There is something basic that I am clearly not getting when it comes to iterating over Dataloders created on top of Datasets with the mid-level API.
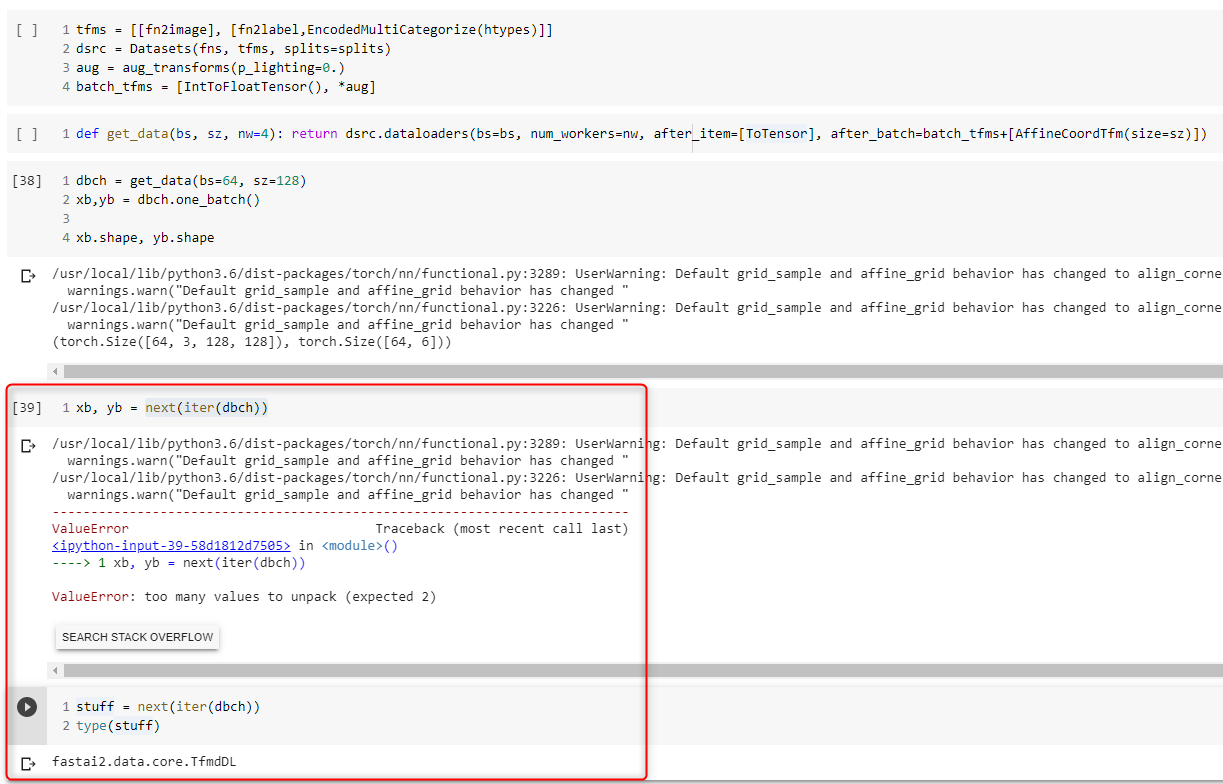
Here my problem (see screenshot too).
xb,yb = dbch.one_batch() works and xb, yb have the expected shapes.
xb, yb = next(iter(dbch)), which presumably is the same thing as calling one_batch, is not working instead.
Actually, I can iterate over dbch, but I get a TfmdDL out of it, not a tuple with a pair of Tensors.
What am I missing, please?
1 Like
I think the concept could be explained better by changing what you call it  So we notice it’s
So we notice it’s .dataloaders. So let’s call it dls (for DataLoaders). Now if it’s dls, this would assume then that there’s multiple of these. So you’d want to specify which DataLoader to pick from. This can be done one of two ways. For the training DataLoader we could do next(iter(dls[0])), as the first DataLoader will be training DataLoader. So we’re iterating over DataLoaders here . The other option would be dls.train and dls.valid (valid would be [1]). The reasoning for this is in v2 we can have any number of DataLoaders present, not just the 2 from train and valid, so we can iterate over all the DataLoaders to get the one we want, as you saw with your second experiment. Does this help?
1 Like
Thanks! This makes perfect sense.
I was sure I was messing up in a very stupid way.
1 Like