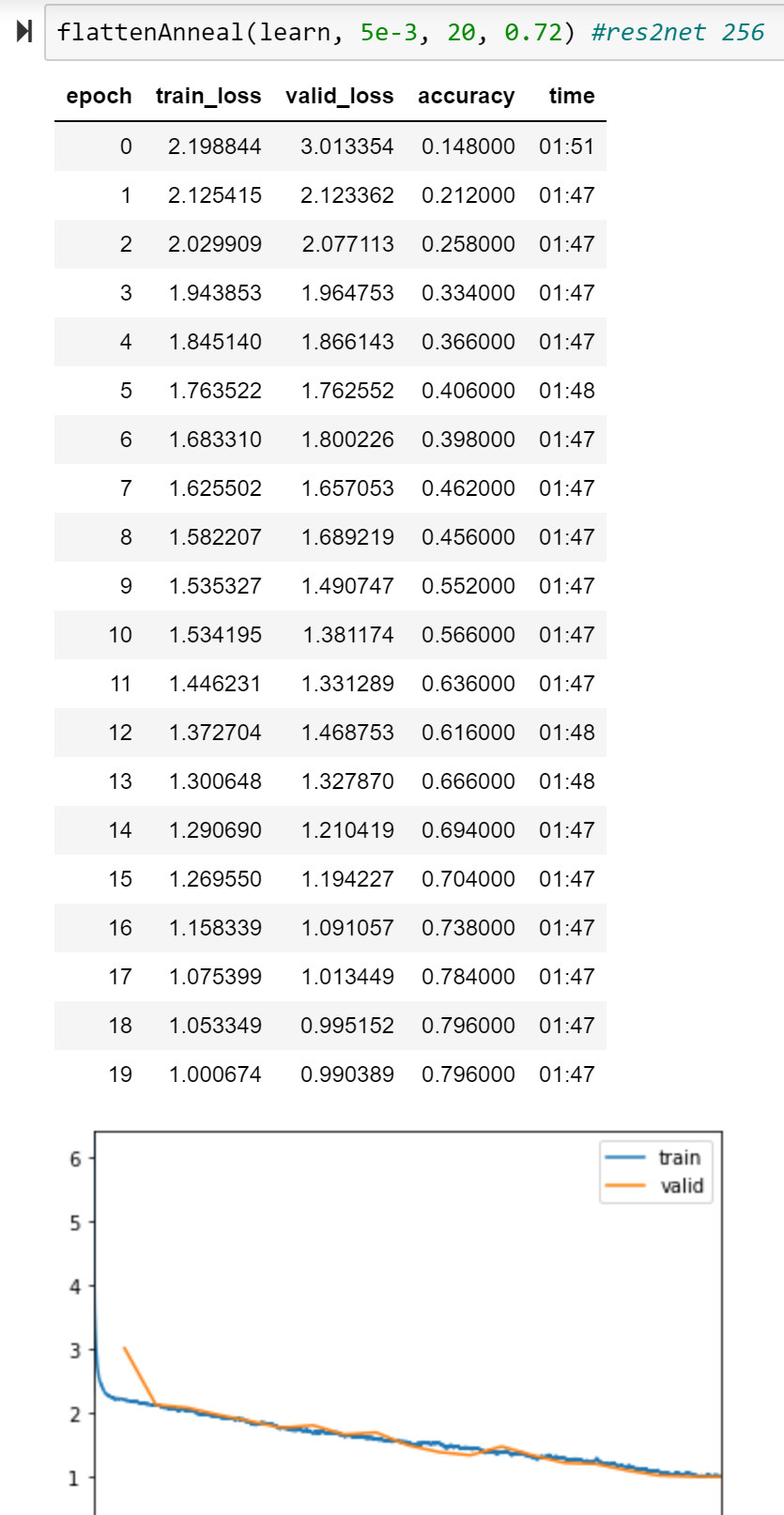
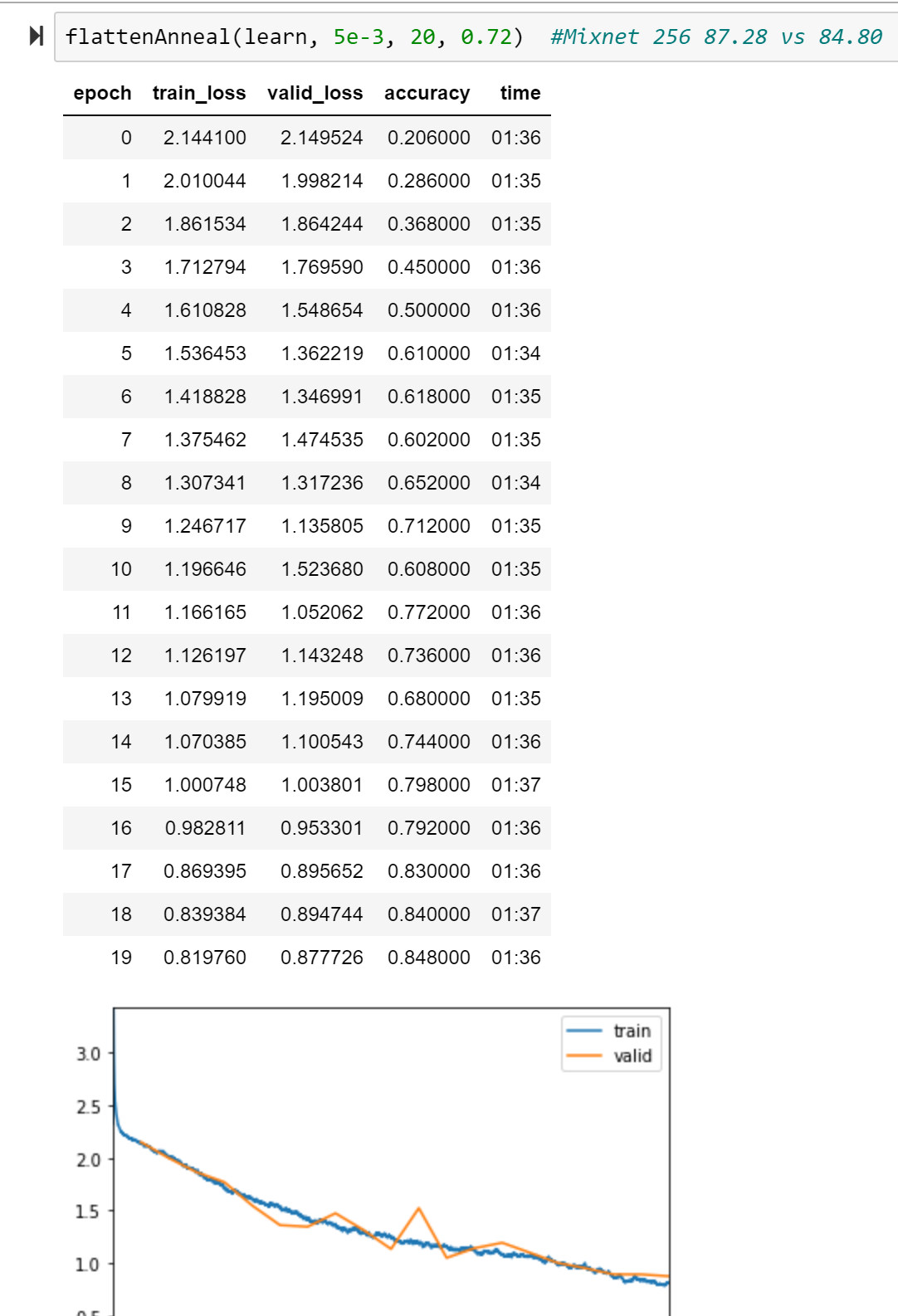
So on a quick run with RangerQH and ImageWoof-256 for 20 epochs, MixNet-L got pretty close to our leaderboard record (note that I did swap in Mish activation as that seemed to help it).
Res2Net-50 plus did not do as well under same ‘default’ settings.
On lower resolution (128) the difference was not as great and Res2Net had a slight edge.
These are only 1 run each and not the desired 5 runs * 20 epochs, but MixNet looks pretty strong considering it was close to the leaderboard (2.4% off) with no tuning at all - just plug in RangerQH with defaults and go.
More testing is needed, and some learning rate calibration, etc. but at least can say MixNet looks pretty good and certainly worth further investigation. It seems to train pretty steadily.
I don’t think that is a coincidence :’). Looking at both papers
MixNet-M
5.0M params
360M FLOPS
top-1 77.0%
EfficientNet-B0
5.3M params
390M FLOPS
top-1: 77.3%
They are extremely close to each other. Comparing MixNet-L vs EfficientNet-B1 (closest one) shows similar results. In both cases, EfficientNet has slightly more parameters but also slightly higher accuracy, both in top-1 and top-5 accuracies.
On some kaggle discussion it was pointed out that the EfficientNet was not so fast in pytorch due to some not optimized operations. Maybe this is fixed now, but if not MixNet could solve this problem as it relies on multiple standard conv2d (unless there are some drawbacks in terms of running multiple conv2d with less filters vs. all filters in one conv2d).
If somebody has (preliminary) results I would be very interested to hear about them!
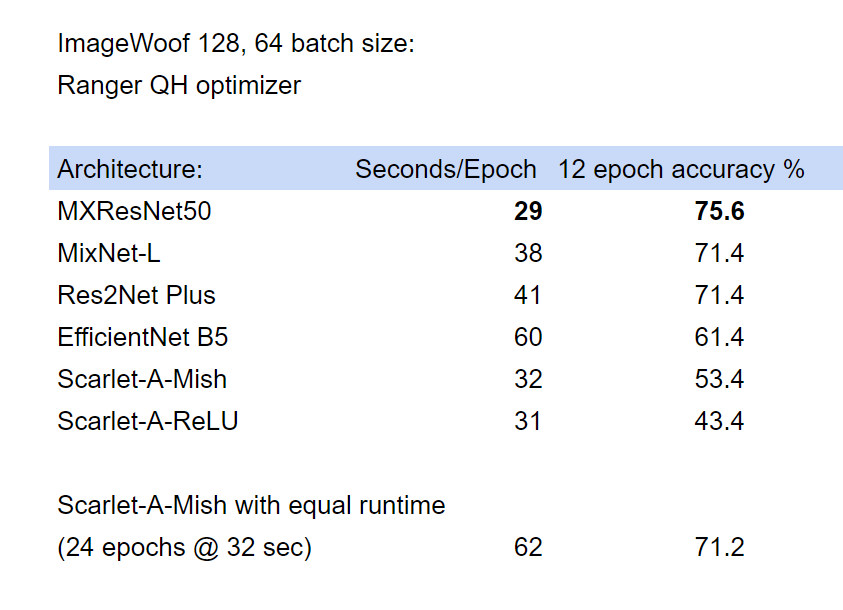
I’m going to try to run MixNet and EfficientNet (B-5) today against ImageWoof and see.
Offhand I felt MixNet ran faster, but let me prove that with a direct test
Note that swapping in Mish activation made a big improvement for Scarlet. Scarlet-A is certainly the smallest model of them all…meaning it’s not a fair comparison with 5x smaller model, but assuming a GPU card on a server and not mobile is what is being tested here.
To put Scarlet on a bit more equal footing, I ran it for 24 epochs to match the equivalent run time EfficientNet B5 was run under, at which point Scarlet beats EfficientNet for 12 minutes of training (71.2 vs 61.4).
Hi @MicPie -
The MXResNet is the FastAI2 XResNet, but with Mish Activation and Seb’s self attention layer plus a change to the initial receptive fields.
Scarlet is a NAS designed architecture from XiaoMi - they claim it is more efficient than EfficientNet.
I just added in Mish activation instead of their Relu6. Here’s their github and I can post my modified version out as well:
 Should have some updates soon.
Should have some updates soon.