This is the result I’m getting, the accuracy always gets stuck at around 60%.
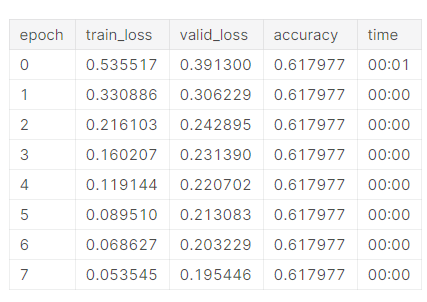
Maybe I’ve chosen the wrong categories?
This is the result I’m getting, the accuracy always gets stuck at around 60%.
Maybe I’ve chosen the wrong categories?
Part of the point of Titanic as a beginners competition is learning to clean up the data and feature engineer. They’ve messed up the data on purpose so you can’t just throw it at a model and get a good result.
Go and take a look at the Titanic forum on kaggle and some of the notebooks and start looking at what other people are doing.
Start by looking at each column and asking yourself what useful info you can currently get from it, and what info you could get from it. EG: ID isn’t going to help you, name probably isn’t terribly helpful but extracting title from it might be.
I have an intro to pandas notebook which covers some feature generation on the titanic dataset (but as @joedockrill mentioned, all of it is inspired from Kaggle kernels I read  )
)
Thanks for the responses @muellerzr and @joedockrill
