Well surprisingly right after my article on RAdam, I found a new paper on LookAhead optimizer in part by Geoffrey Hinton.
RAdam stabilizes training at the start, LookAhead stabilizes training and convergence during the rest of training…so it was immediately clear that putting the two together might build a dream team optimizer.
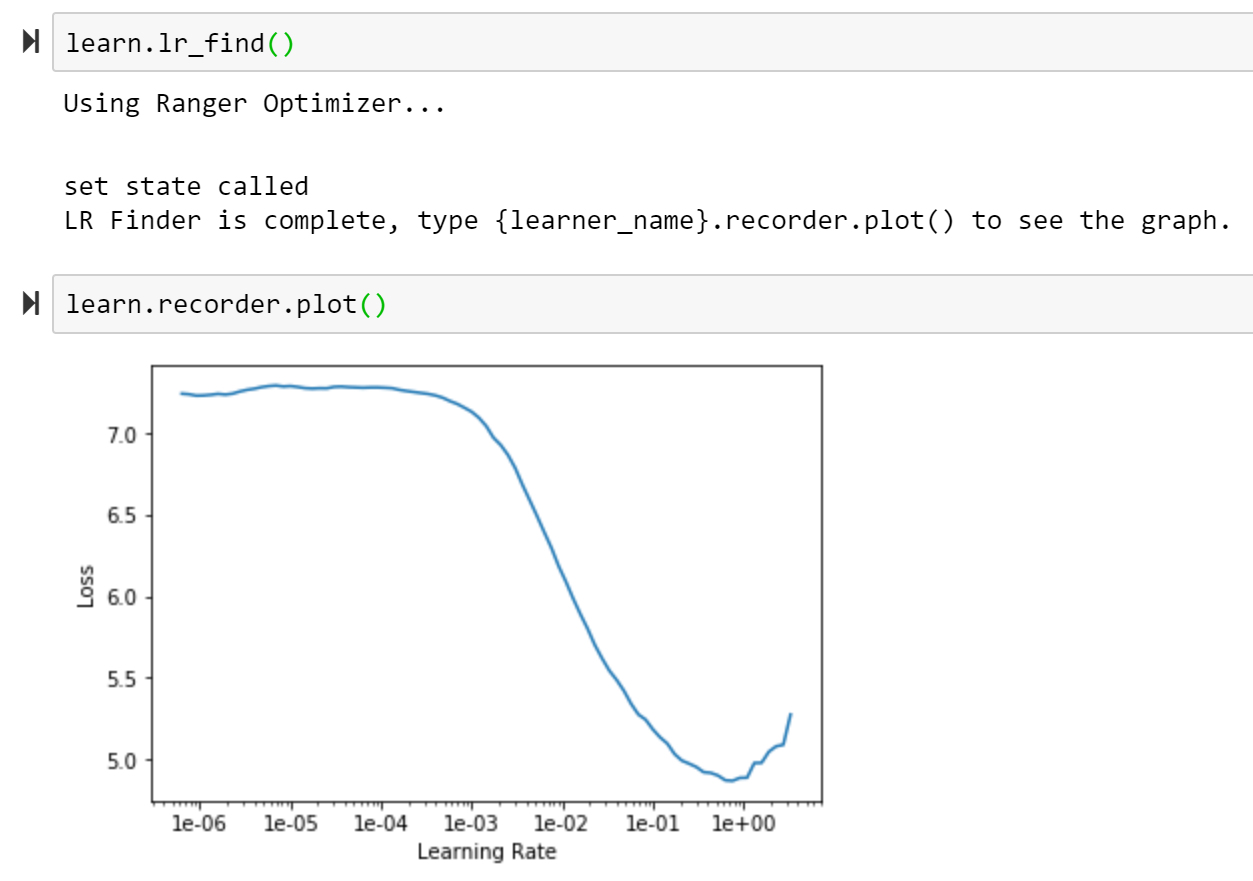
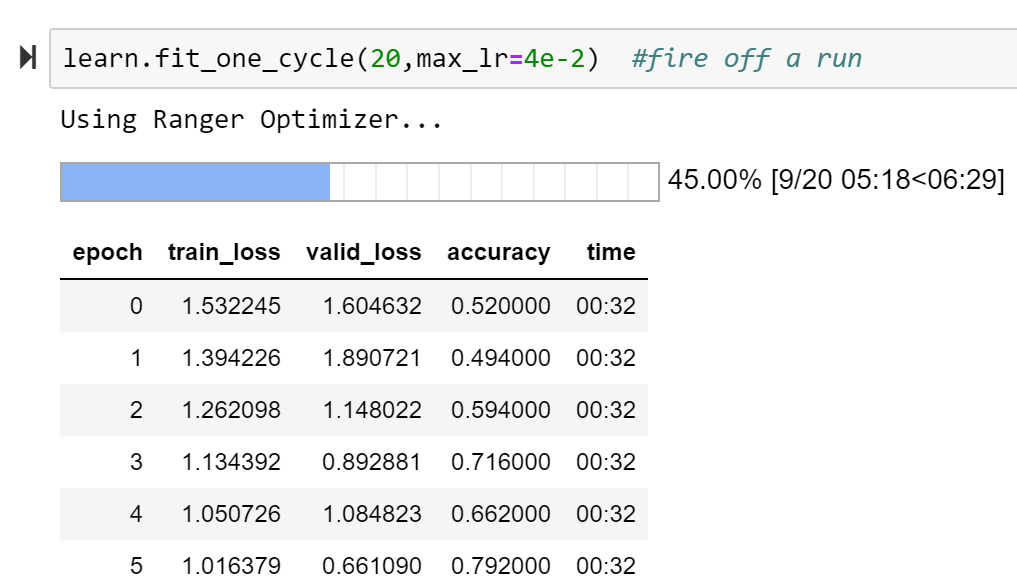
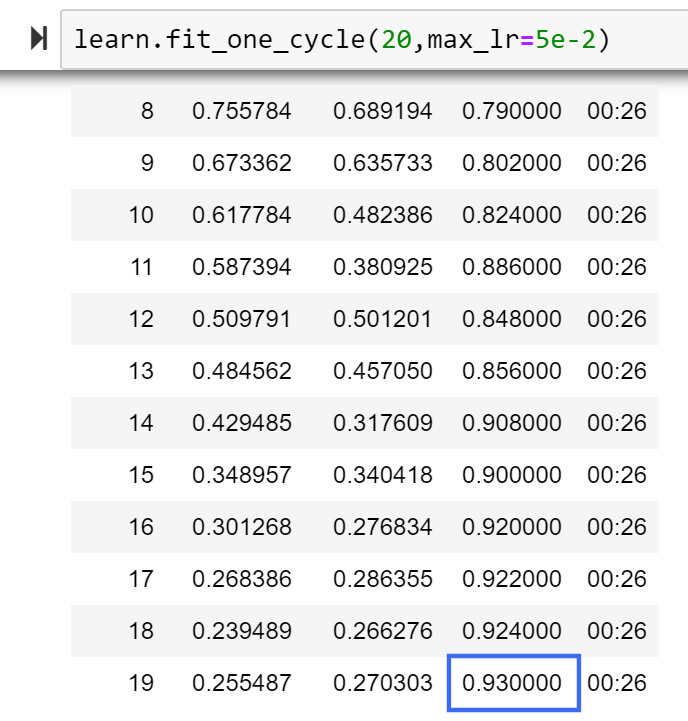
I was not disappointed as the first run with Ranger (integration of both) jumped to 93% on the 20 epoch ImageNette test.
I’ve written yet another optimizer article to get into more details:
And put the Ranger source out for anyone to quickly test. I merged these into one codebase to make it easier to integrate into FastAI and general use, but you can also plug in AdamW, SGD into LookAhead directly.
Ranger code is here:
I’m readying a notebook as well based on previous feedback but I kept getting kicked off over and over today at Salamander…so was not able to finish my testing and notebook.
But here’s the basic process:
Great work @LessW2020! Very very exciting to see all this effort you’ve put into getting this operating and discovering how it all works together even better!!!
Conclusion:
No detected difference in accuracy. Maybe a small signal in valid loss (p=0.25, would still need more data). I’d try with a harder dataset like Imagewoof.
If results are equivalent to Adam, maybe there are advantages to running Ranger:
I’m coming to the same conclusion that we’ll need to move to a harder dataset. I’m wondering if ImageNette is effectively maxed out for XRes50 in general so we’re not able to as readily see improvements in supporting things like activation functions and optimizers.
I’m all for faster testing, esp when I keep getting pre-empted on my servers lol.
That said, we’d need a leaderboard for X18 in order to have a baseline to test with.
Hi @cooli46,
Absolutely none - you can definitely just use the wrapper like you show. I show the same thing in the article.
The reasons I integrated were for modularity (a lot of people on Medium just wanted one line plugins it seemed), and ease of making future code enhancements.
I have plans to test out some auto lr stuff to integrate with these to see if that can further improve and remove the lr selection issues.
Hope that helps!
For the time being, I’m using Lookahead as a wrapper, but if you do, you’ll have to define the state_dict method (basically return the state_dict of base_optimizer). Otherwise, you might have a surprise when you try to save your optimizer’s checkpoint
By the way @LessW2020,
with which type of scheduler have you performed your experiments so far?
I’ve been using a custom version of OneCycleScheduler but I’ve seen posts where the warmup phase should be switched for a flat LR (=max_lr).
Considering the reduced need for warmup with RAdam and Lookahead, we might need to consider new schedulers to make the most out of those two!
Yes, thanks @Seb, I’ve been playing around with his implementation since I found the other post
The best part is that the flat + cosine phases can be obtained from a Onecycle scheduler where div_factor=1 and final_div << 1
Now that we’ve played around with adding a bunch of ideas together in the mish thread, I think it’s a good idea to go back to individual ideas.
I think Ranger needs a second look. Using --sched_type flat_and_anneal --ann_start 0.72 --mom .95,
I get an improvement of 2% (p<0.05, 5 runs) over Adam +OneCycle on 5 epochs, Imagewoof 128px.
(I used the full-sized dataset and the increased channel count on my xresnet, so my baseline is 66%)
On @grankin 's github, adam and ranger did 61.2% and 59.4% but use ann_start=0.50. So we missed some potential on Ranger by annealing too early it seems.
It could also be that it is Lookahead that is bringing all the improvement (or Radam?)
And we’ll need to try with more epochs.
One thing I like with Ranger is that it seems to run epochs as fast as Adam. Worth testing more!
I’m trying to make Lookahead work with Pickle atm.
I’ve added the code def __getstate__(self): return self.__dict__ to Lookahead to override parent method. That should return base_optimizer in dict and then base_optimizer should correctly save it’s state. I can’t figure what is missing here.
So the thing is, that your class is inheriting from torch.optim.optimizer.Optimizer. However, you do inherit the methods, but you’ll want to be careful with what they’re applied to.
In your case, my best guess is:
what you wrote above, does not change (is exactly like) the inherited method of the Optimizer class. What you actually want is to get the state of base_optimizer, otherwise the method is applied to self which is quite different from self.base_optimizer. So overriding the method like below should work: