I have found some curious behavior of the lr_find() method after running one iteration of the language model in the lang_model-arxiv notebook (week 4). NOTE: I am running on the old arxiv.csv from Jeremy, not the full arxiv dataset.
I ran one epoch of the learner last night and saved the weights, just to load them and run them fully today (just wanted to be sure I could save / load weights properly). After loading the weights, I decided to run lr_find() before training extensively. When I then ran learner.sched.plot() I returned the following plot:
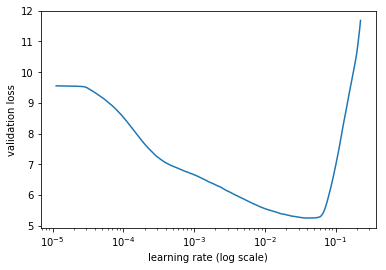
I found it curious so I re-initialized the model and ran lr_find, which yielded this graph (as it did the previous night):
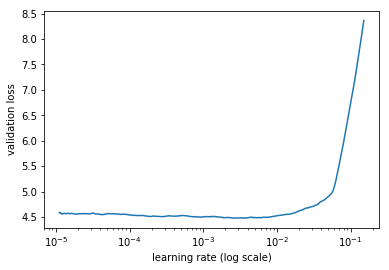
I then ran my first epoch again, and decided to check the behavior by running lr_find() once more to see if this behavior was repeatable. Indeed I did get this graph again:
.
I also noticed this on a Kaggle dataset of images (using a CNN) where there was basically a flat rate that eventually diverged, but basically no suitable learning rate.
Can anyone confirm similar behavior, and perhaps give me insight into what I’m seeing? Most curiously, why does the profile change so drastically after only one epoch of the language model?