I am training a custom model that is essentially a hybrid tabular learner + convnet learner. This guide, which was also referenced in another forum post was extremely helpful for setting it up.
I am able to view batches and connect a DataBunch to my model using a generic Learner object. The lr_find() module works well, and I am able to train my model using the standard fit_one_cycle() policy.
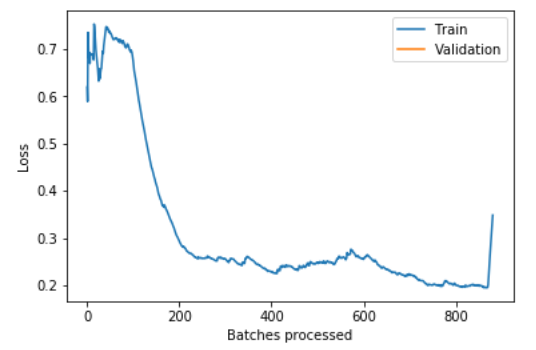
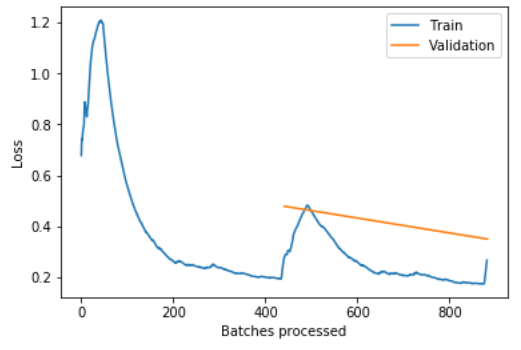
However, I am now encountering a strange result while training: the training loss abruptly increases for the final 1% of training (e.g., minibatches 790-800 out of 800). The same phenomenon occurs whether I train for one epoch or for many. Below is an example of my training losses for one cycle (= 1 epoch), and the figure below that shows another example of training using the one cycle policy (= 2 epochs). Note that the batchsize was doubled in the second case, so that the total number of processed batches is unchanged from the first case.
Has anyone else experienced this? Thank you in advance for your help!
No, I did not! I thought the rows were randomized already, but it turns out that the final few batches were not representative of the full data set and caused major issues. Sometimes the simplest explanations escape me when I’ve stared at it too long – thank you!
So I’ve got a new, but most likely related, issue. Here, the validation loss takes on a strange periodic structure within each epoch.
In this example I’m training for 5 epochs, and you can clearly see the 25 cycles as a series of dips and increases. Is this because my batches aren’t being shuffled?
EDIT: I tried to add shuffle=True to when I create the DataLoader, like such