I’m trying to understand the number of weights to be trained in any given layer. The simple way would be to start off with just 1 dense layer and look at how many weights are trained. So I refer to the following code and look at the model summary:
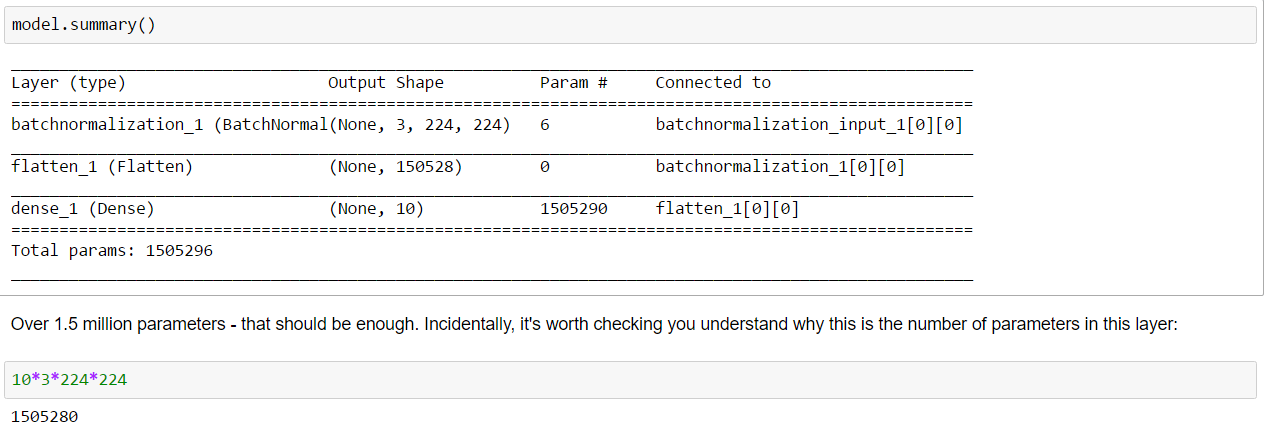
In the batch normalization step, there are 6 parameters being trained. I haven’t read details about batch normalization yet, so maybe I’ll understand this part after reading more about batch norm.
The part that’s throwing me off a little bit is:
We know from math that the number of parameters to be trained should be 103224*224 = 1505280
But looking at the model summary (as seen in the image above), we know that the number of parameters trained are 1505290, which is 10 more than 1505280. Is this because we have 10 output classes (I’m looking at state farm dataset)? How do these output classes play a role in increasing the number of parameters to be trained, apart from the actual multiplication of 103224*224?
