If one of you wants to file a PR with any changes we need to make, it would be most welcome - happy to merge multiple PRs if things aren’t quite finished yet.
1 Like
One bit of important information that I need to check out that he did was “To help a little, we are going to concatenate a left-right flipped version onto to the validation set to get an effective 1000 examples” (which aligns to how you wanted to add more samples to the validation set)
(on top of the custom DALI dataloaders)
I’ll check on that post the weekend though. Need to step back for a few days and focus on some other things 
I’ve added a new notebook with a different train/val split for Imagenette (2500 validation examples instead of 500) and a smoothed accuracy metric to try to reduce variance of validation accuracy. This should make it easier to compare training setups/hyperparams. As a bonus it also has a slightly faster MishJit than the one in the current fastai2 codebase…
2 Likes
Nice! Want to submit a PR if your faster version of MishJit is tested? (if you haven’t already)
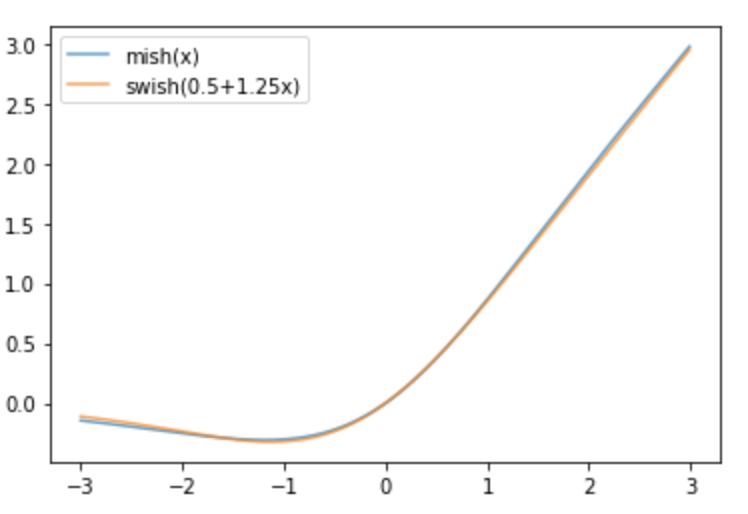
Only concern would be numerical stability, but I’m not sure it’s worth it. I think scaled and shifted Swish is likely to work just as well (and be slightly faster.) I’ll try to run some experiments later in the week.
1 Like
I’ve added a notebook getting training to tie-out between fastai v1 and v2 codebases. The remaining differences were in how weight decay was being applied and a minor difference in cos annealing schedules…
3 Likes
FYI I’ll be releasing a new Imagenette dataset in the next day or two with a 70/30 train/val split, so it’ll be much more reliable for validation. I’ll try to create a new leaderboard as well that leverages all the tricks from @LessW2020 et al (with full credit of course) as well as some new tricks which hopefully will be a good challenge for you all to try and beat…
My plan is to keep the old Imagenette version in the same place but to update fastai.dataset.URLs to point to the new version.
7 Likes
Awesome, looking forward to it!
I’m finally back from my three month cloud architecture excursion and besides learning golang, have some new optimizer and pooling techniques I’d like to bring to bear here
5 Likes
A little off topic relative to the current discussion, but I wanted to share some work a colleague did and present it as a possible template for developing faster optimizers that fuse cuda kernels to minimize the compute. It’s based off of Numba so that becomes a dependency, but the code is very clear to read unlike the binary style of fusing, and the effects are similar. It relies on Numbas JIT which seems to do a better job than torchscript of fusing CUDA kernels.
We benchmarked Adam with the fusedAdam from Apex and saw similar acceleration, and our fused AdamW implementation is ~3x faster than the base pytorch version. We’ve also implemented Radam.
I’d hoped that we would be able to extend these to include lookahead and over9000 in the near term but the expertise to develop these is in high demand and my team is super small right now. If anyone is interested in contributing by following these examples we would welcome contributions via PR. Eventually I hope to have coverage for all of these along with Novograd. @muellerzr pm me if you’re interested in an internship this summer working on this…
Either way I thought that this crowd would find the methodology interesting and potentially useful so I figured I’d share it.
warm regards
Even
8 Likes
This looks great. I wonder if it’s possible to make fastai v2’s generic optimizer use this approach. If so, then we could cover most modern optimizers with just a few small simple functions…
4 Likes
That would probably work even better than what I was imagining since the current optimizer repo is a stand alone package right now. I’m hoping to have some resources to commit to this in the coming year, but we’ve got a lot on our plate and this falls slightly outside our normal focus. I’m going to try to drum up more internal support for it because the improvements in speed are substantial and the optimizer takes 25-30% of the runtime in most profiles I’m looking at so there’s an opportunity here to speed up deep learning training by ~20% across the board if this is done right.
Numba has been really amazing in terms of it’s ability to JIT compile to cuda kernel, and I’m surprised it’s not more commonly used TBH. I’m hoping that torchscript gets better, but in the meantime this could be a good solution for fused kernel optimizations of new developments.
I also think that an organization of the different optimization methods and a systematic way to combine them would be really interesting work. We’ve taken a brief look into it, but having a more theoretically grounded breakdown like it sounds like you’re taking in v2 would be useful. The only issue we ran into when looking into splitting it up that way is in how the decorators work, but I think there’s probably a way to overcome it.
Let me know if there’s any way I can help.
3 Likes
Have to say this is conceptually quite exciting. And Jeremy is spot on that if you just focus on the key differentiators, many current optimizers can be encompassed into the basic v2 base + specific stepper functions. ( I haven’t looked to see if v2 handles passing back the loss function yet as that is required for some self tuning genre optimizers though).
I just finished working in golang (think Python & C++ have a baby that has all their best traits) and since my latest contract just finished I am going through the Numba tutorials now to see if I can get on board with this impressive speedup tech.
If so I’ll try and get a lookahead function implemented with Numba since you already have RAdam (and thus have a Numba Ranger to start with)…which will then need QH and the new global minima sticky function that I’ll post about soon…
Thanks for posting about this, could be a big boost for FastAI2 and deep learning in general.
4 Likes
Hi all,
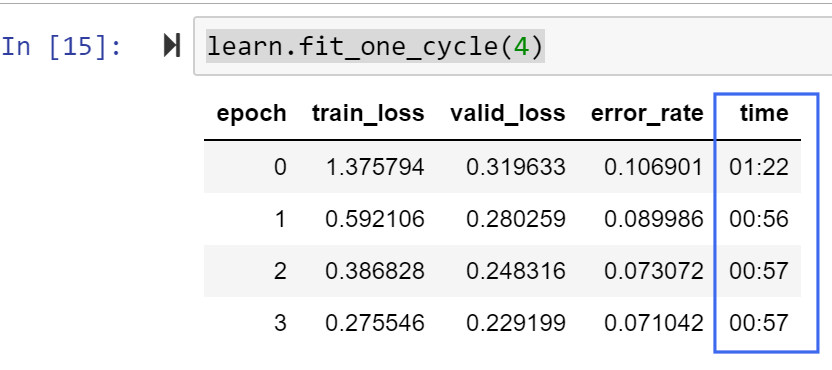
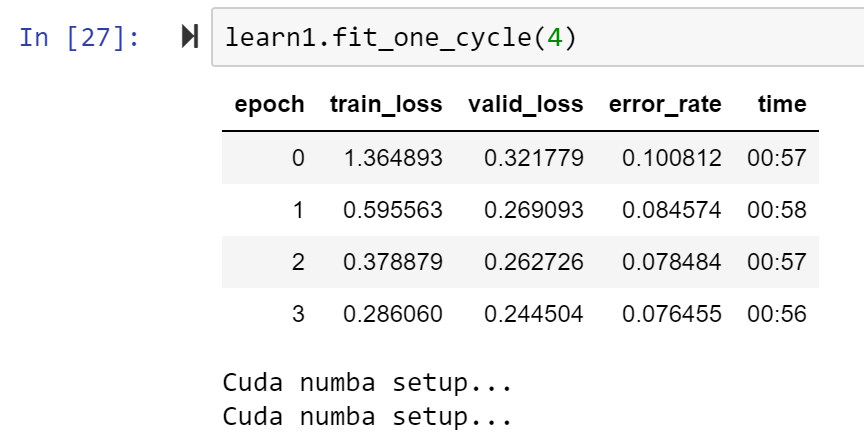
I was able to setup and run the pets db using both regular AdamW and then numba enabled AdamW.
A bit of mixed news though - the numba enabled version was 20%+ faster on the first epoch, but then was the same vs regular Adam for the remaining epochs.
Regular AdamW:
And then Numba AdamW (I put the debug print to make sure it was going into the Numba portion…):
I restarted and ran it again to make sure this results repeated:

Thus, my question is does this mean the GPU is caching better, so the numba advantage basically only last’s one epoch?
I went through the numba tutorials and have a basic grasp of it now but if the speedup only last’s one epoch, then we won’t get the payoff that I was thinking here.
This effect didn’t show in the tutorials (i.e. functions sped up stayed way ahead of regular Python) but not clear why the advantage is disappearing like this?
4 Likes
Hmmm, that’s really interesting. The work we were doing was on tabular models that converged in a single epoch so our profiling was done on that. I’m not sure what’s going on here. Numba should be compiling the optimizer down to fewer cuda kernels (I think it went from ~5 to 1 in the case of AdamW) and I would have thought that would be faster for all epochs not just the first.
It would be helpful to profile what’s going on and to see if we can spot any differences between the first and second epoch. Here’s a helpful link if you’re interested in taking a look:
I’ve also discussed this briefly with the developer Mads and referred him here. He can’t think of a reason why it would be faster on later epoch to run the optimizer off the top of his head but said he’ll give it some thought.
2 Likes
Thanks for the insight and profiling link @Even!
It’s clearly speeding things up a lot on the first epoch, but we’ll have to see why that edge disappears after the first epoch.
I’ll try and read through the profiler docs now and see if I can run something with it this afternoon.
Thanks again for the info!
1 Like
This is now done. In fastai2 URLs.IMAGENETTE et al all point to the new dataset. The new datasets have the same names as the old, except they have a ‘2’ after the ‘imagenette’ or ‘imagewoof’ part of the name. The imagenette github repo points to the new files. The leaderboard hasn’t been updated yet. I’m still trying to create a nice strong benchmark to test you all out with, based heavily off the work done by you all on the forum, and help from @rwightman and @david_page.
4 Likes
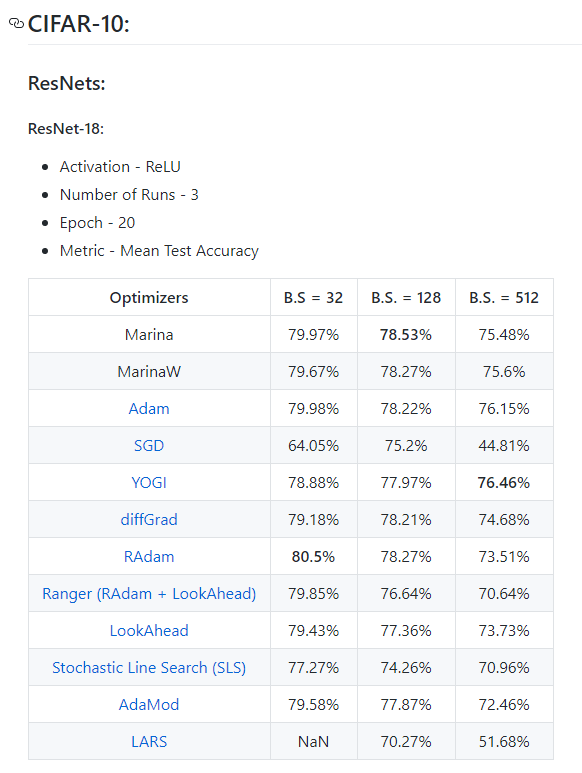
Have been extensively working on optimizers recently and designed two optimizers of my own - Marina and MarinaW. So far, I have seen promising the results with the same but I’m concerned why LARS is giving NaN in 8 runs across 2 batch sizes in 3 models so far. I’m following the official PyTorch ResNet code and the official LARS code. Here are the results. (I’m aware LARS is for Large Scale Training but still it shouldn’t give NaN issues, might be because of bad init I guess?)
3 Likes