Whoops! I just road-tested this with my brother creating a new Paperspace account, and discovered I’d left out a very important step to create /storage/cfg, so the ‘.local’ folder failed to move before it is deleted, and lost the jupyter keys, so unable to open notebooks. I edited above to fix this by adding mkdir -p /storage/cfg.
Awesome effort Daniel.
btw, at 10:29 should that be -p ~/conda ?
I think its useful to record the starting point of the environment, to make it easier to understand where I’ve made mistakes creating files and folders in the wrong place, and so help to know what can be blown away without breaking anything in the original environment.
So I went further back, and created a new account to redo this.
As a point of comparison, I first looked at a PyTorch instance…

$ ls /storage
was empty, and for the home directory…
$ ls -aF ~
.bashrc .cache/ .conda/ .config/ .ipython/ .jupyter/ .local/ .npm/ .pip/ .profile .wget-hsts
$ find ~
/root
/root/.profile
/root/.bashrc
/root/.local
/root/.local/share
/root/.local/share/jupyter
/root/.local/share/jupyter/nbextensions
/root/.local/share/jupyter/nbextensions/jupyter_tensorboard
/root/.local/share/jupyter/nbextensions/jupyter_tensorboard/style.css
/root/.local/share/jupyter/nbextensions/jupyter_tensorboard/tree.js
/root/.local/share/jupyter/nbextensions/jupyter_tensorboard/tensorboardlist.js
/root/.local/share/jupyter/runtime
/root/.local/share/jupyter/runtime/jpserver-1.json
/root/.local/share/jupyter/runtime/jupyter_cookie_secret
/root/.local/share/jupyter/runtime/jpserver-1-open.html
/root/.ipython
/root/.jupyter
/root/.jupyter/nbconfig
/root/.jupyter/nbconfig/tree.json
/root/.jupyter/lab
/root/.jupyter/lab/workspaces
/root/.jupyter/lab/workspaces/default-37a8.jupyterlab-workspace
/root/.pip
/root/.pip/pip.conf
/root/.config
/root/.config/pip
/root/.config/pip/pip.conf
/root/.cache
/root/.cache/pip
/root/.cache/pip/http/......
/root/.cache/pip/selfcheck/.......
/root/.conda
/root/.conda/environments.txt
/root/.npm
/root/.npm/_update-notifier-last-checked
/root/.wget-hsts
$ cat /root/.conda/environments.txt
/opt/conda
Then I had a look at Fast.ai instance…

For the very first login I see…
$ find /storage
/storage
/storage/data
/storage/data/*
That last entry is strange, which would only happen if the datasets folder was empty when
ln -s /datasets/fastai/* /storage/data/ is executed in /run.sh.
After a second login I see…
$ find /storage
/storage
/storage/data
/storage/data/biwi_head_pose
/storage/data/camvid
/storage/data/imagenette2-160
/storage/data/oxford-iiit-pet
/storage/data/imagenette2
/storage/data/*
/storage/data/cifar10
/storage/data/imdb
/storage/data/pascal_2007
/storage/data/mnist_png
So perhaps the first time there was a race condition with mounting the contents of /datasets/fastai and linking from there. A more precise command would be…
find /datasets/fastai/ -mindepth 1 -maxdepth 1 -exec ln -sf {} /storage/data/ \;
but btw, I wonder why its beneficial to link them and not use them direct from ‘/datasets’?
For the fast.ai home directory…
$ ls -aF ~
.bashrc .cache/ .fastai/ .jupyter/ .local/ .profile
$ find ~
/root
/root/.profile
/root/.bashrc
/root/.local
/root/.local/share
/root/.local/share/jupyter
/root/.local/share/jupyter/runtime
/root/.local/share/jupyter/runtime/jpserver-37.json
/root/.local/share/jupyter/runtime/jpserver-37-open.html
/root/.local/share/jupyter/runtime/jupyter_cookie_secret
/root/.viminfo
/root/.jupyter
/root/.jupyter/lab
/root/.jupyter/lab/workspaces
/root/.jupyter/lab/workspaces/default-37a8.jupyterlab-workspace
/root/.fastai
/root/.fastai/config.ini
/root/.cache
/root/.cache/pip
/root/.cache/pip/http/......
/root/.cache/pip/selfcheck/......
/root/.cache/pip/wheels/......
[EDIT]:
Is there any issue with all of .cache/ .fastai/ .jupyter/ .local/
being linked to persistant storage/cfg ?
The jupyter secret is lost if ~/.local/ is removed before copying it to /storage/cfg/.local/. That happened to me and the JupterLab GUI wouldn’t open notebooks from file list. I had to disable execution of pre-run.sh to recover the keys. It seems safer to move it (if it hasn’t already been) before overwriting with the link.
Hopefully that makes sense in light of my response to Mike.
In [Walkthru 6 at 8:45] a “~/conda” directory is created on Paperspace, so not a “dot-folder”, but its shown as a dot-folder in [Walkthru 7 at 13:50] on Jeremy’s local machine. The latter seems more consistent with other config folders. Is there a particular reason to do the former, apart from visibility to faciliate learning?
No, in hindsight I think I should have used a dot-name.
1 Like
At [11:54] micromamba is utilised from /storage/prev/micromamba. At [23:22] it very briefly refers to how to install it, but doesn’t actually action those steps (is this done in a walkthru?) So I’ve done that, adapted to run out of my ~/.conda folder using the tar “-C” flag, after emptying my .conda folder to ensure I’m starting from scratch…
$ ls -la ~/.conda/
lrwxrwxrwx 1 root root 19 Jun 19 09:28 .conda -> /storage/cfg/.conda
$ rm -rf /storage/cfg/.conda/*
$ curl -Ls https://micro.mamba.pm/api/micromamba/linux-64/latest | tar -C ~/.conda -xvj bin/micromamba
Then I tried installing ctags and got an error…
$ echo $PATH # previously set in pre-run.sh
/root/.local/bin:/root/.conda/bin:/opt/conda/condabin:/opt/conda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
$ micromamba --yes -p ~/.conda install universal-ctags -c conda-forge
error libmamba Expected environment not found at prefix: /storage/cfg/.conda
In the walkthru conda had been run previously, so I presume that may have done some environment setup, whereas here I’m starting with a blank slate. So I performed the additional init steps detailed in the install instructions…
$ ~/.conda/bin/micromamba shell init -s bash -p ~/.conda
Modifiying RC file "/root/.bashrc"
Generating config for root prefix "/storage/cfg/.conda"
Setting mamba executable to: "/storage/cfg/.conda/bin/micromamba"
Adding (or replacing) the following in your "/root/.bashrc" file
# >>> mamba initialize >>>
# !! Contents within this block are managed by 'mamba init' !!
export MAMBA_EXE="/storage/cfg/.conda/bin/micromamba";
export MAMBA_ROOT_PREFIX="/storage/cfg/.conda";
__mamba_setup="$('/storage/cfg/.conda/bin/micromamba' shell hook --shell bash --prefix '/storage/cfg/.conda' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__mamba_setup"
else
if [ -f "/storage/cfg/.conda/etc/profile.d/micromamba.sh" ]; then
. "/storage/cfg/.conda/etc/profile.d/micromamba.sh"
else
export PATH="/storage/cfg/.conda/bin:$PATH" # extra space after export prevents interference from conda init
fi
fi
unset __mamba_setup
# <<< mamba initialize <<<
!!! That change to .bashrc will be blown away next restart of the instance, so should I copy it to pre-run.sh, or maybe link .bashrc into /storage/cfg ?
and then continuing…
$ source ~/.bashrc
$ micromamba activate
(base) $ micromamba --yes -p ~/.conda install universal-ctags -c conda-forge
(base) $ ctags --version
Universal Ctags 5.9.0, Copyright (C) 2015-2022 Universal Ctags Team
Universal Ctags is derived from Exuberant Ctags.
Exuberant Ctags 5.8, Copyright (C) 1996-2009 Darren Hiebert
Compiled: Jun 19 2022, 04:30:13
So thats good ctags is installed and runnable.
But looking at the space taken, 399MB is bigger than expected compared to the walkthru…
$ cd /storage/cfg/.conda
$ du -sh .
399MB
$ du -sh *
(base) root@nakf6utbos:/storage/cfg/.conda# du -sh * | sort -hr
321M pkgs
55M lib
18M bin
5.4M include
232K conda-meta
16K share
3.5K etc
$ du -sh pkgs/* | sort -hr | head
295M pkgs/cache
42M pkgs/icu-70.1-h27087fc_0
14M pkgs/icu-70.1-h27087fc_0.tar.bz2
12M pkgs/libstdcxx-ng-12.1.0-ha89aaad_16
4.3M pkgs/libstdcxx-ng-12.1.0-ha89aaad_16.tar.bz2
2.5M pkgs/libgcc-ng-12.1.0-h8d9b700_16
2.4M pkgs/universal-ctags-5.9.20220619.0-h373f2ac_0
2.4M pkgs/libiconv-1.16-h516909a_0
2.3M pkgs/libxml2-2.9.14-h22db469_0
1.4M pkgs/libiconv-1.16-h516909a_0.tar.bz2
$ du -sh pkgs/cache/* | sort -hr | head
186M pkgs/cache/497deca9.json
58M pkgs/cache/09cdf8bf.json
38M pkgs/cache/497deca9.solv
13M pkgs/cache/09cdf8bf.solv
$ bzip2 -c /root/.conda/pkgs/cache/497deca9.json > /tmp/x
$ du -sh /tmp/x
20M /tmp/x
So the json cache files seem the most problematic. Is there anything that can be done with them?
Is there anything that can be streamlined overall in the above procedure?
You don’t want any of these steps. It’ll get in the way of your paperspace python install. I suggest removing them all. I can’t quite remember what we did in the video to get the conda folder working, but I think all the steps (except downloading micromamba) must be there since I didn’t do anything outside the video.
In the video you do…
[12:50] $ conda install -p ~/conda -c conda-forge mamba
[13:27] $ /storage/prev/micromamba -p ~/conda install -c conda-forge universal-ctags
So it works if I similarly do…
1 $ rm -rf ~/.conda/*
2 $ conda install -p ~/.conda -c conda-forge mamba
3 $ curl -Ls https://micro.mamba.pm/api/micromamba/linux-64/latest | tar -C ~/.conda -xvj bin/micromamba
4 $ micromamba -p ~/.conda install universal-ctags -c conda-forge
5 $ which ctags
/root/.conda/bin/ctags
but it doesn’t work if I leave out step 2, whereas I thought the ideal we were aiming for was to run only micromamba.
[EDIT:]
Alternatively, for minimal storage, why not just…
$ rm -rf ~/.conda/*
$ conda install -p ~/.conda -c conda-forge universal-ctags
$ which ctags
/root/.conda/bin/ctags
$ du -sh ~/.conda/* | sort -hr
55M .conda/lib
5.4M .conda/include
3.2M .conda/bin
1.4M .conda/share
204K .conda/conda-meta
512 .conda/environments.txt
1 Like
Yes I think that’s a good way. Or do the shell init thing, but don’t add the bashrc stuff to be part of your persistent login script.
I have been trying to take notes (or to document it properly) on source code/docs exploration like what Jeremy started doing in walkthru 6. I think there is a way to do it all in jupyter notebook that works ok for me. If you like documenting these kind of exploration process, read below please.
I first tried to redo Jeremy’s demo on how to walk through fastai/fastai/ repo to understand the meaning of from fastai.vision.all import * and how to understand the usage of untar_data all in a jupyter notebook video start 48:13
Since I didn’t have much questions about this exploration, so the documenting work is kind of smooth.
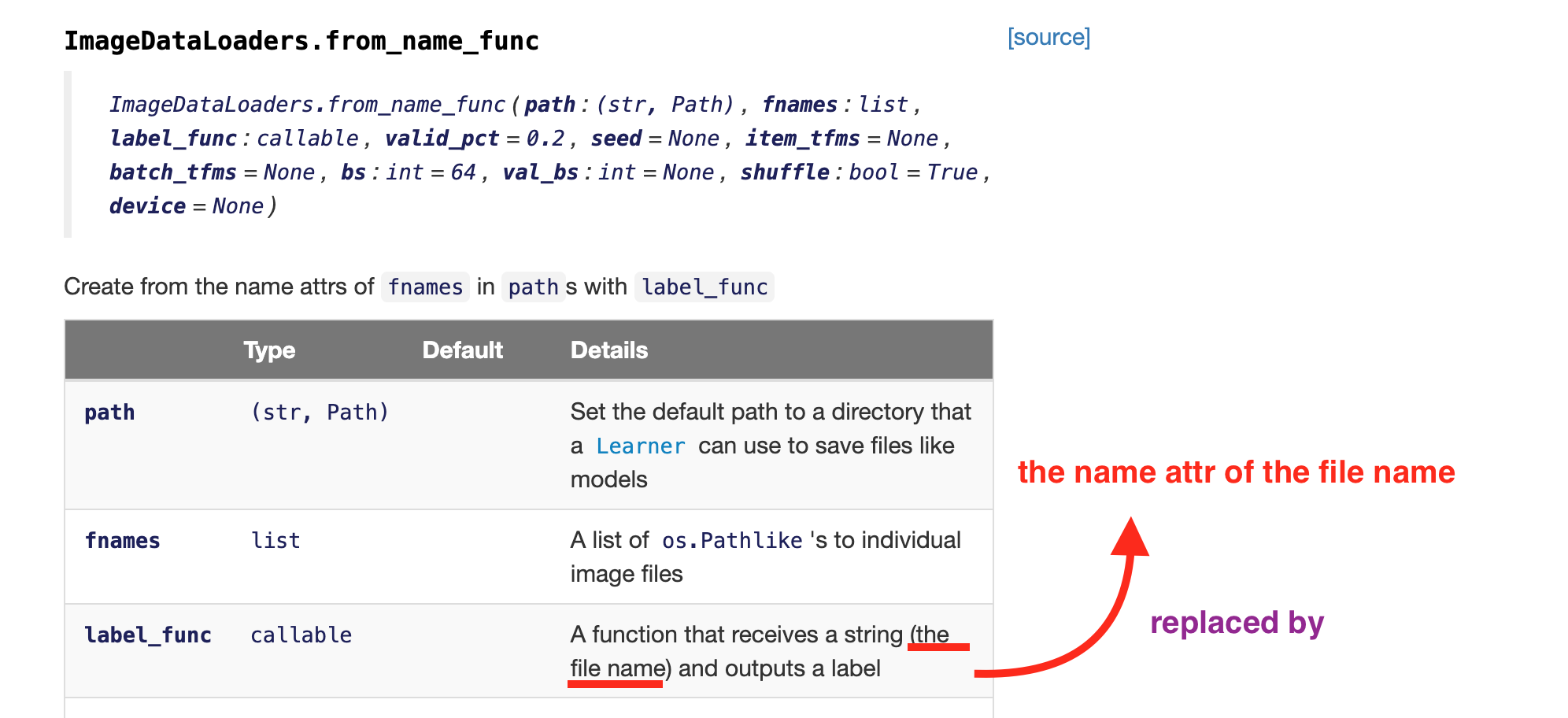
And then I moved onto understanding the use of ImageDataLoaders.from_name_func (video start 1:02:58 ), and I did have a number of questions on how to use it, so it took a long time for me to sort things out and I think this documenting process saved me from giving up and eventually reached the most of answers on my own (if you read the notebook, please correct me if I am wrong on those answers).
However, I couldn’t find anything online introducing this particular name attr specifics of PETS data. If I didn’t do this exploration documenting work, I would never find out that all the cats filenames have the cat breed name first letter upper case, and dog files have the first letter of breed name lower case.
One more thing, shouldn’t the following change be more accurate?
1 Like
The fast.ai datasets are documented here:
https://course.fast.ai/datasets
That includes a link to the paper, where the full details are provided.
2 Likes
If I understand correctly, we ought to install micromamba instead of mamba in the .conda folder, right?
You don’t really need to install anything now since there’s a complete ready-to-go setup nowadays:
But if you’re doing it from scratch, yes just download micromamba.
2 Likes
Thanks! I did not know that this exists. Was this created in the later session of the live coding?
Yup created towards the end of this series.
I wrote a blog on live coding 6. I noticed Paperspace has mamba available now. So, there’s no need to download micromamba anymore. I covered how I installed ctags, setup bash_history persistently, gitconfig, and some fastbook.
2 Likes
This has saved me a lot with micromamba stuff
I watched all 5 previous live coding and at the sixth session, I faced this problem when I am trying to run clean intro notebook, and it’s stuck in this step. I’m currently using gradient notebook free cpu (because I can’t not using the gpu one), and I am wondering is it the root of my problem?

If that so, is any alternative way for me to complete this course?
Hi, this happened to me, too when I used the CPU instead of GPU.
It depends on what you want to do.
There is free GPU available time to time on Paperspace.
However, its availability is limited, so you may consider subscribing to Paperspace.
If you’re on a budget and want to choose other free options, you can use google colab or kaggle notebook to utilize their free GPU. But, these options do not provide you with environment like persistent storage like Paperspace.
Hopefully this helps.