lesson 1 mentions that Apple does not support Nvidia GPUs and hence it makes no sense to run the course notebooks on a Mac.
However the newer Apple Macs with M1 processors come with up to 32 GPUs.
What would it involve to make use of these GPUs?
As I understand, for fastai to make use of these GPUs, the underlying pytorch framework would need to work with it. Pytorch team seems to be working on it, but I haven’t heard any pytorch builds that can leverage the M1 architecture (yet.).
EDIT: This issue in the pytorch github has some discussion on what’s been going on in this regard:
thanks Mike.
I now subscribed to the GitHub issue
By browsing through the issue comments I get the impression that it would be good to get a basic understanding on how PyTorch utilises GPUs and how CUDA works.
The impression I got from some of the posts in that thread was that Apple’s politics with FB have something to do with it. They facilitated TF Metal development but not so much on the pytorch/torch side and to get similar perormance the pytorch team would have to do things from scratch, which is a daunting task.
Would be nice to have pytorch work on it, but looks like it’s going to be a while before we see it on apple’s M architecture.
This article has some numbers on performance of numpy etc and it seems M1 Max is able to get about 8 Teraflops for 1/8th the power draw of a 3090.
Hi, I wrote an article benchmarking the different Nvidia Gpus and the M1/pro/max/ultra GPUs. They are very very slow compared to CUDA, so don’t expect too much:
Don’t get me wrong, I love the new 14", and I think it’s probably the best PC on the market right now, but no deep learning machine. Anyway, I don’t think a laptop is a good deep learning machine.
The PyTorch backend doesn’t run on Intel Macs (yet), unlike the TensorFlow backend. That means you’ll have to ensure you have an Apple silicon Mac before running notebooks with GPU acceleration. You’ll also need to watch out for operators like SVD and Cholesky decomposition, which MPS does not support. This is different from CUDA, where almost every operator can run on the GPU.
I think more work is needed by both Apple and Pytorch teams on this because the average speedup shown on the blog is only 15-20 times over the CPU. Although they have not shown the actual time taken so overall it “maybe” comparable to a NVIDIA laptop GPU. Maybe the stable version will have a better performance.
*Testing conducted by Apple in April 2022 using production Mac Studio systems with Apple M1 Ultra, 20-core CPU, 64-core GPU 128GB of RAM, and 2TB SSD. Tested with macOS Monterey 12.3, prerelease PyTorch 1.12, ResNet50 (batch size=128), HuggingFace BERT (batch size=64), and VGG16 (batch size=64). Performance tests are conducted using specific computer systems and reflect the approximate performance of Mac Studio.
BTW, just for the heck of it I wanted to compare these numbers with my 1070ti, but copying the train.py file is tricky. There’s no way to copy just the text and if I select and paste it, it introduces some unicode characters in the source file.
After cleaning it up I was able to run it, but the download of the PETS dataset failed on my machine after downloading about 8000 files (out of 25000).
I’ll try to re-run it and see if it restarts from where it left off (at.download() is where it died.)
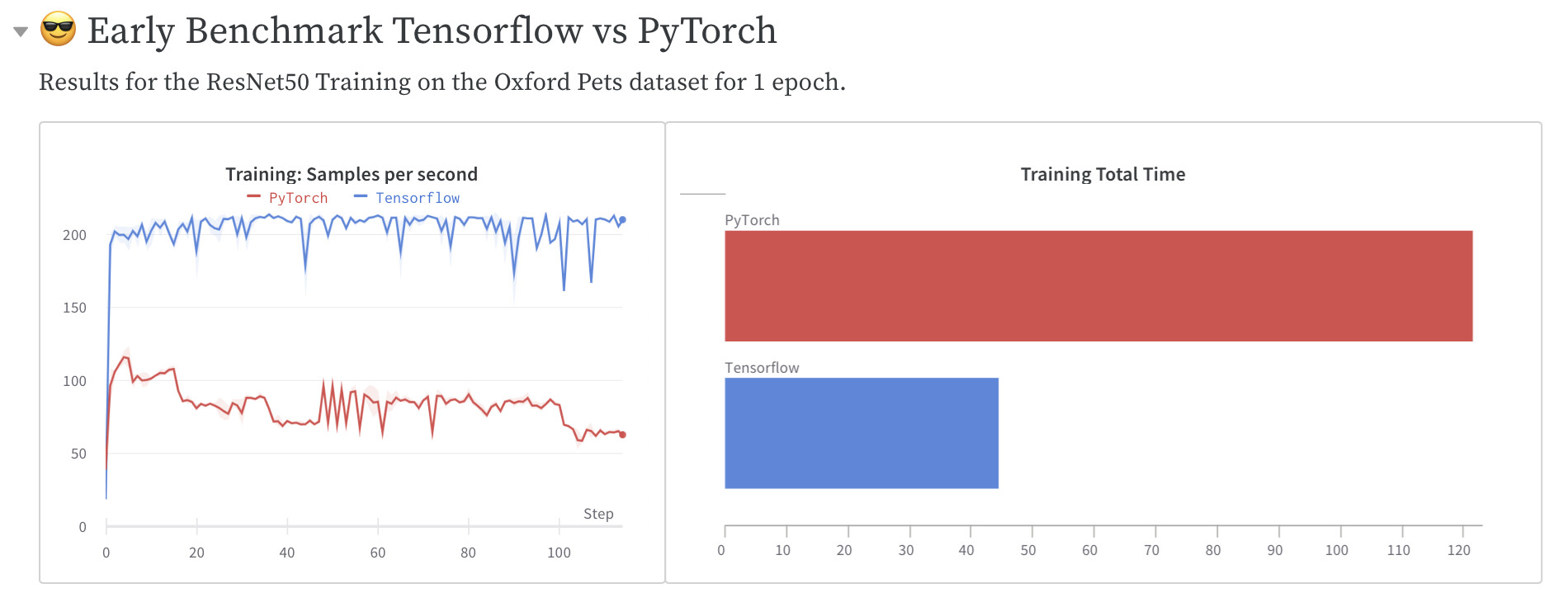
EDIT: So, I reran it and it just went with the 7300 images it had already downloaded. I’m not sure how to make heads or tails of this experiment but it’s at Weights & Biases if anyone wants to look at it.
Alex Ziskind and Daniel Bourke posted a collab on Youtube recently that compared runtimes for M1 Pro, M1 Max, M1 Ultra and an Nvidia Titan (Spoiler alert! Titan blew the Ultra out of the water, but still early days!)