I remember we said in class that we needed to “clip” the probabilities for dogs vs cats redux because if you give a 1 when the answer is actually 1, you’ll end up with a higher loss than if you use 0.95 or what have you, because of the nature of how log loss is computed.
What I didn’t understand was why we wouldn’t just clip at 0.001 / 0.999, ie closer to 0 / 1 ? When I played around in the spread sheet it seemed to me that this actually lowered the loss.
So I’m not entirely sure about this, but I suspect it is because Log Loss punishes being overconfident and wrong way more than it praises being super confident and right.
I’m still confused why the VGG16 model for cats vs. dogs makes so many predictions that are 1.0 or 0.0. The loss function is being set to ‘categorical_crossentropy’ in the vgg finetune method. So you would think that the model would learn the optimal clipping values in the training process. My only theory is that the model has not been trained for enough epochs. (Or, the learning rate could be higher for longer, or lower for longer.)
I’ll try training the model for longer and see what happens.
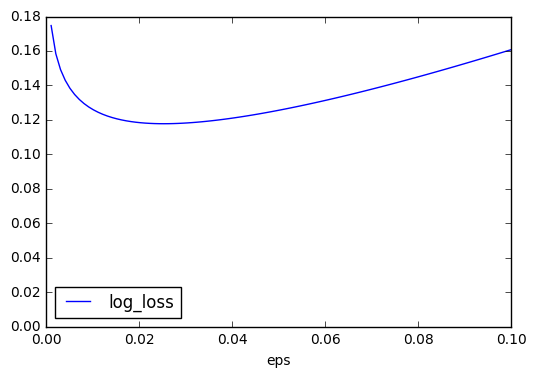
In the meantime, I’m computing the optimal clipping value by a brute force method.
Because the model is seeing the same training inputs multiple times, it is getting very good at predicting them, so it makes sense for it to predict very close to one or zero. But on the validation set this over-confidence gets penalized!
I think I’m confused on the role that ‘categorical_crossentropy’ is playing in the training of the model. If the model was getting perfect accuracy on the training set, the predictions of 1.0 and 0.0 would make sense since the high penalty never comes into play. But there are still mis-categorizations in the training set. Here’s the confusion matrix from testing on the training set.
[[8369 275]
[ 70 8536]]
That’s still 2% of the samples in the training set that are incorrect. Looking at these 345 errors, only 15 are values other than 0.0 or 1.0.
I think I’m assuming this is like other kinds of machine learning models, like logistic regression, but it is very different.
I’m not sure I understand your question or where you’re confused… Have you looked at the worked example in http://www.platform.ai/files/xl/entropy_example.xlsx ? Can you explain more about what you’re unsure about?
Logistic regression and crossentropy are identical in the binary case!
I’m still confused about the reason for the over-confident outputs of the model. I was assuming that compiling the model with categorical crossentropy would result in clipped values automatically, since the model would be highly penalized by guessing wrong with a 1.0 or 0.0. If clipping reduces the loss, why wouldn’t the model learn this?
One possibility is that confident wrong predictions are not penalized that severely. Looking at the Keras code, it applies an epsilon of 1e-8 for clipping values passed to categorical_crossentropy, so the maximum contribution of an extreme value is only -ln(1e-8) = 18.42. In the case of training with 17,250 samples, this contributes only 0.001 for each confident wrong answer.
Kaggle log-loss uses an epsilon of 1e-15 which is almost twice the penalty. Keras has a set_epsilon method so I may try experimenting with that to see if it has an effect.
It is over-confident of the training set, since it’s very good at calculating the predictions for the training set, so it makes perfect sense for it to get close to one and zero for those predictions. But (by design) it knows nothing about the validation set, where it is much less accurate.
In an effort to better understand log loss, I wrote a little formula to attempt to replicate the Keras training / validation output:
# Training log loss
-1/len(trn_labels)*sum(sum(np.multiply(trn_labels, np.log(trn_preds))))
Everything seems okay for the validation data where the formula equals model.evaluate as well as the last Keras epoch (4.0176). However, in the case of the training data, the formula equals model.evaluate (0.000397), but not the loss metric from the last training epoch (0.2099).
I had been assuming that “loss” and “acc” from the epochs were equal to log loss and prediction accuracy for the training data. Apparently, this is not correct?
Why is the training loss much higher than the testing loss?
A Keras model has two modes: training and testing. Regularization mechanisms, such as Dropout and L1/L2 weight regularization, are turned off at testing time.
Besides, the training loss is the average of the losses over each batch of training data. Because your model is changing over time, the loss over the first batches of an epoch is generally higher than over the last batches. On the other hand, the testing (validation?) loss for an epoch is computed using the model as it is at the end of the epoch, resulting in a lower loss.
Shouldn’t the spreadsheet Jeremy shows in lesson 2 be using “ln” instead of “log” to look at this?
I suppose in practice the two both have the same characteristics, so it’s not really important.
But it’s confusing nonetheless.
Or is this just wrong on the Kaggle site, since they also use “log” in the formula?
I found another page that helped clarify at Kaggle: https://www.kaggle.com/wiki/LogLoss
I plugged in their N=6 example in a spreadsheet, and I needed to use “ln” instead of “log” to get their answer of ~ 1.88179
In the video for lesson 2 at 32:32, Jeremy is using Excel’s log() function when he should actually be using ln().
However, in Python math.log() is exactly what we want, since it’s the natural logarithm, while math.log10() is the base 10 logarithm.