Hello, I am currently using fastai to train computer vision models.
I use a development environment of this style.
On this machine we have :
CPU 16 cores
RAM 64go
GPU Nvidia A100
SSD 200go
I devellope on a jupyterlab container, on a 1 node docker swarm cluster.
The jupyterlab instance is installed on this image : nvcr.io/nvidia/pytorch:23.01-py3
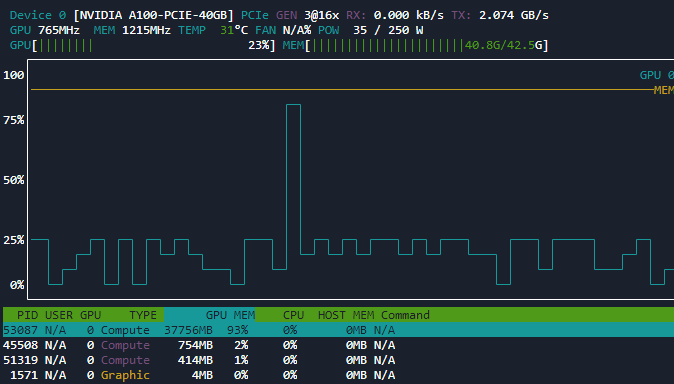
When I launch a training the GPU is not used at 100% it is more or less at 20% and the GPU memory is well exploded according to my batch_size.
Here is a screenshot :
I run a training via pytorch with the same model, the same data and similar hyperparameters and with pytorch it uses 100% of the GPU power.
I tried to install different versions of pytorch, fastai, cuda but nothing works with fastai the use of my GPU is always limited to 20%.
Would you have a reflection track, to help me to find a solution please?
Since you are not mentioning what dataset you are using and what network you are training it is place were I would check for the likely reason why it isn’t training as fast as you would like.
For example, if you have small/toy dataset like fashion mnist you will have hard time utilising a100. In fact I have similar training speeds on M1 Pro, 2080ti and a100 on hyper optimised data loading code. I’ve spend quite some time making the models train fast, so I don’t have much incentive to check what is the bottleneck now. But I’ve got 5x gains by tuning the dataloading .
But do you really need to invest time in fixing this? If the network trains fast enough, just change the instance to something older and cheaper and get few experiments running at the same time.
If you like tuning, then the easiest way is to load the whole dataset in to the memory in form that is fast to make batches. This alone will give you quite some gain.