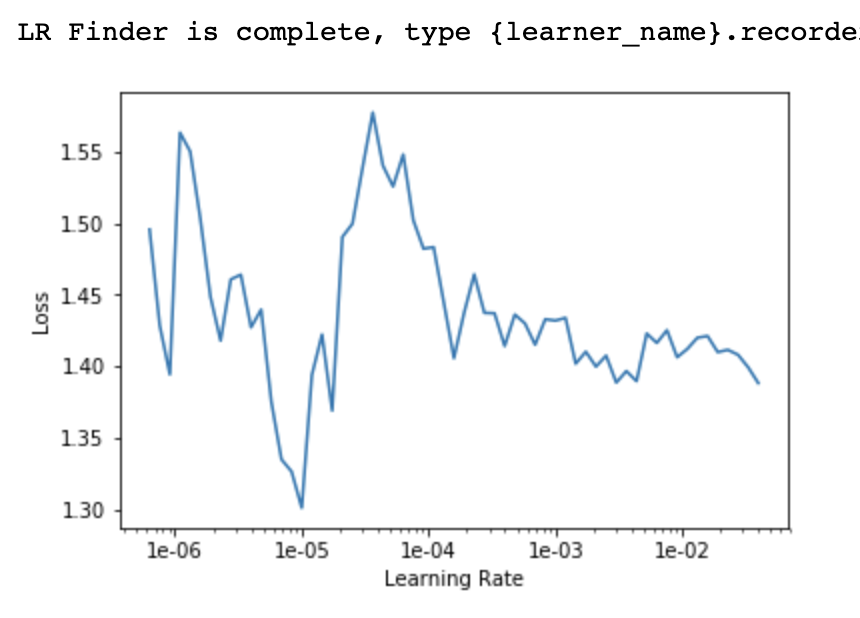
In this case I would try out 1e-4. But try out higher learning rates and if it doesn’t overfit or the loss doesn’t diverge, it’s probably good.
I agree, with low batch-size it’s harder to determine learning rate. One possible solution might be to utilize gradient accumulation to simulate higher batch sizes just for calculating the learning rate. However, the optimal learning rate is proportional to batch size so you would have to divide the learning rate by the same factor ex: gradient accumulation to simulate bs=32, find learning rate, divide by 2, and use for bs=16.
Thanks @ilovescience I’ll try that and see if that helps. I’ve just been using trial and error for the moment, but was just wondering if there was another way.
Looking around the forums, it sounds like for gradient accumulation I might need to write a custom training loop? Or maybe use callbacks?
This kernel has some version of gradient accumulation that seemed to work for an actual use case with batch-norm. But honestly I have no clue I have never tried this before so I can’t guarantee any of these callbacks will work properly.
Thanks for sharing your results. Unfortunately, I don’t know what the problem is.
Could you please share the loss curves and the curves of the metric?
EfficientNets are also notoriously hard to train. I would also try training with an EfficientNetB0 first and when things look good then scale up. I have done a lot of experiments with EfficientNets but based on the couple I have done and the discussion I have seen here, results on smaller EfficientNet models usually scale up pretty well.
Finally, what is the dataset you are using? Training difficulties may also be due to properties of the dataset. Given that you are using quadratic kappa, I am going to guess that you are using a diabetic retinopathy dataset?
Oh yea sure I’ll try that, I started with a effnet-b2 network actually but with a bs=64. But I actually got slightly better results with a effnet-b5 with a bs=16, so I began training more with that.
And yes you are right, I am using a combined 2015 and 2019 diabetic retinopathy dataset and using 224px. I preprocessed and re-saved the original images with crop + resize at 224px.
Maybe I’ll try some smaller efficientnets.
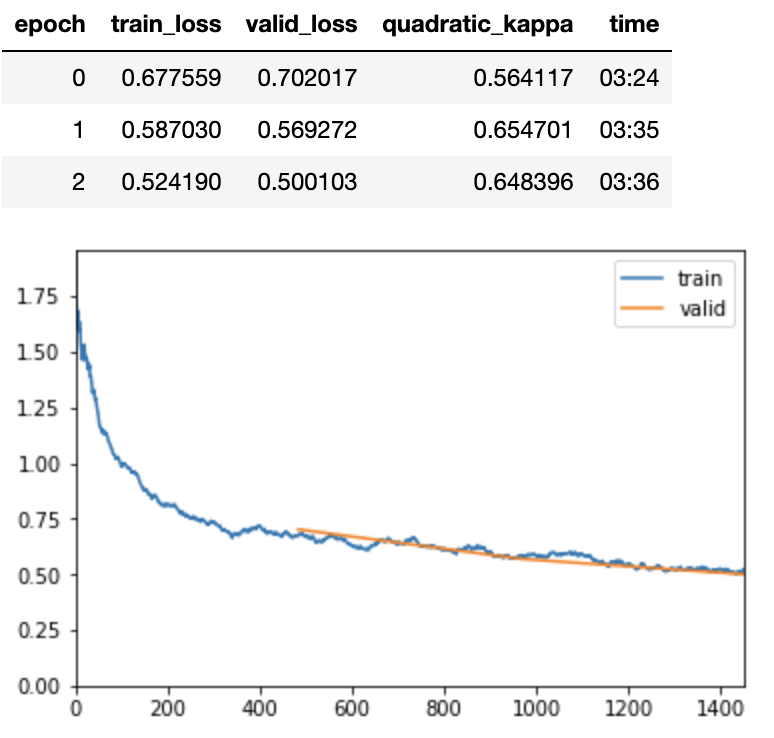
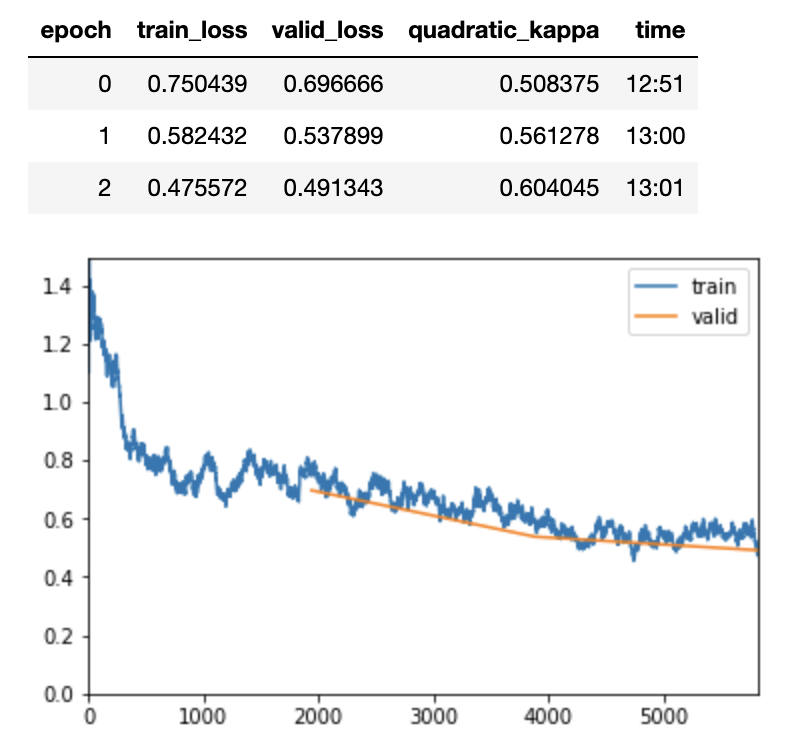
Below are some loss curves I’ve been getting without using the Accumulator (I’m training on a single RTX2070 with fp16, fit_one_cycle, frozen). I ran only one epoch with the Accumulator and got a loss of 13, so I didn’t bother training any further.
OK you are only training for 3 epochs. For those three epochs QWK = 0.65 actually doesn’t seem terribly bad. Note in my experiments I trained on the previous dataset for like 10 epochs, then the 2019 dataset for like 30 epochs. So I would run the experiment for many more epochs.
Also, it doesn’t seem that the B5 model is showing much advantage here. I would recommend doing the experiments with B3 first and then when you get good results with B3 you can move to B5 and probably get a gain in QWK.
Hey @ilovescience I just had one other question. When you said to try b3 first, then move to b5, did you mean to transfer learn the b3 network to b5? Or did you mean to try them separately and see which performed better?

 But appreciate all the new tips to try!
But appreciate all the new tips to try!