Hey guys! I’m currently reading Jeremy’s paper “The Matrix Calculus You Need For Deep Learning” and came across a bit I don’t understand.
In section 4.4 (Vector Sum Reduction), they are calculating the derivative of y = sum(f(x)), like so:
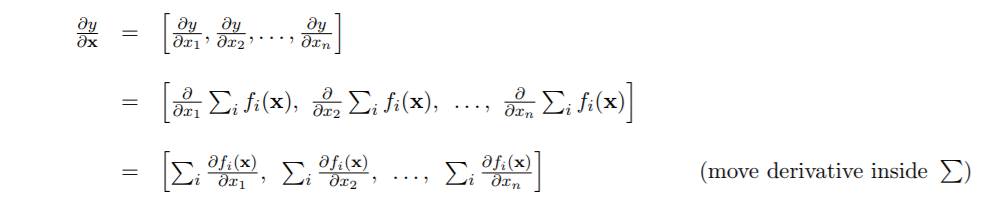
Here, it is noted that “Notice we were careful here to leave the parameter as a vector x
because each function fi could use all values in the vector, not just xi”
What does that mean? I thought it meant that we can’t reduce fi(x) to fi(xi) to xi, but right afterwards, that is precisely what they do:

Does it have something to do with the summation being taken out? Or am I reading this completely wrong?
Here’s the link to his paper:
