I am trying to implement The LSTM conditional GAN architecture from this paper Generating Image Sequence From Description with LSTM Conditional GAN to generate the handwritten data.
The main architecture used is shown below:
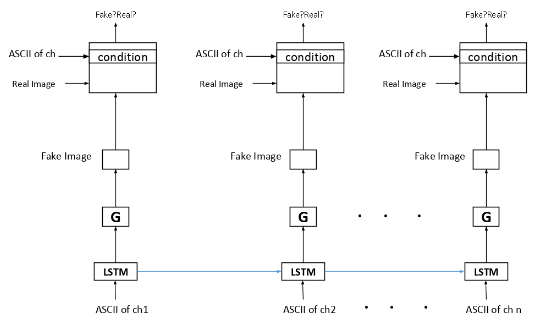
The main problem is to implement this architecture and seems different from others. The Implementation consists on Conditional DCGAN with LSTM . I tried something which is given below:
class Generator(nn.Module):
" Conditional DCGAN implementation with LSTM as input instead of noise vector"
def __init__(self):
super(Generator, self).__init__()
self.label_emb = nn.Embedding(config.vocab_size_l, config.emb_dim_l) # character level embedding
self.lstm_out = nn.LSTM(config.emb_dim_l, 64, 1)
self.main = nn.Sequential(
nn.ConvTranspose2d(config.input_image_len, 512, 4, 1, 0, bias=False),
# in_channels, out_channels, kernel_size, stride=1, padding=0
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(128, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64, 1, 4, 2, 1, bias=False), # fake or real
nn.Tanh(),
)
def forward(self, text):
" style_id: used to generate different style images"
h0, c0 = self.init_hidden(text.size(0))
emb_out = self.label_emb(text)
lstm_out = self.lstm_out(emb_out, (h0, c0))
out = self.model(lstm_out)
return out.view(x.size(0), 128, 32) # width=128, height=32
def step(self, x, h, c):
"""
Embeds input and applies LSTM one token at a time (seq_len = 1).
Inputs: x, h, c
- x: (batch_size, 1), sequence of tokens generated by generator
- h: (1, batch_size, hidden_dim), lstm hidden state
- c: (1, batch_size, hidden_dim), lstm cell state
Outputs: out, h, c
- out: (batch_size, vocab_size), lstm output prediction
- h: (1, batch_size, hidden_dim), lstm hidden state
- c: (1, batch_size, hidden_dim), lstm cell state
"""
self.lstm.flatten_parameters()
emb = self.label_emb(x) # batch_size * 1 * emb_dim
out, (h, c) = self.lstm_out(emb, (h, c)) # out: batch_size * 1 * hidden_dim
return out, h, c
def init_hidden(self, batch_size):
h = torch.zeros(1, batch_size, self.hidden_dim)
c = torch.zeros(1, batch_size, self.hidden_dim)
if self.use_cuda:
h, c = h.cuda(), c.cuda()
return h, c
def init_params(self):
for param in self.parameters():
param.data.uniform_(-0.05, 0.05)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.label_emb = nn.Embedding(config.vocab_size_D, config.emb_dim_D) # word level embedding
self.main = nn.Sequential(
nn.Conv2d(config.input_image_len, 64, 4, 2, 1, bias=False), # input_dim=128x32
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 512, 4, 2, 1, bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(512, 1, 4, 1, 0, bias=False),
)
def forward(self, labels, real_image):
"Take labels as description of image and real_image"
batch_size = real_image.size(0)
real_image = real_image.view(batch_size, 1, 128, 32) # width=128, height=32
c = self.label_emb(labels)
x = torch.cat([real_image, c], 1) # depth concatenation of real_image with label
out = self.model(x)
return out.sequeeze()
I am quite unsure that the implementation exactly matches or not the architecture details. The main idea is to send the character in LSTM each time step and pass the feature of LSTM to the generator instead of the noise vector.
Any helpful insights on implementation is useful. I am quite new on Pytorch and difficult on the implementation. Thanks in Advance.