I am working on a simple library meant to be used as a learning aid to understand how neural networks work internally.
It supports arbitrary operations and can compute the gradients for any op (just like tensorflow,pytorch, etc).
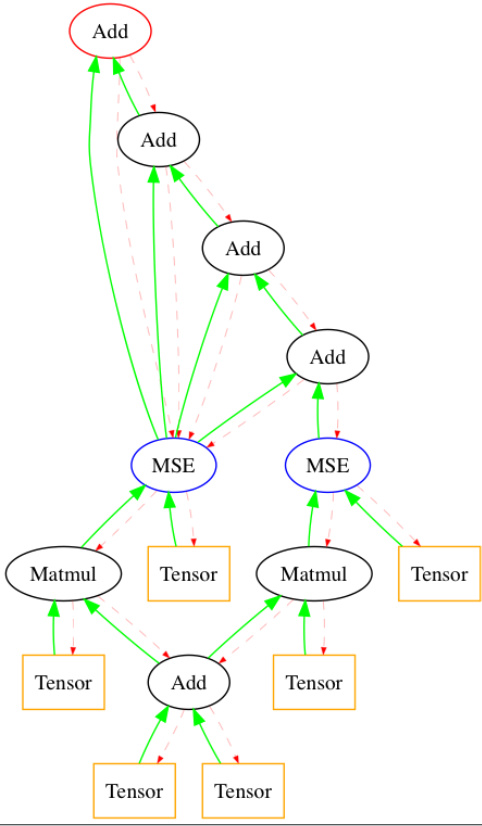
An output from one such computation graph:
Hi harveyslash,
I’ve taken a quick look at your library and I you can easily improve the performance. For example in Add.py:
def forward(self):
left = self.children[0].forward()
right = self.children[1].forward()
add = np.add(left, right)
return add
def backward(self, respect_to_node, parent_grads=None, **kwargs):
back = parent_grads
if back is None:
back = np.ones_like(self.forward())
if respect_to_node == self.children[0]:
child = self.children[0].forward()
elif respect_to_node == self.children[1]:
child = self.children[1].forward()
In the backward method you are calling the forward method. You can assume that before a backward pass there is a forward pass. So you can save self.add = np.add(left, right) on the forward pass and use self.add in the backward pass. Using this approach you won’t need to recompute all the graph.
You can also do the same with children.
The forward() method is called only once when its required. Any other time its called, the values are cached , so it will be returned instead of recomputing.
This cached value can be manually removed by calling clear() on the graph.