I had the same issue in September 2017. I wanted to keep using my mac os workflows to do deep learning, unfortunately, this isn’t easy/possible. Here is why:
you need Nvidia GPU and macs are shipped with AMD which is not yet supported or super slow (OpenCL), for something that has the potential of matching CUDA in the future see ROCm.
Thunderbolt external GPU had driver issues in 2017, this is supposed to be fixed this year.
Even if you manage to get GPU connected you might have issues compiling the deep learning frameworks. For example, Tensorflow does not support GPU since 1.2, PyTorch seems to have better support though.
So I’ve ended up with the following solutions:
make a headless GPU rig - this is what I end up doing
use AWS or services like Floydhub. Floydhub takes no time to setup but is a bit more expensive than AWS
rent a dedicated server with GPU (you can get 1080) on hetzner.com for 99 usd /month + 99 usd setup on
help to get the e-GPU’s working well on mac os.
I’ve gone for option 1. for the following reasons:
I’d rather invest once and then worry that I’m not using the pc enough than consider the cost before each experiment.
Cost of running it on AWS is huge. My PC can run 4 models at once 3 times faster than K80 on AWS. That gives me 600h (25d) after which running models on AWS starts to be more expensive than building your own PC, assuming that the electricity cost is not a huge factor here. Hetzner looks a bit better as the same budget gives you nine months of similar computing power.
I am also facing similar issue with Mac OS 10.13.3 with Nvidia GT 750M . I am using CUDA 9.1 and also verified as per Nvidia instructions(deviceQuery and bandwithTest) and it is working.
Then when I run the first lesson1.ipynb with full sample data (10 dogs/10 cats) it ran fine. But when I tried with full dataset, estimated time given is 1.5 hrs and it is not using my GPU.
Any clue on what I am missing here? Any other suggestions to proceed further?
Hi @Mariam,
For some reason building PyTorch from source is not working for me(It crashes my machine when I try to use for full dataset in fastai lessons, but works for sample). Can you please explain me the steps you took to install through “pip” ?
will install pytorch for you. however, pytorch will not be based on cuda.
I ended up installing ubuntu 16.04 along with mac OSx (dual boot, not through virtualbox). I found the process to be relatively straight forward and now pytorch is using GPU for computations.
I reduced the sz to 100(in lesson1.ipynb), then it worked . But it looks like some out-of-memory issue is happening as per the comments from Pytorch forum https://github.com/pytorch/pytorch/issues/4926
Dual boot on Ubuntu, it never occured to me. I think I am going to explore that option. If you have any link on how to do dual boot installation, please pass it on …
“sz” refers to the image size and you do not want to change it for this model at this time. if you need to change the batch size from its default value of 64, you can pass in the bs= parameter like so…
data = ImageClassifierData.from_paths(PATH, bs=32, tfms=tfms_from_model(arch, sz))
Thanks @Mariam
Atlast, I successfully setup Ubuntu on my Mac and ran the first lesson with few hiccups. These are the steps which I followed, it might help others:
In Ubuntu, search for “Additional Drivers” , then select propritary drivers for GPU and Wireless card.
Then I just used fastai/conda env update to install all the CUDA drivers and other libraries
Though I am still getting “out of memory” issue while running lesson1.ipynb, I am doing the temp fix:
Thanks to jeremy , I now check the following initially to make sure everything is set:
torch.cuda.is_available()
torch.backends.cudnn.enabled
torch.cuda.current_device()
torch.cuda.device(0)
torch.cuda.get_device_name(0) #This should give us GPU name
Then I go upto “learn.save(‘224_lastlayer’)” , then I restart my kernel.
Run torch.cuda.empty_cache() after every training, this helps me alot in giving some free space in GPU (but still ~900MB is used always , don’t know how to clear it)
Then I load the saved model and proceed from there. I noticed if my GPU free memory is atleast 1GB it runs fine (Mine is GT 750M having only 2GB).
I’ve spent quite some time learning about the new hardware it is fascinating and I can share some superb blog posts about that. However, after weeks of exploration, I’ve ended up purchasing and assembling a PC based on pugetsystems - digits with small modifications. I would probably by from pugetsystems if they were selling to EU.
The PC has a motherboard with an older X99 socket. However, this is the only Intel-based option that lets you put 4 GPU with 16x lanes on each.
I have 4 GPU’s, but I can’t put them on the pcpartpicker, as the cards don’t support 4-way SLI.
I would change the chaises to BE QUIET! DARK BASE 900 - it has better quality and looks.
Make sure you buy the MSI Areo OC card or Founders Edition this are the only cards that have Air Intakes on the rear I could find. Initially, I’ve purchased 4x Asus 1080 TI Turbo, because that are blower cards however intake is only on the side so they become super hot when used intensively.
If you are happy with 2 or 3 cards consider going for Ryzen or ThreadRipper. The CPU isn’t that important as GPU. However this is only true if you can write optimised code, and when you are training your models this is usually the least of your concerns then having a fast CPU and good SSD helps.
You may be mistaken or the information is not quite accurate. While the x99 boards may fit 4 gpu cards, they do not all run at 16 lanes each when all are in use. The processor dictates how many lanes will be used. As of now I have yet to see an Intel processor with more than 44 lanes, and my 6850K only has 40 lanes. If you are running 4 cards on X99, you will probably be running them at 8x each for 32 lanes, not the implied 64.
My motherboard has a switch for pci-e lines and as far as I understood each card can use 16x lanes if their are available and other cards aren’t using them.
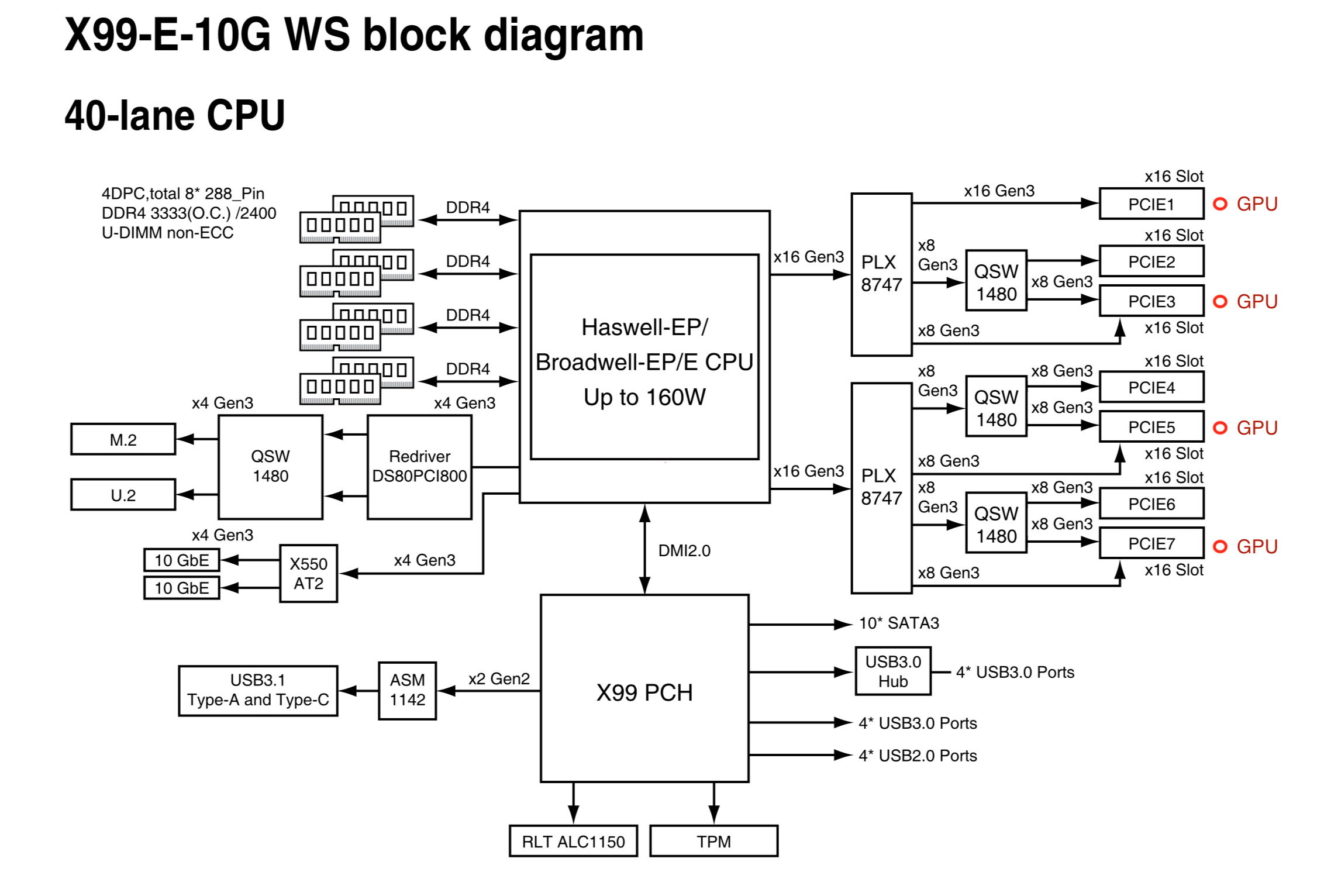
According to asus specs: 7 x PCIe 3.0/2.0 x16 (single x16 or dual x16/x16 or triple x16/x16/x16 or quad x16/x16/x16/x16 or seven x16/x8/x8/x8/x8/x8/x8) (https://www.asus.com/Motherboards/X99-E-10G-WS/specifications/)
Have a look at the block diagram that shows how PLX 8747 and QSW 1480 are used together to multiplex 32 lanes to 64
you still only have 32 lanes to the processor at any given time between those units. even if everything was 4x16, and if they are maxed with info, there will be a waiting game. now this is probably all a moot point as i have yet to see any studies (they could be out there) where the type of DL we do here fills up 16 lanes of info for just one card let alone 4. If we can get to that point of hardware utilization, I would look into the Threadripper as it can support more lanes than the Intel units at this time.
Indeed if all cards are actively using the 32 lanes you are out of luck, fortunately that isn’t happening with deeplearning usually a forward + backward pass on a batch takes much longer than transfer time. You are right that writing algorithms that utilise more than one GPU is hard. But I usually run 4 experiments at once, it greatly speeds up hyper parameter tuning, and I’d like to be able to run them on full speed hence the choice of X99-E-10G.
Moreover I’ve seen a study claims that there is no difference between 16x or 8x for deeplearning: https://www.pugetsystems.com/labs/hpc/PCIe-X16-vs-X8-for-GPUs-when-running-cuDNN-and-Caffe-887/
re. Threadripper I was considering buying it and I think it would work really really well but I wasn’t able to find a motherboard that would give me 4 GPUs and 10g ethernet on the same time, but I bet they will develop such motherboards in the future. If you find such motherboard please share.
The reason for 10g and 4 GPU I intend to stack such computers together in the future once my company takes off.