Hi all,
Just wanted to have a quick discussion on this topic as I am learning to deal with this in a tabular model. I know the easiest way to deal with class imbalance is in the train set, you oversample the minority in order to help deal with this fact. But I’m weary of this in such a task as my largest class has 290,000 items and my lowest class has 40,000 items. That would mean each sample is copied 7 times! Would it not be better to instead take the mean over all the classes, then over or undersample randomly to fill the gap? So now, the mean is 165,000 items, and instead each item is only copied 4 times. Is there caveat to doing this besides losing some data from the undersampled set? Are there better ways?
Another thought I had is we have AUROC to help with this a bit, but what if we had a different loss function where instead on beginning of training, we store the relative imbalances in relation to the highest abundance. Then when we calculate or losses, we multiply them based off of 1+(1-relative percentage), so now the losses from all classes but the highest class are impacted more.
Thank you for your input!
Zach
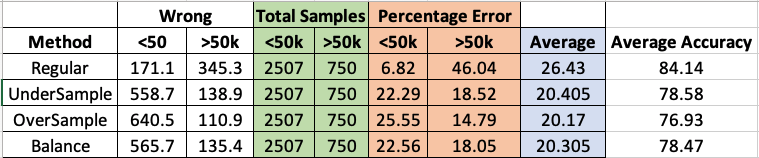
Edit: When I have time, I will run a test on how each of the three sampling techniques do on the ADULTs dataset as a comparison of sorts.