We have a new fit function, fit_fc. Grab the most recent version via dev install of the library to use  otherwise I believe there was a hack to allow for one cycle to run in a way similar to fit_fc
otherwise I believe there was a hack to allow for one cycle to run in a way similar to fit_fc
2 Likes
That sounds super interesting, @muellerzr! Found it and will try it out for sure - thanks!
I am trying the new version right now, but I think there may be a few bugs. I am trying this with a pretrained ResNet50.
I first got a KeyError: 'k' so I changed group['k'] to self.k. I am unsure if that is the right fix. It was then running for k steps and then said `KeyError: ‘slow_buffer’. I am not sure what’s going on here.
Please let me know if you need more information and if you have a fix.
It seems the error actually occurs when the model is frozen. If the model is unfrozen, it works perfectly fine.
It would be amazing if it worked for frozen models too.
1 Like
Thanks for the feedback - seems the group lr support isn’t fully adapting properly.
Let me work on it and will get it fixed!
1 Like
I just tested it on frozen/unfrozen ResNet34 with no issue (used the dl1 notebook 6 and pets). However, I see you had it on ResNet50 so let me try that and see if that’s the difference (might be as more layers).
I used both a ResNet50 and an EfficientNetB4 and both had the same problem with frozen models. There might have been a bug, but it is unlikely as the code worked without the Ranger optimizer.
Thanks - can you post a code snippet for the ResNet50, of how you are loading up ranger and then the learner and then fitting?
I want to see exactly how you are loading it with the learner.
I did test with Res50 and couldn’t repro.
Also, can you confirm you are using 9.3.19 (latest) for Ranger?
Hopefully that will let me isolate and correct.
@LessW2020 sorry I didn’t respond earlier. I was busy with a competition and completely forgot about your post.
Actually, I wanted to try freezing and unfreezing with Ranger for the competition, but as I mentioned earlier, I was unsuccessful.
Here is the code. Feel free to play around with it to be able to figure out where the bug is. I am probably only going to revisit it in about a week to try it out for a different competition.
1 Like
@LessW2020 Please check this out
1 Like
I read the Lookahead paper and found some difficulties and thought this would be the best place to ask.
-
Problem related to Figure1 of paper. How do I generate such a plot using matplotlib or some other library? They project the weights onto a plane defined by the first, middle and last fast weights. How is this done?
-
Problem related to Proposition1 of paper. I understand that there is some quadratic loss model that can act as a proxy for neural network optimization but how do I use this information to set the value of alpha found in the Proposition1 when I am using CrossEntropy Loss?
Or is there no need to worry about alpha that much? Test some values to see which works best or use default value.

Great stuff, thanks for posting this! If I have time I’ll build in their exponential warmup and put a toggle so people can test both.
Also, their comments at the end about interpolating between Adam/SGD for late stage convergence is basically…RangerQH ![]()
I’ll have to write an article about RangerQH but that’s what I’m using for my production models now (i.e. anytime I’m running over 100+ training iterations).
Thanks again for the link!
Less
1 Like
Hi @kushaj,
Good questions - I have just used their default alpha and seems to work well.
You could certainly experiment with some alpha settings to test, that would be a very interesting avenue to delve into and see if any trends emerge from it.
Best regards,
Less
Note that RAdam and Lookahead have both been added to fastai v2. I didn’t create a Ranger shortcut, but you can use
def opt_func(ps, lr=defaults.lr): return Lookahead(RAdam(ps, lr=lr))
for it (and potentially change any default hyper-param). Lookahead can be wrapped around any fastai optimizer for those wanting to experiment.
7 Likes
@sgugger how do we pass in custom eps into the opt function (as we saw that 0.95 and 0.99 worked the best). I’m wondering if that may be missing as I was trying to recreate the ImageWoof results and I could not. The highest I achieved was 68% with your above code wheras we would consistently get 74-78%. Thoughts? If the eps does not do the trick then I’ll post the problem notebook for others to get ideas
You can pass the value for eps in the call to RAdam but it looms like you want to pass betas form your values. They are called mom and sqr_mom. Tab completion is your friend 
1 Like
Still no luck  I tried recreating all the hyperparameters and steps for it and could only get up to 69.2%. @LessW2020 or @morgan could either of you double check me here? I ran SSA with Mish:
I tried recreating all the hyperparameters and steps for it and could only get up to 69.2%. @LessW2020 or @morgan could either of you double check me here? I ran SSA with Mish:
def opt_func(ps, lr=defaults.lr): return Lookahead(RAdam(ps, wd=1e-2,mom=0.95, eps=1e-6,lr=lr))
learn = Learner(dbunch, xresnet50(sa=True), opt_func=opt_func, loss_func=LabelSmoothingCrossEntropy(),
metrics=accuracy)
learn.fit_flat_cos(5, 4e-3, pct_start=0.72)
The code for SSA is here: https://github.com/sdoria/SimpleSelfAttention/blob/master/xresnet.py
I replaced act_fn with Mish()
Just in case I am trying without bn_wd=False, true_wd=True, and regular wd (1e-2) and seeing if it lines up. Still did better (75.2% on v1)
Also my losses are much higher (2.7 to start and 1.8 at end vs 1.92 and 1.19 for v1).
My notebook is here
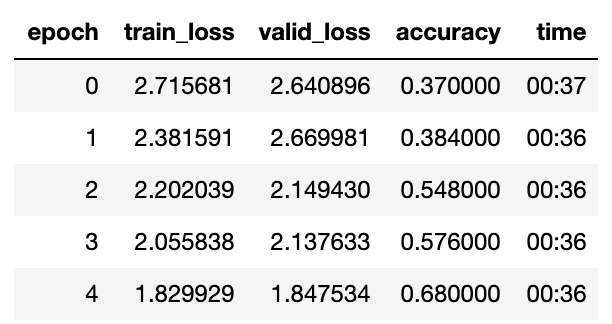
@muellerzr just ran your notebook there and got the same result, 68%
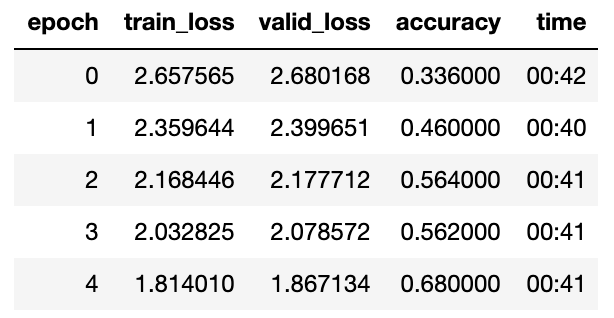
Also, using MishJit code (from @TomB) I got a ~12% speedup. I used the MishJit code in @rwightman’s geffent library
2 Likes
Odd. @morgan how far did you get on your version of Ranger?
Having issues with the my first hacky version on proper models/data. Am going to do a re-write for QHAdam based on the fastai2 RAdam version as above. Maybe have a v0 later today, I think I hav a better idea of what I’m doing now so it looks like a fairly straightfoward port to fastai. Will see how that interacts with the fastai2 Lookahead then
1 Like