I created a very small data set by downloading a few images of three different international currencies from Google Images. It’s definitely not the greatest data set in the world, but I was expecting to get better accuracy than what I’m getting (it would be an easy problem for a human). Typically I get about 80% accuracy, but it does vary a bit.
Challenges of this data set
There is very little training and validation data. For example for the Hong Kong Dollars, there are only 12 training images.
There are bills in the validation set from years that have no equivalent in the training set. For example for the Hong Kong bills, in the validation set there are red colored bills but none of the bills in the training set have this style/color.
There are very different image sizes ranging from 1000 (w) x 500 (h) to 450 (w) x 200 (h)
One thing that I thought would improve things a lot, bit didn’t, was to switch from center cropping to no-cropping. With center cropping, it was transforming images like this:
to images like this:
Whereas with no cropping it would squash the images down to images like this:
Which seemed like it would be a lot better, since at least it preserves the word “Indonesia”. So far it didn’t seem to improve the accuracy at all though.
Also, I didn’t seem to get any improvement using the data augmentation (I tried transforms_basic and transforms_side_on). I didn’t try test time augmentation (TTA) since I don’t have a test set, and I’m a bit confused on whether I actually need one or not.
I think more data is extremely rarely a bad thing. I would say if you can get more data, do that.
As for your cropping problem…squeezing, as I recently discovered is the default behavior of Keras, is generally not a good idea. Are you doing random cropping? If not try using random cropping and TTA.
Jeremy uses Test Time Augmentation (TTA) to account for the cropping missing pertinent parts of the image.
Your model is definitely learning, but it’s overfitting to the training dataset - May be because each of the notes (particularly the HK / Indonesian ones) are fairly unique?
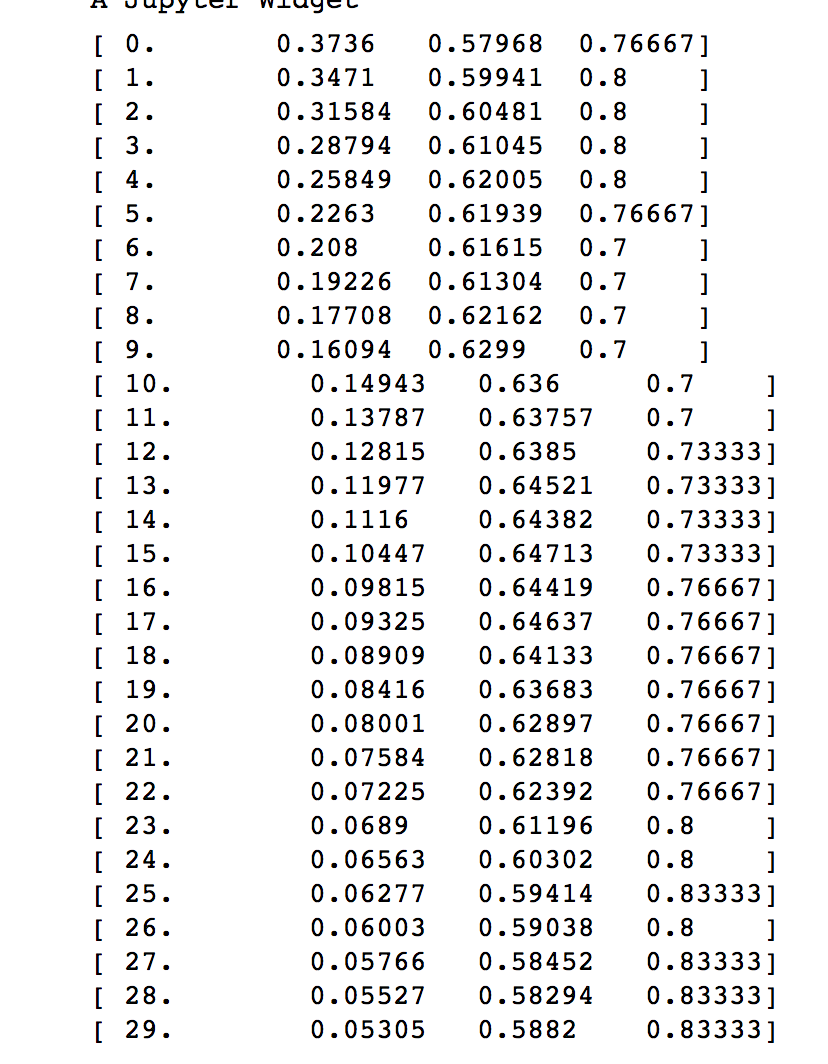
As you can see the Training loss kept going down -
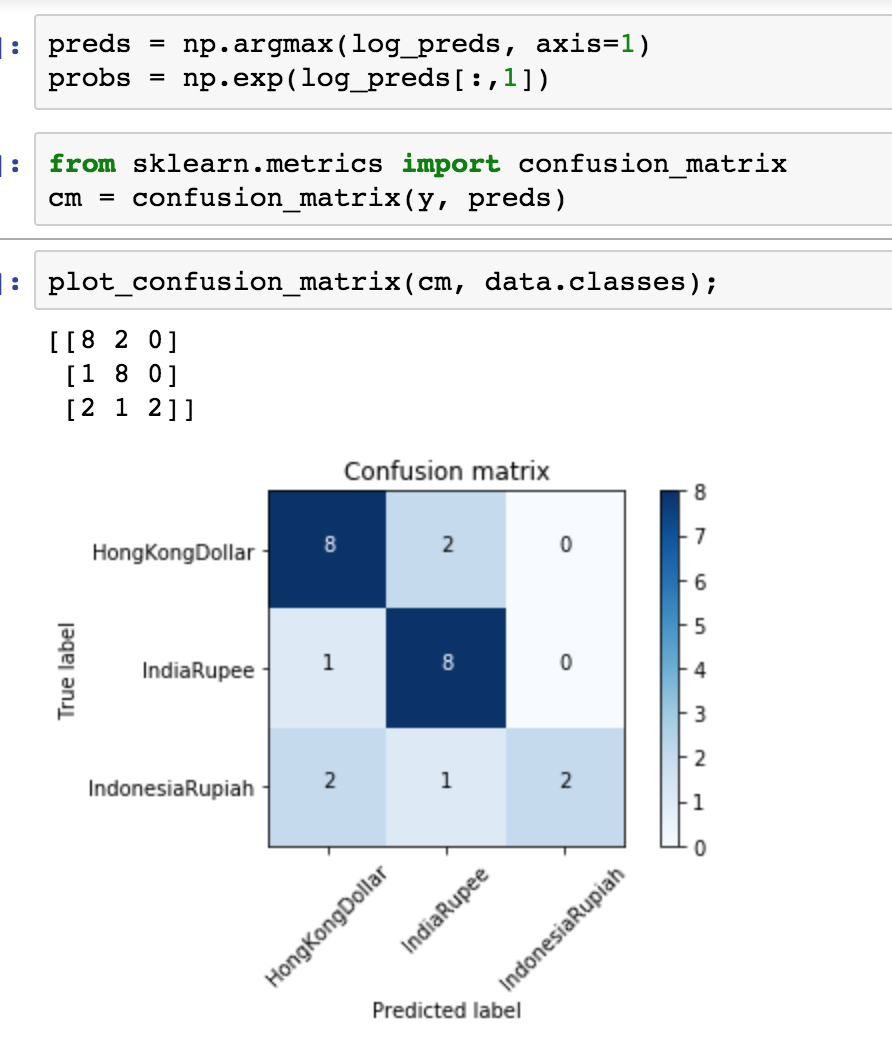
Also the confusion matrix - shows that Indian Rupee are fairly distinct, so you may not need more of it, but may need lot more Indonesian even HK Dollar
If all of your bills are nicely horizontally aligned, and the right way around, then the regular data augmentation definitely won’t help (as you noticed), since the augmentation isn’t creating variation that you actually see in the validation set.
@metachi I will definitely try random cropping, that sounds promising. Do you happen to know if it’s one random crop per image or will it generate multiple croppings per image? I feel like if it’s only one, it might miss some very distinctive parts of the image.
I’m not using Test Time Augmentation, and in fact I don’t even have a test set. I didn’t fully understand the need for one. Can TTA still be used?
@jeremy that makes sense, and probably highlights how unrealistic this data set is. I’m guessing in most “real world” image data sets data augmentation would be beneficial.
it has the same emblem with the Unicorn and the Lion over the picture of the ships sailing in, but with different color schemes. I’m starting to wonder if normalizing these to grayscale would improve the results, because it seems like the color channels might just be making the problem more complicated for the algorithm.
I’ll try it and see if it improves accuracy. Does the fast.ai library have a way to specify to treat all images as grayscale?
@tleyden This is a great project! Very fun. I am thinking it might be easier to do this with coins, they are equal width/height at least. But bills are more fun
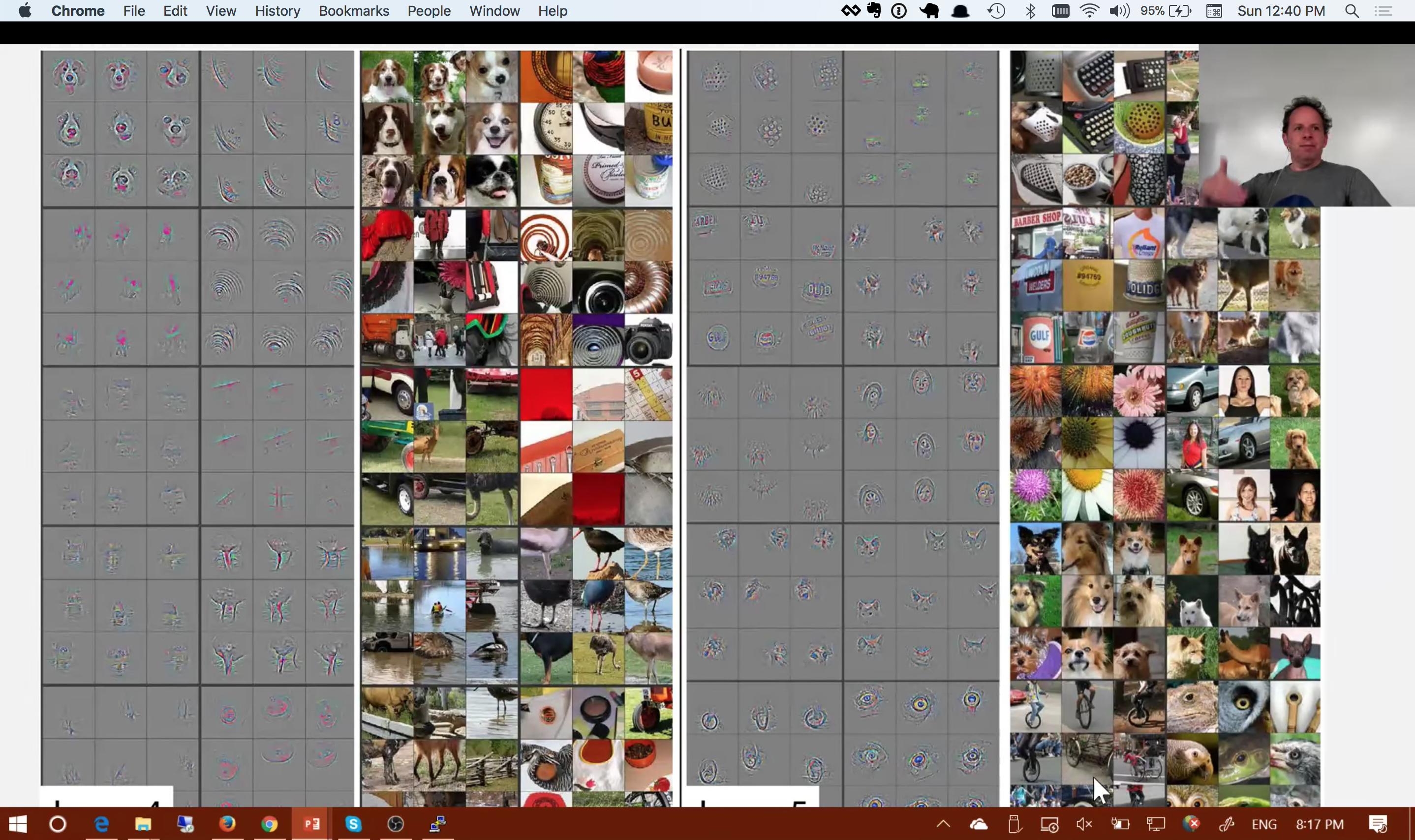
Is there an easy way to visualize the filters at the various layers? For example, given the fine tuned network which is giving 70% accuracy on the currency data set, generate something like this:
I’m wondering if I’d see filters that had components of the currency bills like:
or if there would still be cat and dog faces and all the other high level images from ImageNet?
Given the low accuracy, I’m guessing it would be the latter.
To try to fix that, how could deeper layer weights completely be randomized with a resnet34 model? Eg, try to just keep the weights that correspond to lower level features from layer 1 and layer 2 like:
and then retrain all of the other layers from scratch, and hopefully after that training all of the later layers would represent higher level features of the currencies.
@tleyden I think you can get more images for Hong Kong dollars from Google images.
There are three banks, named: Standard Chartered Bank, The Hong Kong and Shanghai Banking Corporation (also known as HSBC) and Bank of China. They issue bank notes in six-denomination each (ie HKD20, HKD50, HKD100, HKD500 and HKD1,000).
The government of Hong Kong Special Administration Region (HKSAR) issues only HKD10 bank notes. So, you should have minimum 38 unique images to train your model. (3 banks x 6 denominations x 2 sides + 1 HKSAR x 2 sides).
Sample bank notes issued by HSBC (6 denominations with both sides)