I have trained a basic classifier model in fastai using a resnet50 model.
I have freezed the model body and set all the batchnorm layers in the body to not update the batchnorm params by iterating over all the params and setting the module’s requires_grad to False.
for module in learn5.model.modules():
if isinstance(module, nn.BatchNorm2d):
if hasattr(module, 'weight'):
module.weight.requires_grad_(False)
if hasattr(module, 'bias'):
module.bias.requires_grad_(False)
module.eval()
Then I trained the classifier and saved only model’s head using the following.
Now, during inference, I create the model by loading the body using create_body method of fastai and for the head I create it using create_head and load the model’s state_dict.
After comparing the weights of the two models, one by using load_state_dict and other by using load_learner, the two model’s parameters are exactly the same and yet when I do a forward pass, I obtain different results for the same input. I have attached the entire notebook below as an HTML file.
Comparison Notebook Link. Request you to download the notebook and view in browser (prefarably chrome).
Can someone please help me understand where might I be going wrong because of which this issue is coming?
I have not looked at your code in detail, but here are a couple of debugging suggestions:
Make sure that the BatchNorm running_mean and running_variance are equal between the two models, for both Head and Body. parameters() will not list these tensors for a BatchNorm layer, and they affect the forward pass.
Make sure that both models are fully in eval mode, Head and Body.
What a mystery! Please let us readers know what you discover.
I highly appreciate your very prompt reply. I did look at your first suggestion and it is indeed correct. I thought parameters lists running_mean and running_var but it supposedly doesn’t
How do I freeze these as well in my training? See what I am trying out is that having only the imagenet base body, if my head is trained to give decent performance on a classification task, I can minimize the storage requirement for my model. And in fastai I have observed that by freezing the body and only training the head, I am getting really good accuracy.
So, I would highly appreciate if you let me know how I can kind of freeze these and I hope that wouldn’t impact the fastai training loop…
Or could I only store the means and variances running and load them at inference time? I mean then boith the models will be completely identical I guess…
I am glad you found the source of the anomaly. BatchNorm can be difficult to work with. I once had to replace all the BatchNorms in a pretrained model with “myFixedBatchNorm”, because BatchNorm behaves badly with a batch size of 1.
In your case, the body is being altered during training even though you froze its weights and biases. To get the same results during inference, you would need to save the trained running means and variances and replace them in a fresh resnet. So I think your idea would work. If you want to spend the time to understand PyTorch code, you could probably get all the changed parameters into one state dictionary and load them at inference in one step.
Alternatively, you could try setting all the bnlayer.track_running_stats=False before training. The two bodies would be identical, but you would not get the same accuracy as when allowing the running stats to change. It might be good enough though.
One hacky way to do this is to get the state_dict() for the whole trained model and delete all the entries that were from the body, except for the running means and variances. That state dictionary can then be loaded into the fresh model used for inference.
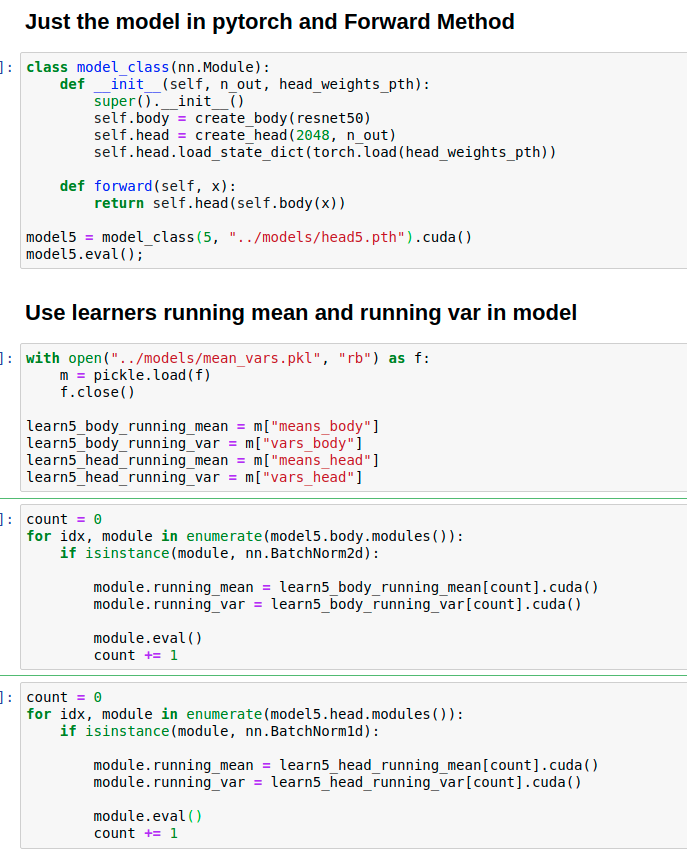
I am happy to say that your valuable suggestion was able to solve my problem. Basically I stored the running_mean and running_var tensors after training into a pickle file as follows
During inference, after loading the model, I made sure to set the running_mean and running_var variables for every BatchNorm module in both the head and body to the ones obtained when training as follows
After doing these changes, now I am able to save the model head and these running mean and running var stats iin around 10 MB instead of storing the entire model of 103 MBand get reasonably good accuracy. Thanks a lot for helping me out with my project. Really appreciate your input.
Glad to help. I understood the issue only because I had to struggle with BatchNorm’s details when it was used in a pretrained model that repairs damaged videos. I really appreciate that you narrowed down the issue and showed your code clearly. Those efforts make it much easier to give and receive help on the forums.