What is the purpose of max pooling?
I can see how the mechanics of max pooling reduces the number of activations but what is the purpose of that? Does it improve model accuracy? or is it only to reduce the size of the network?
Thanks
What is the purpose of max pooling?
I can see how the mechanics of max pooling reduces the number of activations but what is the purpose of that? Does it improve model accuracy? or is it only to reduce the size of the network?
Thanks
Pooling, among other things, gives you some shift invariance. Meaning it doesn’t matter if a flower is shifted by a couple of pixels to the left or by a couple of pixels to the right - the kernel that looks for flowers will still be able to pick it up.
I remember Jeremy elaborating on this in future videos. But here is how I understand this.
You reduce the number of activations using a pooling layer to design how your neural network will learn.
When you add a max pool you force the filters of a convolution layer below to search for a feature and report if it is there or not ignoring:
For comparison, an average pooling makes the filters of the layer below to take into consideration how many times a feature was detected which corresponds with how large it was.
Thanks to gradient descent your neural network will learn something most of the times no matter if you selected a max pool or an average pool or if you just use a bunch of dense layers.
The point of using different network architectures is to facilitate this process and let the network ignore some unimportant details and amplify others that you deem essential for the task.
Let’s us an extream example and use a global max pooling that takes a maximum of a whole filter below reducing its size to 1x1.
Assume that you are tasked with building two neural networks that work with fabric:
Assume you come up with the following network architecture:
To find if there is a rip in a piece of fabric (Network A) you would be better off with global max pool. Because it would ignore the surrounding and just react to one single large number that could be representing the rip.
Have a look how the output of such filter detecting rip could look like when a max global pooling is being used as a last layer:
0, 0, 0, 0, 0, 0, 0
0, 0, **2**, 0, 0, 0, 0
0, 0, 0, 0, 0, 0, 0
0, 0, 0, 0, 0, 0, 0
0, 0, 0, 0, 0, 0, 0
0, 0, 0, 0, 0, 0, 0
0, 0, 0, 0, 0, 0, 0
When you take a max pool from such filter you would get 2, something that can be easily interpreted as a whole in afabric, on the other hand an average pool would return 0.04 that could be indistinguishable from another piece of fabric that doesn’t have a rip but for some reason returns a bit of activation on each neuron, like this:
0.04, 0.04, 0.04, 0.04, 0.04, 0.04, 0.04
0.04, 0.04, 0.04, 0.04, 0.04, 0.04, 0.04
0.04, 0.04, 0.04, 0.04, 0.04, 0.04, 0.04
0.04, 0.04, 0.04, 0.04, 0.04, 0.04, 0.04
0.04, 0.04, 0.04, 0.04, 0.04, 0.04, 0.04
0.04, 0.04, 0.04, 0.04, 0.04, 0.04, 0.04
0.04, 0.04, 0.04, 0.04, 0.04, 0.04, 0.04
0.04, 0.04, 0.04, 0.04, 0.04, 0.04, 0.04
This is obviously an imagination how the activation could look like. The point I’m trying to make is that it is hard for me to imagine how an average max pooling would work with such task, it would most likely start to ignore small wholes.
On the other hand, if train Network B that detect wrinkles, I can imagine an average max pool better. For example an underlying filter could have 0 if the patch of the cloth is smooth and 1.0 if there is a wrinkle. In such configuration, a lot of wrinkles would be reported as material that isn’t smooth. While a single fold of fabric would be ignored, even though it could have a similar activation to a wrinkle.
My understanding (based on its simple mechanics) is that MP is a downsampling technique. It filters the less important features, passing the most important to the following conv layer.
You’re right - but I wouldn’t say “features” here, since that might imply choosing filters, whereas pooling chooses parts of the image.
One key concept to google for to understand pooling is “receptive field” - because a key thing pooling does is to increase the receptive field of a filter. Understand this, and you’re well on the way to a deep understanding of CNNs…
Thank you @jeremy. In fact, I never heard of it. Googling it now!
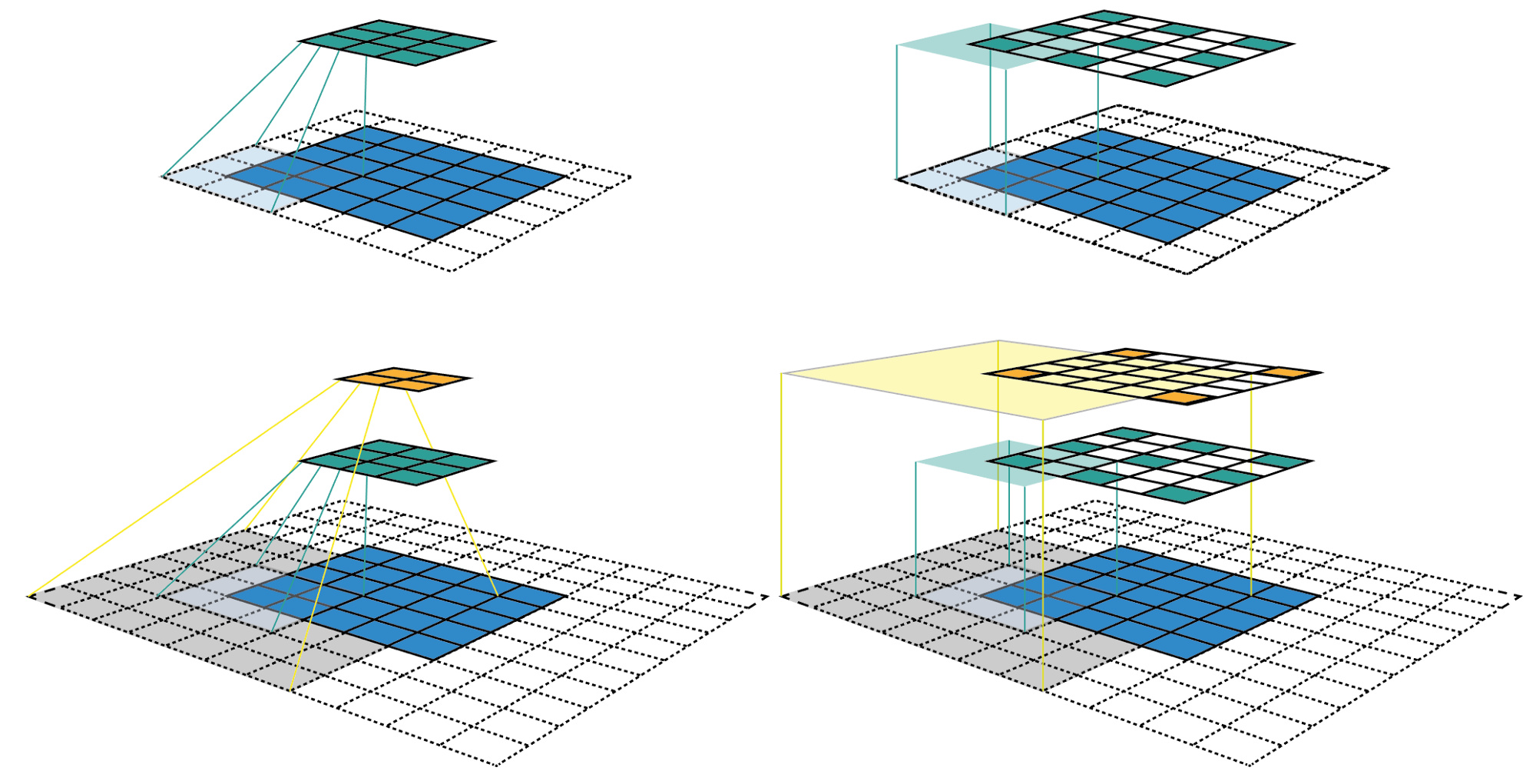
Re. Receptive field,. I’ve googled it and here is what I’ve found.
The receptive field in Convolutional Neural Networks (CNN) is the region of the input space that affects a particular unit of the network.
Here is a more in-depth explanation
The image below shows how the receptive field is extended when two convolutions 3x3 stride 2x2 are overlayed on each other, the second convolution has receptive filed of 7x7 even though it is stil 3x3 convolution. It is caused by the stride that is larger than 1.The pooling layer seems to be a cheap way of extending the receptive field for the layers that come after it.