I have a tabular dataset and I aim to predict the category of a target variable among 5 options. However, I need to take into account that 4 of these categories are correlated with each other in pairs (the first is correlated with the second, and the third is correlated with the fourth). Therefore, I intend to develop a custom loss function that penalizes larger errors if the predicted value falls outside the correlated categories while the actual value does not. Since I couldn’t find any relevant resources online to get started, I wonder if someone would be willing to assist me in writing it. Thank you!
I think I’ve figure out a working solution—here is a notebook with my approach. I haven’t written a custom loss this complex before so I imagine there are cleaner ways to write it. But it seems to be working (the model trains on it, and it’s value each epoch is a bit larger than the regular cross-entropy loss which is a good sign that the penalty is being applied). Let me know what you think!
pred_penalty_idx is correctly True if pred is NOT 0 or 1 where targ IS 0 or 1—but pred_penalty_idx also is True if pred IS 0 or 1 where targ is some other class (in your full case, 2, 3, or 4).
In your full case with 5 classes, I think you would have to think about how to handle that case—you want the penalty applied if pred is 1, 0 or 4 where targ is 2 or 3. But you don’t want the penalty applied if pred is something other than 4 where targ is 4.
My approach for your full case might get messy/confusing quick. Maybe there’s a logical pattern out there in numpy or torch that gets this done cleaner and more easily.
Sorry for the late response, I’ve been very busy. By the way, thank you so much. I got the idea and understand the code and i think I’m close to adapt your idea to my data. I’m having trouble understanding where I’m doing wrong: i basically took the code for the crossentropy and added a penalty but the loss values are very high and I don’t understand why. Here’s the code I came up with:
classes = {0: 1, 1: 1, 2: 2, 3: 2, 4: 3}
class GroupLoss(nn.Module):
def __init__(self):
super(GroupLoss, self).__init__()
def forward(self, inp, targ):
sm_acts = torch.softmax(inp, dim=1)
losses = []
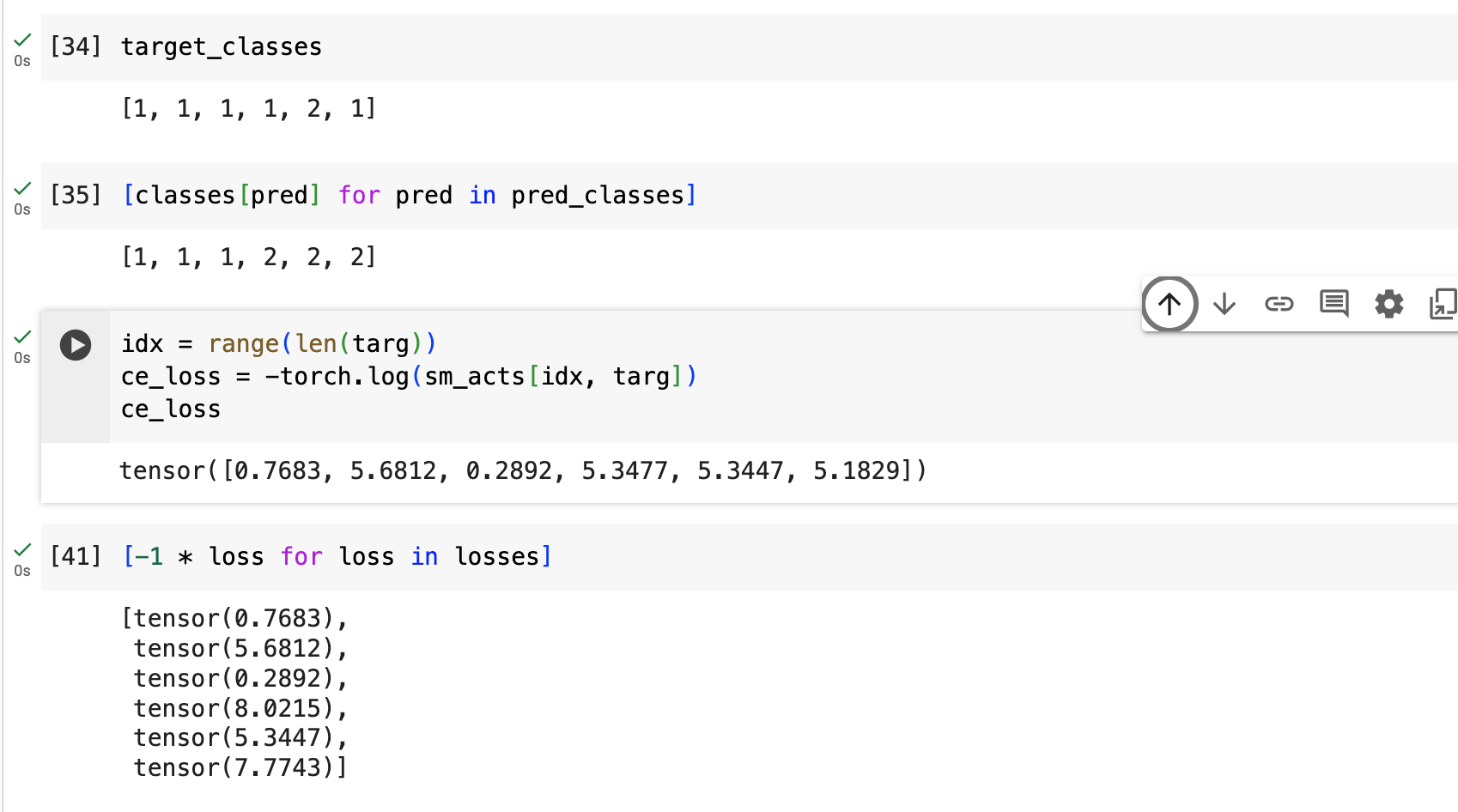
for i in range(len(targ)):
target_class = classes[targ[i].item()]
pred_class = sm_acts[i].argmax().item()
if target_class != classes[pred_class]:
losses.append(torch.log(sm_acts[i][targ[i].item()]) * 1.5)
else:
losses.append(torch.log(sm_acts[i][targ[i].item()]))
return -torch.stack(losses).sum()
I ran your forward code in the Colab notebook using the same sm_acts and targ as used before in that notebook and got the same resulting loss values per item (and total). So that leads me to believe that your forward method is not the problem? Can you share the rest of your code? And possibly data (or representative fake data) in order for me to try and recreate your issue?
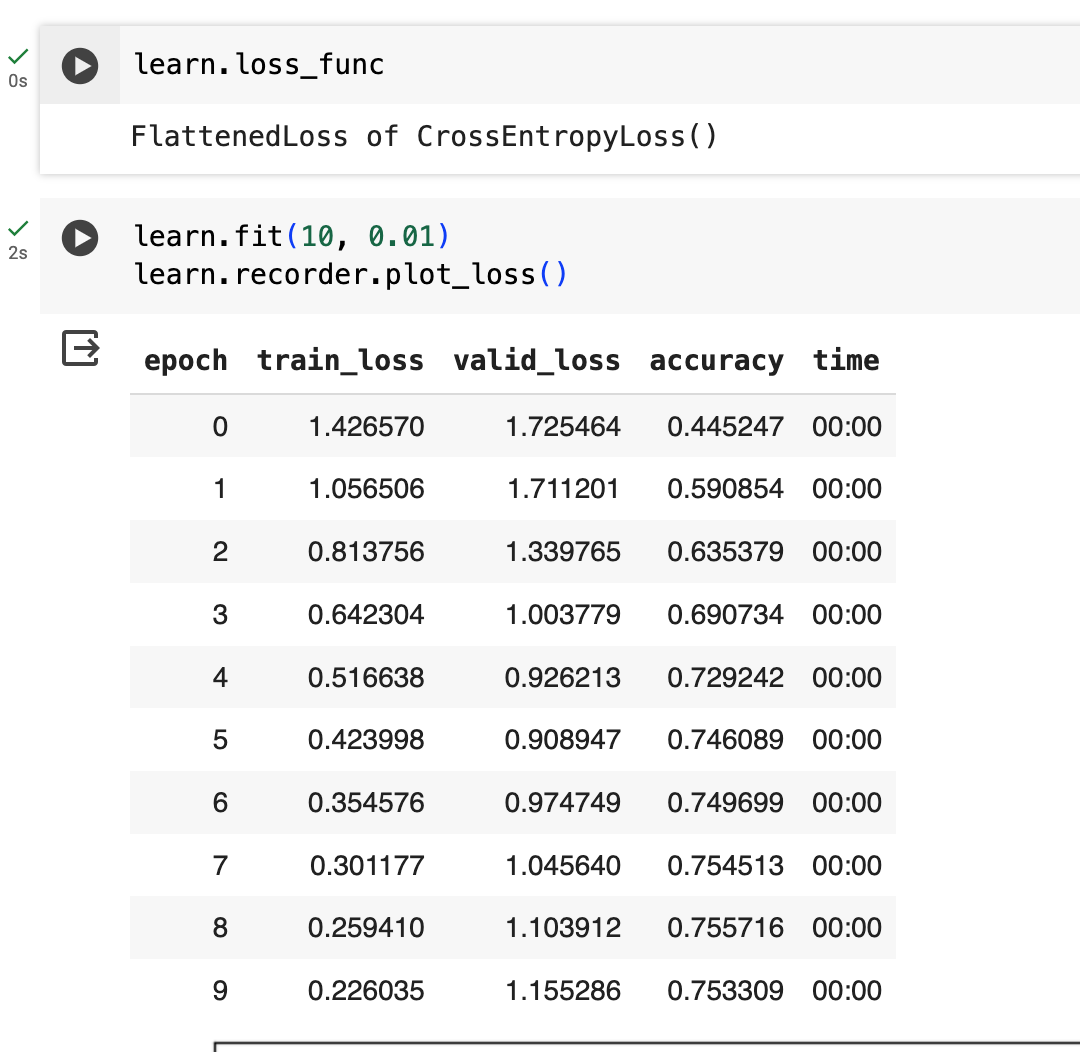
Which is comparable (slightly larger values, which makes sense as the penalty of 1.5x is being applied to certain values) to training it with the default CrossEntropyLoss which defaults to reduction='mean'.
One additional question I do have is about how you have defined classes. Shouldn’t it be defined as follows? I have also updated your forward method accordingly. Perhaps I’m misunderstanding what you stated in your original post.
# classes = {0: 1, 1: 1, 2: 2, 3: 2, 4: 3}
classes = {0: [0, 1], 1: [0, 1], 2: [2, 3], 3: [2, 3, 4], 4: [3, 4]}
class GroupLoss(nn.Module):
def __init__(self):
super(GroupLoss, self).__init__()
def forward(self, inp, targ):
sm_acts = torch.softmax(inp, dim=1)
losses = []
for i in range(len(targ)):
target_class = classes[targ[i].item()]
pred_class = sm_acts[i].argmax().item()
if target_class not in classes[pred_class]:
losses.append(torch.log(sm_acts[i][targ[i].item()]) * 1.5)
else:
losses.append(torch.log(sm_acts[i][targ[i].item()]))
return -torch.stack(losses).mean()
In this way, correlated classes are considered “correct” if the target is either of the two correlated values. Since 3 is correlated to both 2 and 4, all three are considered correct.
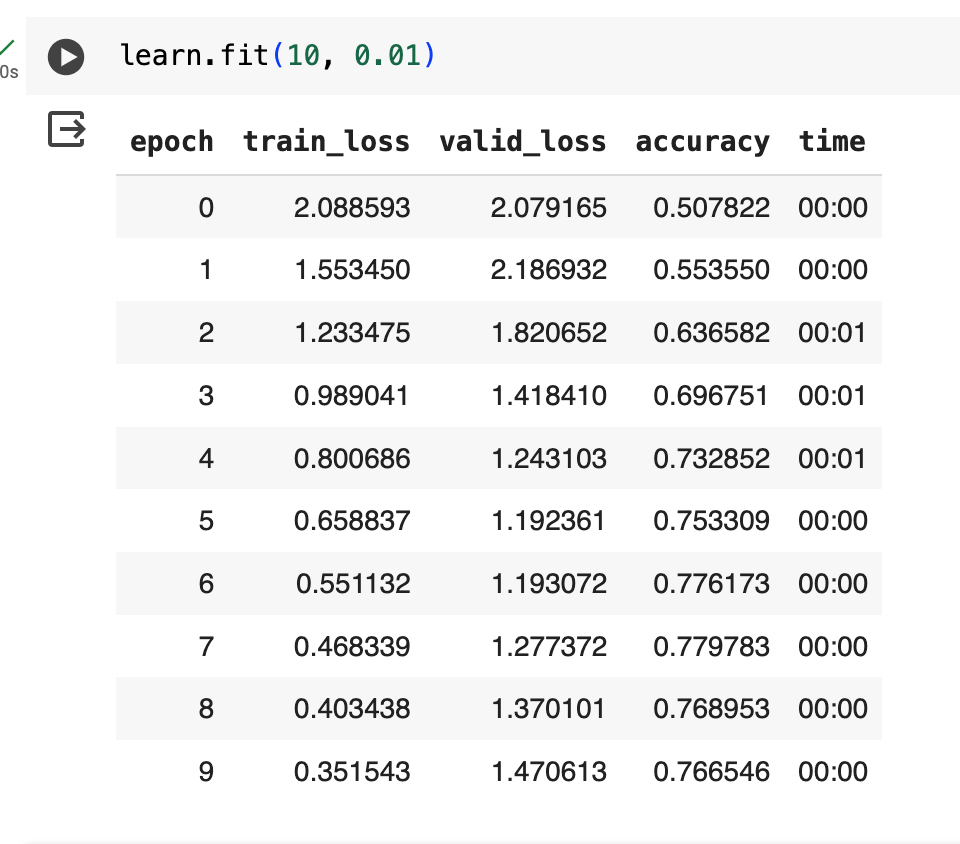
Training it with this loss function doesn’t really improve accuracy—which makes sense, I think you’ll have to define a custom accuracy metric as well if you are considering correlated classes “correct” predictions.
Sorry if I explained my self bad for the classes thing: in my data the classes are Benign, Likely Benign, Pathogenic, Likely Pathogenic and uncertain. I wanted to penalize more if the prediction is Benign and the target is Pathogenic then if the prediction is Likely Pathogenic because the first prediction is way more wrong. So what I did is just define Likely Benign and Benign in the class 1, Likely Pathogenic and Pathogenic in the class 2 and uncertain in the class 3 so that if the prediction and the target are in different classes, the penalty is applied.
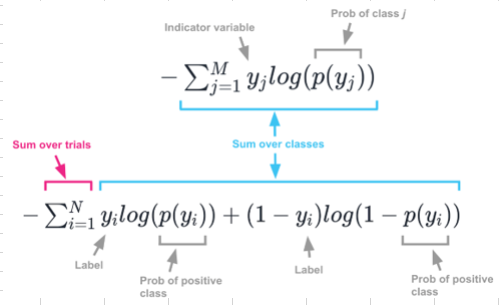
About taking the mean I thought of that too but I took the formula that Jeremy showed In lesson 7, which is:
So I didn’t have any reason to take the mean other then “That way, it works”
Yeah I don’t have a good intuition about why to use it either.
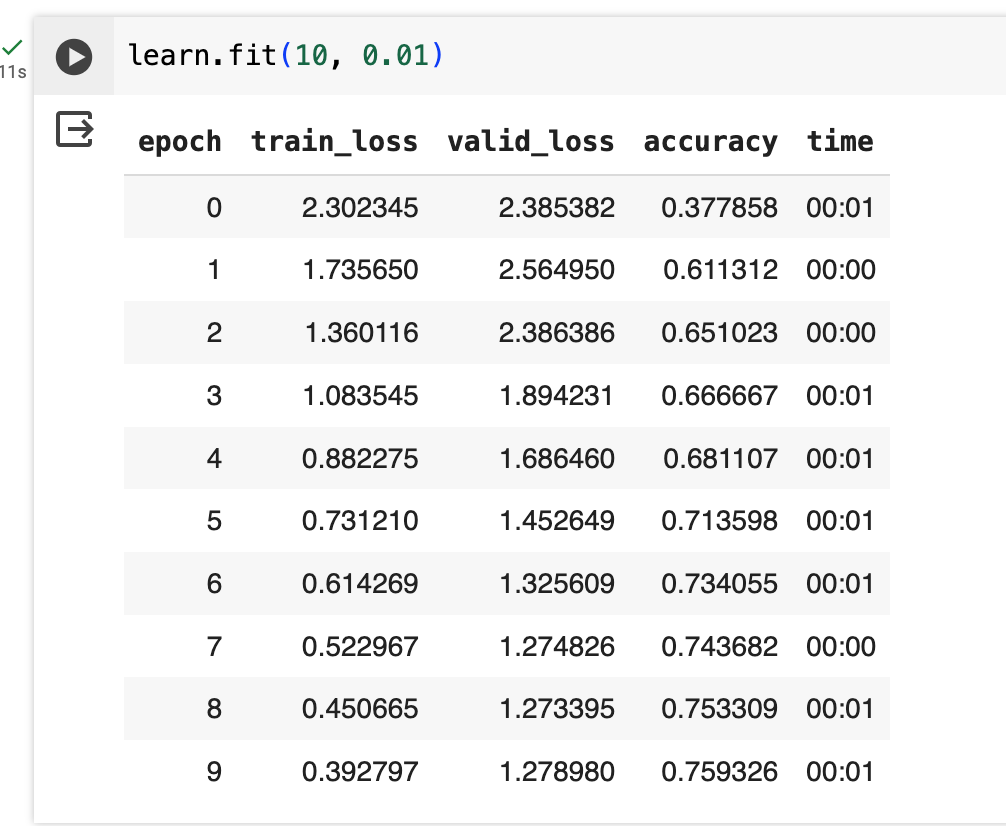
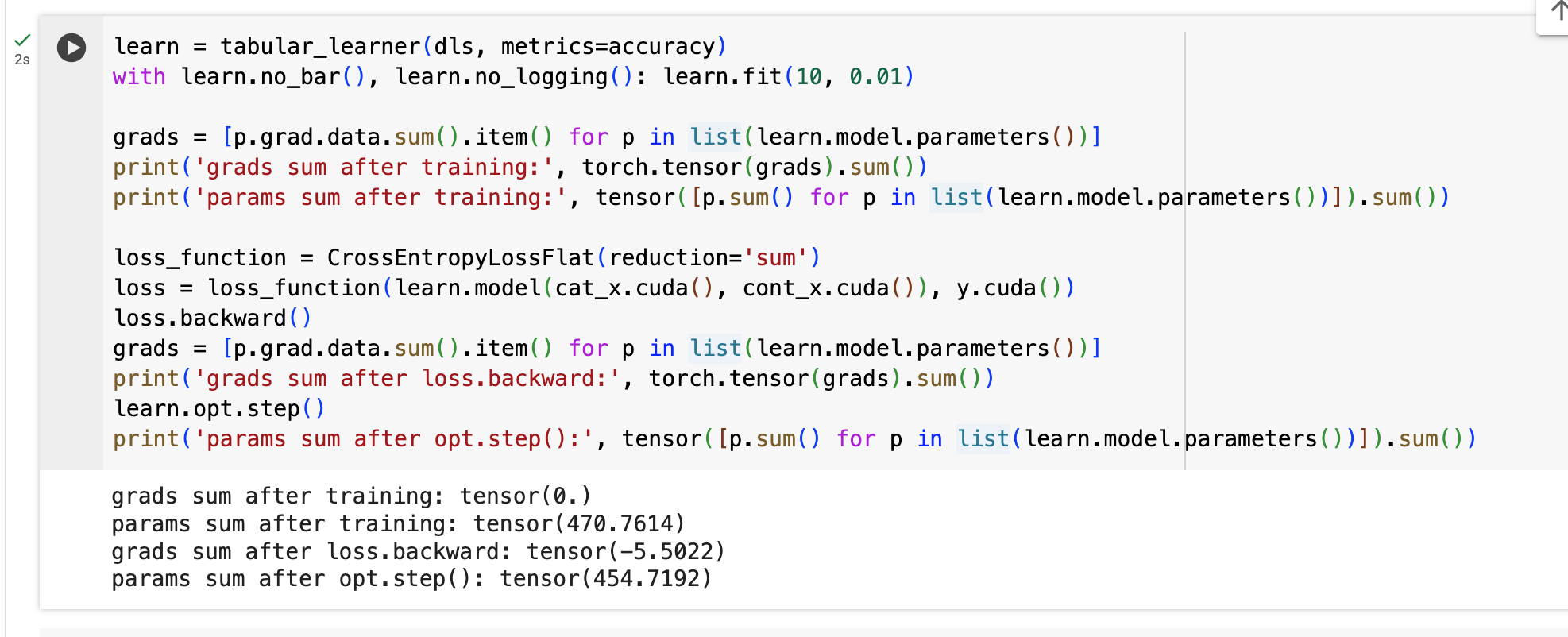
This PyTorch forum post provides some intuition, that when using sum the batch size affects the loss and also that the loss function affects the gradients.
I ran a little experiment as shown below, the gradients are much larger for a loss function with reduction='sum', and the parameters also change more after the optimizer step
I’m confused why both trainings are successful and yield similar epoch accuracies if the gradients are so different. This is the limit of my understanding so far of the internals of fastai so I can’t dig much deeper quickly.
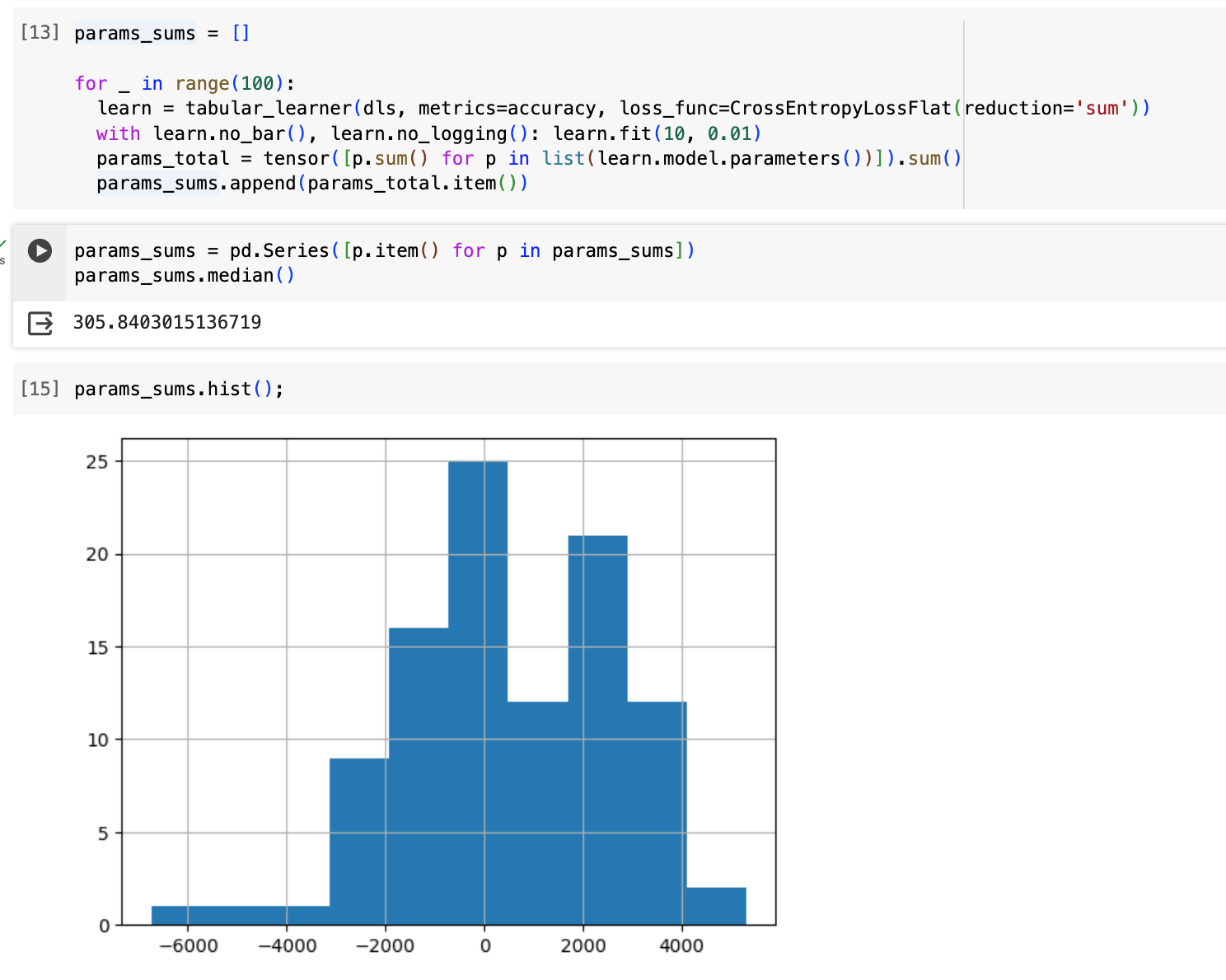
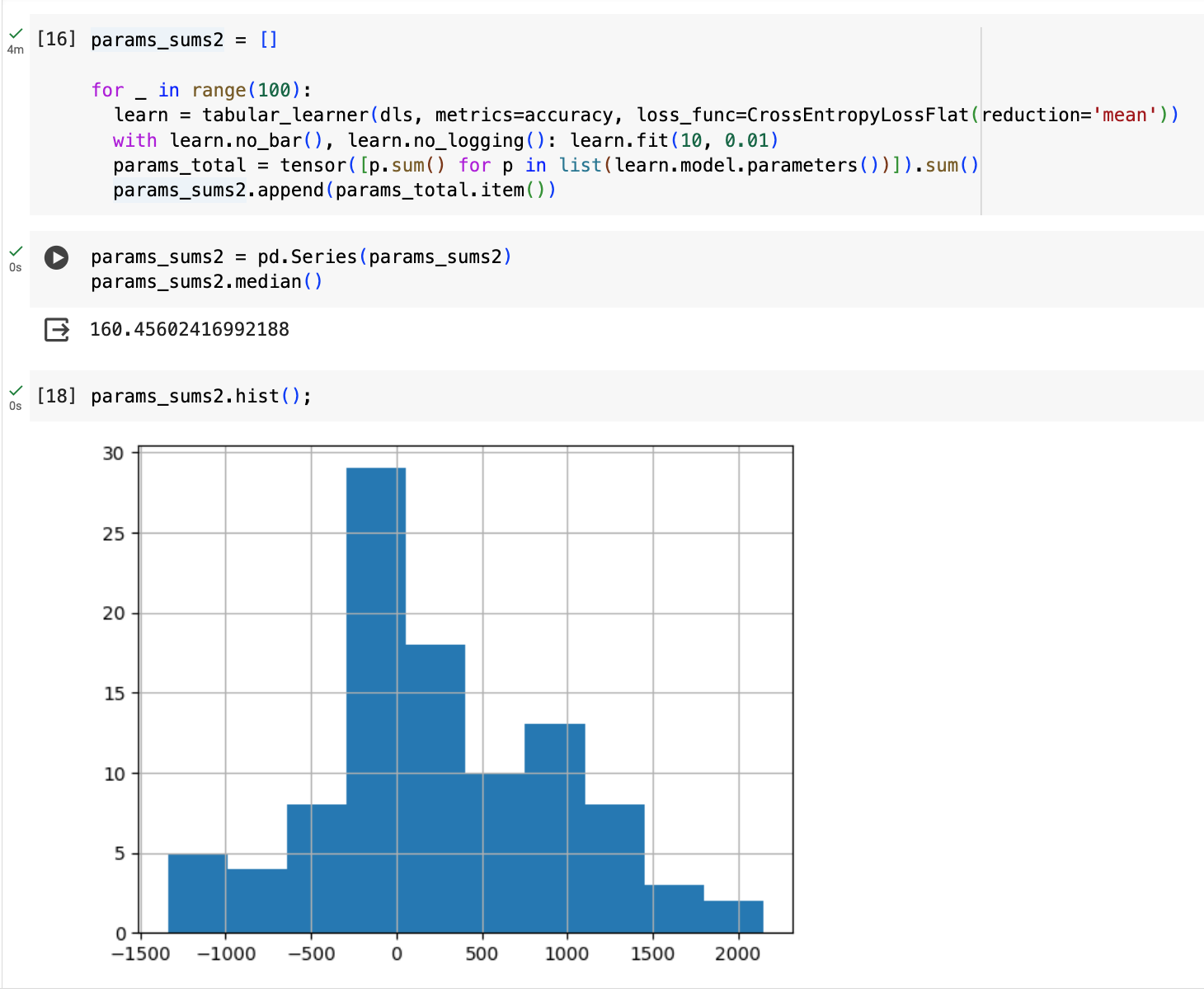
Adding one more experiment: training with each loss (sum and mean) 100 times and looking at the resulting sum of all of the model’s parameters—I end up with much larger median sum of parameters (and wider range) with sum than mean: