Hi guys,
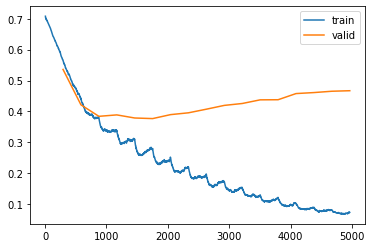
Anybody ever seen a loss function periodically increase / decrease? Here’s what happening:
Overall, the training loss decreases during training, but every few iterations it goes up a bit and then decreases again. I think this might be the optimizer (default Adam) fault, but I’m not sure why it would cause something like this.
My 2 cents:
The training loss and the validation loss both are going down till 1000 iterations. But then the validation loss constantly increases because the network is overfitting - at the same time the network is still “trying to learn the data”, but it’s hard for it (hard, because it’s not really learning anything from this point, only try to memorize all the data) and on that harder points the training loss can increase temporarily, but with optimization the network eventually finds its way to memorize (even if it memorize something totally random, it can memorize, because it has millions of weights for it ;)).
You can think like if you have millions of hills and you need to find even only 1 to going down from 1 point - because of that sheer number sooner or later you will find 1 down in almost any point
Makes total sense! I guess I was too concerned about my metrics increasing (they were increasing from time to time but it was very random) that I didnt pay enough attention to the loss diverging. I’m running some experiments and it was definitely overfitting.
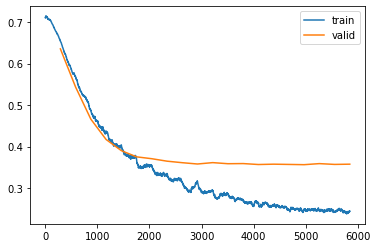
Now I lowered the learning rate and added more dropout. The periodic behaviour is still there, but it’s much less pronounced.
fit_one_cycle only has one cycle of learning rate and it happens over multiple epochs, while this seems like it’s potentially cycling multiple times per single epoch.
You are right of course - it was just a guess without seeing the actual training code.
It’s a strong and compelling observation. But before constructing a new theory I’d eliminate simpler explanations for the periodicities. Like a cycling of LR, or a cycle per full batch when the examples are not shuffled, or a per batch reset of some parameter that affects training. If the effect remains robust, then you’ve found something with deeper significance.
Its a standard training loop with tabular data. I’m actually using fit_one_cycle and made sure my data is shuffled. I’m not seeing that periodic behaviour with a higher dropout rate.
Ok, one more idea. From the graph, it looks like each training loss cycle is coincident with each validation loss calculation. Validation loss is recorded at the end of each epoch, right? So why would the epoch cycle be the same as the mysterious training loss cycle?