I have done lessons 1 through 4 and am now playing around with the Google Landmarks competition which has a very large data set. I have filtered it down to not be as huge, but it is still pretty big.
When trying to to do
it runs for 4 minutes or so and the my machine is totally dead. Connection to it dies, my SSH session is dead. The only thing I can do to recover is to go into the closet (where the computer physically lives) and do a hard-reboot.
I really don’t understand this problem.
To be frank it is throwing me a bit off experimenting because I don’t understand how to avoid this or what to do about it.
Any insights would be valuable.
My setup is:
GTX 1070 Ti 8GB
ASUS Z270F
2x8GB DDR4 / 3200MHz / CL16
Intel Core i5-7600K
Samsung SSD 850 EVO SSD 500GB
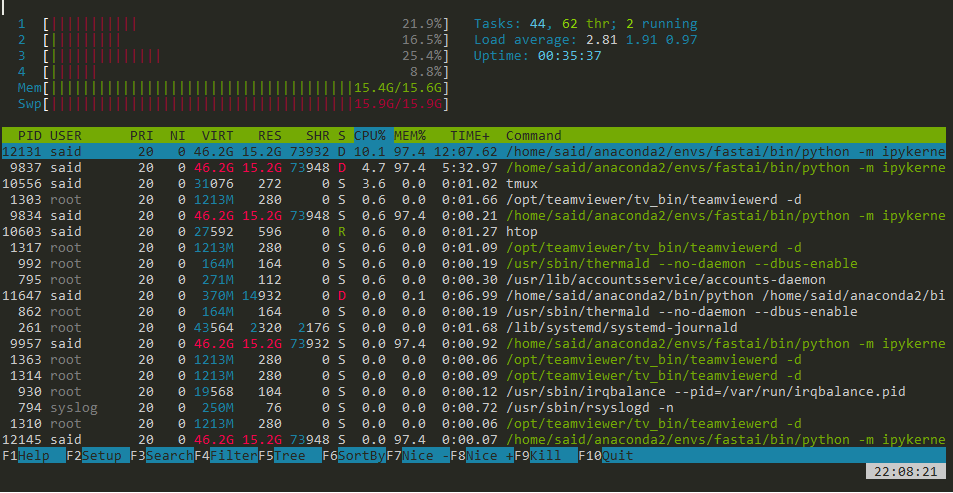
This is the last thing I see from the server before I loose it.
I think your RAM is fully utilized (5th row “Mem 15.4/15.6G”) and in addition the Swap (row below) is also fully utilized (15.9/15.9 GB). Once this happens processes can’t allocate memory any more and may crash and the computer will become unresponsive or may even crash. It also visible, that the python processes use the RAM accordingly. So you will need to check what you load in memory and if that can be reduced. I hope this helps.
Thanks. I think you are right.
Any way to mitigate or avoid it?
Is there anyway that I will know that this is going to happen before I run that particular cell in Jupyter? Would be nice to be able to avoid it.
I did reduce the sizes of the images (to about 500px max) on download. And then I use resize on them further before training. I wanted to use 199px for training but have so far only been able to run anything on images with sizes < 100px.
I have faced this issue on another challenge, and reducing batch size worked for me. But I was working on even smaller machine with much smaller dataset.
I can see that you’ve already downloaded smaller images and kept smaller batch size…
One of the things you can try is to change the arch. to a smaller one, like resnet34 and get some training going on. Once you have a working approach, you would be confident to try bigger arch on the same machine.
The memory blowing up usually happened when I started unfreezing layers, and using differential rates. So make sure you save model weights before that! Also try toggling bn_freeze() (mentioned in videos) if you plan on going with bigger arch, such as anything above resnet50.
Another thing I did was to save models after each every fit I ran, and was monitoring the htop constantly. If I see memory usage going up, I would interrupt and load back the old learner weights, and think of some other way to get around the issue.
If none of these work, you can try compressing jpg images further? Or maybe you can try converting them to grayscale and reduce initial layer depth, as dataset size seems to be the main issue? I am not sure about this part as I haven’t had the opportunity to try it so far.
Hi, how are you getting on with the competition?
my strategy ( with 30gb of ram ) has been to use the resnet34,
download images at 256 resolution
sample 20 images for each class to train on approximately 10% of the data
 Would be nice to be able to avoid it.
Would be nice to be able to avoid it.