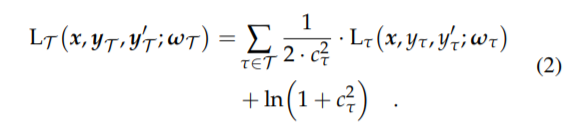You should include everything that’s trainable in your model in general. You can have the same tensor be a part of the model (that is unused) and the loss function (that is used there), since Tensors are a reference type, changing one/updating one will affect the other.
It’s been a long time since I worked on that. But I implemented this learnable weights method from the paper Auxiliary Tasks in Multi-task Learning. See section 2 for the formula.
Here is how I implemented that in my code on a toy project. loss_weights are coming from model in fastai (returned by the model to the loss). I append the loss for each of the tasks I cared about in my problem in losses. Then applied the formula. From what I remember it learned sensible weights between the various task losses, but it`s been a long time since I looked at that code.
I’m trying to do something similar but I dont want to rewrite the AWD_LSTM to include the learnable parameters. I wonder if there’s a way to add new parameters to the AWD_LSTM model.
I don’t have the code in front of me, but you could simply subclass the AWD_LSTM model, in the constructor, create your learnable weights, in the forward function return the value of the base forward method and also your learnable weights. Eventually those two values would get passed down to your loss function where you can use them. From what I remember though AWD_LSTM uses a bunch of callbacks that might get affected if you do that.