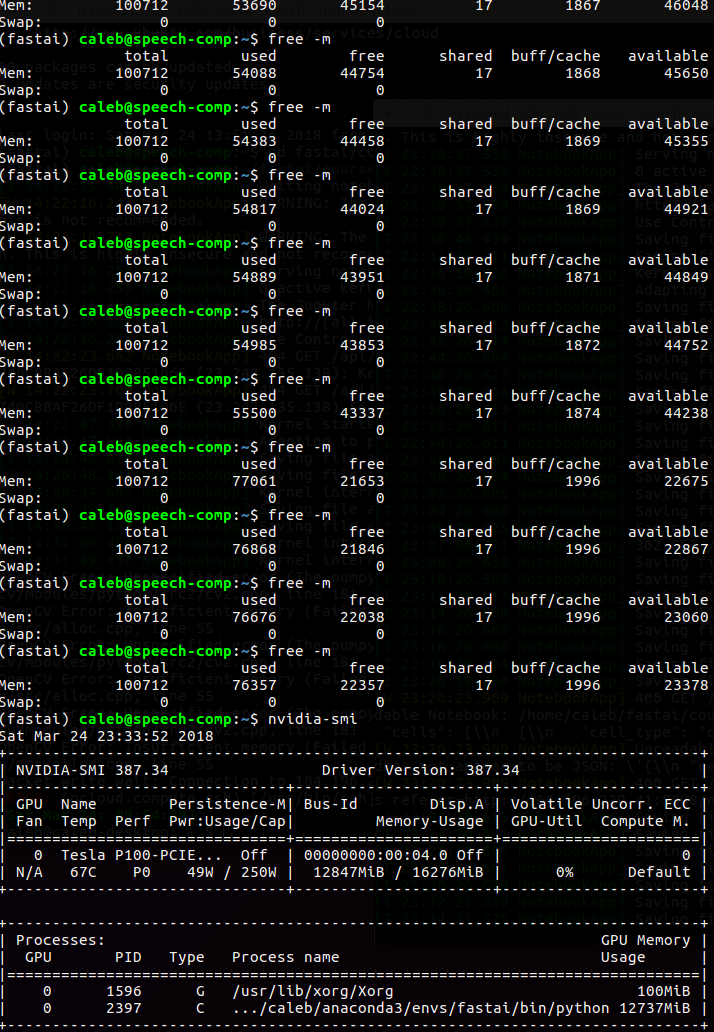
I’ve been working on the carvana notebook, changing out resnet34 for vgg16 and haven’t been able able to train a model with 1024 images. My notebook kernel died and I got out of memory error messages in syslog with a 30GB paperspace machine, so tried a 100GB gcp instance and still no luck. While I was training, I opened up a new shell to the server and ran free -m periodically to check the available memory and found that the available memory continuously decreases.
I’ve tried batch size of 1 and 1 worker on the dataloader. The GPU memory doesn’t seem to be an issue. That stays constant when I check with nvidia-smi.
With resnet34 It actually capped out at about 70GB of memory usage about half way through 510 mini batches of 8 images using 2 workers and then memory usage goes down to under 20GB by the end.
vgg16 is actually making it through a complete epoch with the same batch size and workers and exhibiting the same pattern of memory usage.
This previous forum post identifies this issue as ThreadPoolExecutor greedily pulling batches for each iteration of self.sampler into memory in Python 3.6 vs. pulling them in lazily in Python 3.5.
There are two workarounds:
Set num_workers to 0, which then runs batches in a single thread. This resulted in the consumption of a max of 3GB of memory in the scenario above.
Use the dataloader iterator from Pytorch as described here.
I’m continuing to research ways to make a permanent fix. Any ideas on how to do that or things to look into would be much appreciated.
That’s an interesting point. I’ll see what I can find out about this. Have you tried switching the ThreadPoolExecutor with a ProcessPoolExecutor in the fastai source? (I don’t know if that behaves differently.)
I hacked around this problem by handling the batches a chunk at a time. Fixed for me - let me know if anyone sees any issues. I haven’t tested it carefully for edge cases (e.g. less rows that num_workers*10) so there may be odd bugs still…
There is a NEW TOOL called cstl ( GitHub - fuzihaofzh/cstl: The C++ Standard Template Library (STL) for Python. ) that can solve this problem. It wraps C++ STL containers to solve this issue. It supports multiple types including nested map, list, and set which the numpy and pytorch do not support.
Here is a simple example showing how it solves the problem:
from torch.utils.data import Dataset, DataLoader
import numpy as np
import torch
import copy
import sys
import cstl
from tqdm.auto import tqdm
class DataIter(Dataset):
def __init__(self):
cnt = 24000000
self.cnt = cnt
#self.data = np.array([x for x in range(cnt)]) # Good
#self.data = [x for x in range(cnt)] #Leaky
#self.data = cstl.MapIntInt({i : i for i in range(24000000)})# Good
self.data = cstl.VecInt(range(24000000)) # Good
def __len__(self):
return self.cnt
def __getitem__(self, idx):
data = self.data[idx]
data = np.array([int(data)], dtype=np.int64)
return torch.tensor(data)
train_data = DataIter()
train_loader = DataLoader(train_data, batch_size=300,
shuffle=True,
drop_last=True,
pin_memory=False,
num_workers=18)
for i, item in tqdm(enumerate(train_loader)):
torch.cuda.empty_cache()
if i % 1000 == 0:
print(i)