Hello. I’m working on an NLP project; I trained a language model on approximately 1600 of my own journal entries.
I want to now train and test a classifier on a subset of those 1600 entries (to be specific, 140, as I only classified 140 of them). I tried creating my data bunch using the following code:

where realdf is a dataframe with columns for entry and label; it contains all 1600 entries, but only the first 140 have labels, while the rest have the label “none.” However, when I run the following code to create the learner and load the encoder:

I get the following error:
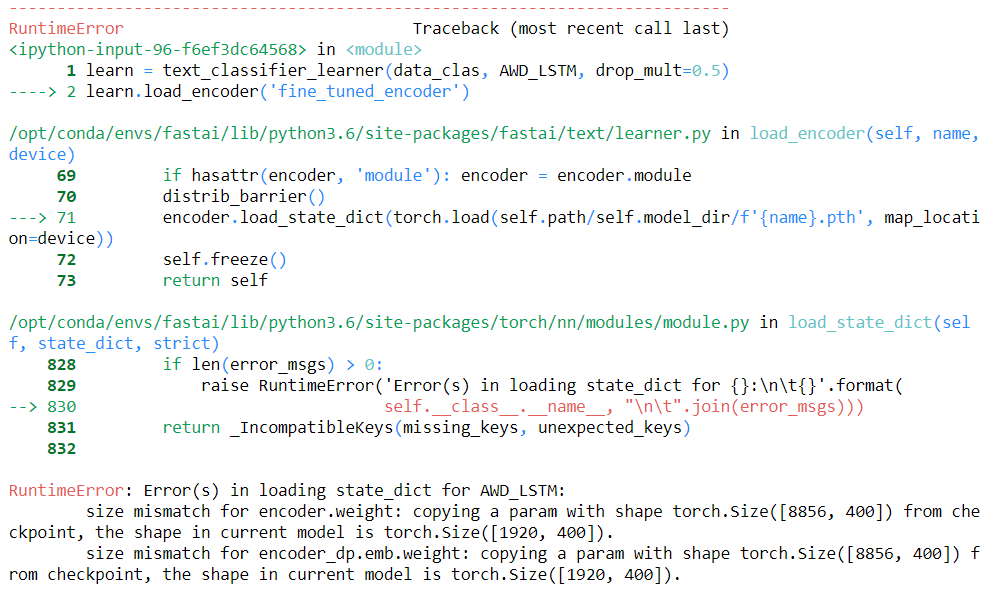
Which seems to indicate that the size of the train and validation set have to match that of the encoder (the language model and therefore encoder were trained on all 1600 entries.)
My plan is to train and test the classifier on the 140 entries that I manually classified, and then predict the class for the remaining 1400+ entries (with no way to validate/check since they don’t have labels, which is okay for the purposes of my project).
I thought that the add_test function would work since the test set is unlabeled anyways, but it doesn’t seem to be considering the test set for the size of the data.
Is there some way that I can get around the size mismatch error while still only using the 140 entries to train/validate the classifier?