Very cool, I think we know how to do this from having done state farm competition!
I started downloading the data bowl dataset (its massive), looking forward to try and use Keras / VGG convolution features and pass into some kind of decision tree and compare with results with dense layer models.
I find it difficult to structure this dataset. Only one or a few slice is malignant in a set of images that belong to a positive patient. I guess some manual identification is required to label what slice it is.
The official Kaggle tutorial is very helpful for preprocessing. One important step is to normalize all 3 dimensions to a 1mm grid. I’d suggest not thinking of it as a bunch of slices, but as a 3d volume. It’s basically impossible to separate a small nodule from vasculature without using 3d.
A good format for 3 or 4D medical data is Nifti (originally created for neuro imaging).
The basic format is an ND array of image data + a transform which describes orientation and scaling of the voxels in patient space.
There are tools for automatic conversion (e.g. dcm2nii) and a few python libraries (dcmstack - python 2 only and a newer one dicom2nifti).
The python library nibabel is useful for working with this format, and even if you aren’t working with neuro imaging data the nipy project may be worth checking out.
%pylab inline
import nibabel as nb
# set this to a nifti file
fp = '/data/data-science-bowl-2017/nifti/0015ceb851d7251b8f399e39779d1e7d/2.nii.gz'
# CT windows
# Radiologists describe settings for viewing different body parts
# as windows/levels, e.g. for lung the level is -600 Hounsfield
# units with a window of 1600 - i.e. ±800
# lung window
lung_params = {'vmin': -600 - 800, 'vmax': -600 + 800}
# body window
body_params = {'vmin': 40 - 200, 'vmax': 40 + 200}
# set to lung window
params = lung_params
params['origin'] = 'lower'
# load nifti object
nii = nb.load(fp)
# get nd array data
img = nii.get_data()
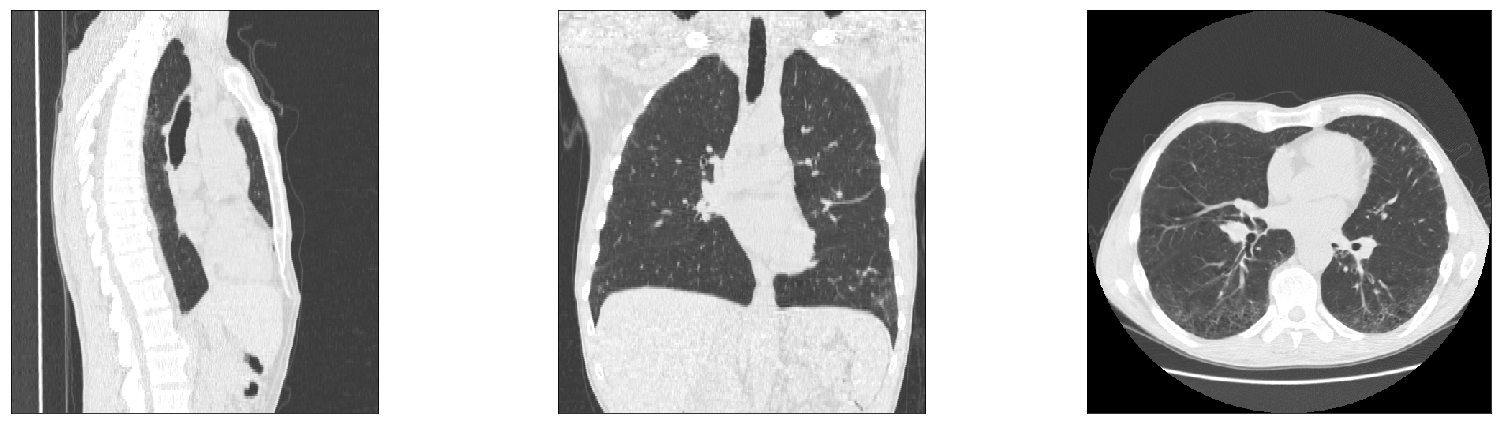
# get slices through middle of data
x, y, z = np.array(img.shape) // 2
fig, axes = plt.subplots(ncols=3, figsize=(24,6))
axes[0].imshow(img[x, ...].T, aspect=abs(nii.affine[2,2]/nii.affine[1,1]), **params)
axes[1].imshow(img[:, y, :].T, aspect=abs(nii.affine[2,2]/nii.affine[0,0]), **params)
axes[2].imshow(img[...,z].T, aspect=abs(nii.affine[1,1]/nii.affine[0,0]), **params)
for ax in axes:
ax.set_xticks(())
ax.set_yticks(())
plt.tight_layout()
I have followed one of the kaggle kernels and saved a weight by running 2 epochs.
Now I am trying to use that weights to predict using tensorflow in python 3.
I think I am doing something wrong, the predict function in tensor flow is not working as I thought.
@davecg - I’m really interested in your advice to use Nifti format. I had previously thought of it as something just for neuroimaging, but clearly that’s not the case.
I think the main thing stopping me from jumping right into it is that I don’t know what I don’t know… With DICOM, I know (more or less) the various ‘gotchas’ and issues required to be addressed, but I don’t know what the same issues can be with Nifti.
In particular: you mentioned that it can largely automatically handle a lot of the preprocessing; for, say, resampling to a 1x1x1 grid, will it handle all the different ways in which DICOM can incorporate slice width, pixel spacing, offsets, etc…? Do you have to do much manual cleaning up after converting DICOM to Nifti? If so, could you show what steps you would use for the data science bowl and LUNA datasets?
There are definitely more things possible in DICOM than can be contained in the simpler Nifti format. It can’t handle unequal slice spacing or rotating planes (both of which will sometimes happen in DICOM).
Only issue I came across in the Kaggle dataset was that one study had unequal slice spacing (think part of the data was missing but didn’t investigate too closely, just left that patient out).
Most converters can handle interleaving (MRI acquisition of odd then even slices), 3D + time datasets, diffusion tensor imaging, etc. I haven’t extensively checked out the source for dicom2nifti but it seems to work well so far for me (previously used dcmstack which is python only or standalone applications like dcm2nii).
Still downloading LUNA dataset, but for Kaggle DSB this worked for all but one subject:
from pathlib import Path
import dicom2nifti
data_path = Path('/path/to/data')
nifti_path = data_path.parent / 'nifti'
# assumes subjectid/*.dcm
for d in data_path.glob('*'):
o = nifti / d.name
o.mkdir(parents=True, exist_ok=True)
# this will create one Nifti file per series in folder
# only one per patient for Kaggle
# I.e. o / '{series}.nii.gz'
dicom2nifti.convert_directory(
str(d),
output_folder=str(o),
compression=True, # .nii.gz vs .nii
reorient=True, # left anterior superior coordinates
)
I can’t remember if it threw an exception or just logged something to STDOUT, but it mentioned unequal slice spacing.
Subject ID is b8bb02d229361a623a4dc57aa0e5c485, looks like they repeated the study under same series (or maybe it’s with and without contrast, haven’t looked at images).
Slices go from one side of pt to other, then start over again. By instance number each slice goes -2.5 mm then jumps back 260 mm before hitting the same positions again.