You can create an file with touch .bash_history and just use that. Or open a terminal, type one command, close the terminal, then reopen, and the history will be there.
Congrats on getting set up!
You can create an file with touch .bash_history and just use that. Or open a terminal, type one command, close the terminal, then reopen, and the history will be there.
Congrats on getting set up!
EDITED: Managed to get bash-history working across machines.
If I create a .bash_history via touch, move it to storage/cfg, symlink it back, then it all works, even on a new machine
Thanx Jeremy.
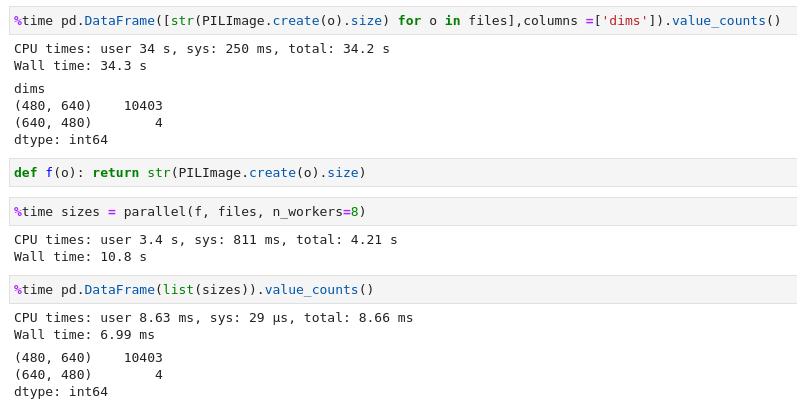
Thanks @jeremy for covering it in walkthru#8. fastcore parallel (with 8 workers) is over 10 times faster for counting unique sizes of images in the whole dataset.
Appreciate your time and awesome explanation.
This is interesting. I have an old Xeon desktop which is 8cores/16t cpu, but I saw improvements with n_workers=4 and doubling it to 8 or even 16 showed not much of an improvement.
I guess it depends on the type of CPU? but for me, the lesson was: YMMV ![]()
I also can’t see much difference beyond 8 workers. The task or the system might be the reason, I guess.
Yeah I was thinking that it is connected to the amount of data. For this given dataset size, anything above 4 workers doesn’t add much value. In your screenshot the single threaded “sys time” was 250ms which increased to 800ms with 4 workers (which I think is the overhead in terms of sending data to 4 cores). In my case it seems after 4 workers which gave me a good 8x speedup, anything beyond that increased the system overhead but did not add more value (if anything it seems to have degraded a bit.)
A rough but detailed note on walkthru 6
00:00
03:25 What will be there in your notebook when you come back next time? stuff in the notebooks/ if you open the same machine or storage/
04:03 How to make storing stuff more flexible? use pre_run.sh, .ssh, .local to save into storage/
04:35 How to pip install to make sure all libraries are ready when we come back to the same machine or a different one?
05:01
06:25 How to install ctag with mamba
What it is about -p?
Where (or how) does the fastai folder come from?
08:06 How to toggle side bar? cmd/ctrl + b
08:27 Create a folder named conda cd; ls; mkdir conda;
mamba and ctags
10:29 Do we have mamba when we start a machine? no, try mamba
Can we install ctag with conda using conda install -p ~/conda mamba? and Why? No, must use conda install -p /conda -c conda-forge mamba
10:31 Why the installation solution above does not work as we expected?
11:47 Where is the micromamba? How to install ctags with micromamba? cd; /storage/prev/micromamba -p ~/conda install universal-ctags
12:34 Does this approach above work? Why?
12:51 Plan to keep what we need and remove the others from conda install -p /conda -c conda-forge mamba but not working
13:54 Try /storage/prev/micromamba -p ~/conda install -c conda-forge universal-ctags does it work? yes
How much stuff does it store after installing into /conda? a lot see cd conda; ls;
How much space does it take? How to get a summary of the disc space of this directory? cd conda; du -sh *
15:00 What stuff takes up nearly 300MB in the /conda folder?
How to see the space distribution inside /lib? du -sh lib/*
How to only see the items take up more than 1 MB? du -sh lib/* | grep 'M'
What does | grep 'M' do here? take the output from the left command and search with ‘M’
How to remove the largest files? conda/lib# rm -rf python3.1* libpython3.*
How to move files out of the way without delete them? conda/lib mv fileName otherDirectory
ctags we just installed?18:02
Why we can’t use mamba?
Why we can’t use ctags the way we wanted? paperspace has an old and emacs version of ctags which is not the one we wanted. see it from ctags --version
Why we can’t find the mamba and the right ctags? use echo $PATH to show where paperspace find libraries to run
Where did we install and store the libraries we want to use? conda/bin and with ~/conda# ls bin/ we can see mamba and ctags are stored there
How to run ctags from /bin/? ~/conda# bin/ctags --version
It turned out a moved file is needed to run ctags, so how to bring the file back into lib/? ~/conda# mv theFileNeeded lib/
now ~/conda# bin/ctags --version works
19:55 How to make conda/ into $PATH?
How to make sure things are in the $PATH when we run things in the terminal? We need to create a .bashrc.local inside /storage/ to put /conda into $PATH
20:36 What to write inside .bashrc.local? we want to run this script in bash to export a variable named PATH which has a new string ~/conda/bin along with other strings already exist in $PATH
#!usr/bin/env bash export PATH=~/conda/bin:$PATH
run.sh read .bash.local not .bashrc.local
21:18 If we open a new terminal, how to see whether the new path string is added into $PATH or not?~/notebooks# echo $PATH
If not automatically working, how to manually make it to work? ~/notebooks# source /storage/.bashrc.local and then root/conda/bin appears in the $PATH, it works
Why .bashrc.local is not automatically run when a new terminal is running? because run.sh does not run .bashrc.local but .bash.local. We got the filename wrong
How to easily change a file’s name? mv .bashrc.local .bash.local or mv !$ .bash.local
Does it work now? open a new terminal, cd to go to root, echo $PATH, and we can see root/conda/bin:
now from root we can run ctags --version we have the right one
Why we still can’t use mamba? (maybe because we have not yet successfully installed mamba in the first place, even though it is shown in conda/bin/)
23:26 How to install micromamba? it is to download from the web, the process is not shown
How to move micromamba from /storage/prev/micromamba to conda/bin? mv /storage/prev/micromamba conda/bin and rm conda/bin/mamba
Now check to see how much space does conda take? ~# du -sh conda and got 175MB
conda/ is ready next time we come back24:27 How to make sure next time we have the exact functioning /conda to use?
How to move /conda into /storage? mv conda /storage
How to symlink /storage/conda back to root? vim pre_run.sh and add ln -s /storage/conda
Then can you check whether the symlink is done? ls -la when next time pre_run.sh is run
25:19 How to ensure we can use ctrl + r and arrows to retrive previous bash commands?
How move .bash_history to /storage? mv .bash_history /storage/
How to copy, paste and edit another two lines into pre_run.sh in vim? 2 + shift + y to copy 2 lines, p to paste two lines above the copied lines, shift + w to move forward by words (faster than w), and shift + c to delete rest of the line and enter edit mode to write .bash_history, and to repeat the last step where the cursor is, just type .
What is the updated pre_run.sh?
pushd ~
#!/usr/bin/env bash
cd
rm -f .bash_history
ln -s /storage/cfg/.bash_history
ln -s /storage/conda
rm -rf .local
ln -s /storage/cfg/.local
rm -rf .ssh
ln -s /storage/cfg/.ssh
popd
30:52 How to make sure ctags and command history work on a new notebook/machine?
Let’s close and reopen the same notebook to see whether everything work as expected? try ctags --version and history to see whether we got them right, and save commands across different machines
32:03 How to remove everything in the notebook directory? Is it safe? rm -rf *
32:31 Intro another great alumni, and be ready to start on chap 1 of fastbook
34:20 How to git clone fastbook properly? 1. fork the book; 2. Fetch upstream when the master version update; 3. git clone the SSH link in the notebooks/ folder
39:40 When you should download all the history version of fastbook instead of the latest version? when we need to make changes
40:28 How to make changes and push it all the way to the master version of fastbook? 1. make changes and remember to save it cmd/ctrl + s; 2. ls; git status to see the changes; 3. git commit -am 'test making a change' to do git add and git commit in one step; 4. to commit properly, we need to set up .gitconfig about who are you in terms of github account (see the question and answer below)
42:34 How to store your github identity (who am I) to persistence storage? 1. set git email and name git config --global user.email 'youremail@host' git config --global user.name 'yourname'; 2. check the hidden files in root/ with /fastbook# ls -a ~ to see the existence of .gitconfig file; 3. check what inside the file with /fastbook# cat ~/.gitconfig; 4. move this file into storage folder mv ~/.gitconfig /storage/; 5. add gitconfig symlink back to notebook inside pre_run.sh: cd; vim /storage/pre_run.sh; add ln -s /storage/.gitconfig/; 6. now the updated pre_run.sh is the following
pushd ~
#!/usr/bin/env bash
cd
rm -f .bash_history
ln -s /storage/cfg/.bash_history
ln -s /storage/conda
rm -rf .local
ln -s /storage/cfg/.local
rm -rf .ssh
ln -s /storage/cfg/.ssh
ln -s /storage/.gitconfig
popd
ln -s /storage/.gitconfig; 8. get back to previous directory type cd ~, and then do the git add and commit without a problem44:43 How to push the changes to the remote server/github? 1. use git status to check whether commit is done properly; 2. git push to push to the cloud; 3. go back to the github fork to see your version is 1 commit ahead from master version; 4. click contribute and click open pull request, and then check the changes and click create pull request to send request to the developer on their master version; 5. go to master fastbook repo to check the list of pull requests; 6 click the specific pull request you want to see, and click ReviewNB to see the readable and graphical format.
47:04 How to use Nbdime on paperspace to view the saved changes on your jupyter notebook? click the git button to view the difference in ReviewNB style
48:13 How to dive into the source code? 1. cd ../fastai; to go to fastai repo directory; 2. ls fastai to check what inside the fastai library folder; 3. we can see there is a subfolder called vision, this is where fastai.vision come from when we do from fastai.vision.all import *; 4. cd fastai/vision; ls; to see all files inside fastai/vision and we see the file all.py which is where from fastai.vision.all from; 5. vim all.py to see what inside the file; 6. what does the .augment from from .augment import * mean? It means there is a augment.py file inside vision folder; 7. in vim :sp augment.py to see both all.py and augment.py in splitted windows; 8. what does * from from augment import * mean? It means import everything from augment.py and everything means everything inside __all__ (dunda all) which is a list of classes and methods to be exported from augment.py; 9. how to quickly move to the next occurence of the class/function RandTransform? move cursor on the word, and use shift + 8 or *; 10. if there is no dunda all __all__, then from augment import * means to import all classes and methods that are defined or imported from elsewhere; 11. to prove RandTransform is available to us, type RandTran and hit tab to see it autocompleted; 12. How to find where a class or function such as RandTransform is from inside jupyter notebook? just type it out and shift + enter, the cell will output its address; 13. How to know more of a class or function? type functionClassName? and shift + enter, you can find the file address you can use in :sp theExactFileAddress to see it in vim split views; 14. if you just want to see the source code of a particular class or function, just type classFunctionName??;
54:57 15. how to display the docs of a class or function? type doc(classFunctionName) in a cell;
56:11 How to dissect and analyse a function? 1. use ctrl + shift + ~ to split a cell into two cells by the location of cursor; 2. run each cell to check what is the result and effects; 3. Where is the dataset downloaded into? path shows the dataset is stored in persistence storage; 4. How to find out how much space does this dataset take? cd datasetDirectory; du -sh .; to see the size, and you can move the dataset to home directory to save money on persistence storage;
58:06 The untar_data docs tell us the dataset is to stored in ~/.fastai, but why it is actually stored inside /storage/? 1. since untar_data is a wrapper on FastDownload.get, we should dive into its source code; 2. we can google FastDownload to read its docs; 3. the docs tells us that FastDownload will download dataset into a base directory with archive and data two subfolders, untar_data uses .fastai folder as base directory; 4. the docs also says if there is a config.ini file inside the base directory now .fastai folder, then the archive and data will be named according to the config.ini file; 5. when we cat ~/.fastai/config.ini, we see that archive is set to be /storage/archive and data by /storage/data; 6. Who created this config.ini? Paperspace;
59:32 How an we adjust and symlink this config.ini file from persistence storage? 1. mv config.ini /storage/; 2. inside pre_run.sh how to make a folder with parent folders: mkdir -p ~/.fastai to create .fastai folder and its parent folders (if not exist); 3. rm -f ./fastai/config.ini to remove the existing config.ini; 4. ln -s /storage/.fastai/config.ini .fastai/ to symlink the config.ini back to ~/.fastai not home folder itself; 5. don’t remember to run ln -s /storage/.fastai/config.ini .fastai/ directly in terminal to set the symlink for this running notebook for this time only; 6. What is the updated pre_run.sh look like
pushd ~
#!/usr/bin/env bash
cd
rm -f .bash_history
ln -s /storage/cfg/.bash_history
ln -s /storage/conda
rm -rf .local
ln -s /storage/cfg/.local
rm -rf .ssh
ln -s /storage/cfg/.ssh
ln -s /storage/.gitconfig
mkdir -p ~/.fastai
rm -f ./fastai/config.ini
ln -s /storage/.fastai/config.ini .fastai/
popd
1:00:51 How to quick paste your previous typed word without selection and cmd/ctrl + c; cmd/ctrl + v;? if your last type was .fastai, then just ctrl + p to paste that again to where your cursor is.
1:02:09 How to adjust config.ini to save persistence storage? we don’t want archive folder to be stored inside persistence storage, so remove the line on archive and the updated config.ini is the following
[DEFAULT]
model = /storage/models/
data = /storage/data/
storage = /storage/data/
How to quickly move up to the immediate parent directory? cd ..
1:02:58 How to quickly get to know ImageDataLoaders and its function from_name_func? 1. type doc(ImageDataLoaders.from_name_func) to get its documentation url link, so read it; 2. go back into the cell where ImageDataLoader.from_name_func is used, put cursor on the function and hit shift + tab to find the parameters of the function; 3. go back to the docs to see each of the parameters do, from there click further into further function docs if necessary
1:05:15 How to dissect and explore a small function get_image_files used as a parameter inside the main target function we are learning such as ImageDataLoaders.from_name_func? 1. copy and paste the small function usage files = get_image_flies(path) into a separate new cell; 2. run the cell to check out what is inside files; 3. how to make the list-like files more like a list? list(files)[:10];
1:06:15 How to make Path more readable by removing the base path? Path.Base_Path = Path('/storage/data/oxford-iiit-pet') and run files again to see all paths without the base path address.
1:07:08 why files does note behave like a list? or What exactly is the type of files? run type(files) to see the class of this function fastcore.foundation.L;
1:07:08 What is fastcore.foundation.L? How to find out more of L? 1. we can try files?; 2. also try help(L) to see the list of methods or functions of L; 3. try doc(L) to see the documentation of L online which have the most info about it
1:08:32 How to explore and experiment on the usage of L using the documentation in jupyter notebook: 1. how to create and play with a normal list? a = [1,2,3]; a[:2];; 2. how to create a L list? b = L(1,2,3); b[:2]; which can do the same thing as a normal list; 3. why use L instead of list in python? because it has a lot more useful functions than list in python; 4. can L do list in numpy array like c = array([1,2,3]); c[(0,2)]; too? yes, b[(0, 2)] to access the first and 3rd items of a list in one go; 5. why not just use numpy array rather than L? because numpy require everything to be in the same data type as it is designed for math, you can do b + "hello" for L, but not c + "hello" in numpy, but c + 5 can do element wise calculation;
This is amazing detail! Thank you @Daniel !!
You are welcome. Glad it is useful to you.
So much treasures in part1 lectures and all these walkthru sessions, hope these detailed notes can make the search easier.
Hi Radek, thanks for the script, this way we don’t need micromamba, right? Also could you elaborate on meaning of the two occurrences of ‘EOT’ in the script? thanks
Hi Daniel, Radek can explain the details when he sees it but this things is called a “Here document” in Unix terms. These are usually used when you want to write a bunch of lines to a text file. So, instead of writing 20 “echo” lines with escape sequences for each line which is a pain to edit if you need to make changes, you just use the ‘Here document’ and put whatever you want between the ‘EOT’ (or \EOT) marker in the first line and the EOT marker by itself at the end of your stuff.
Take a look at this: Here Documents
Hi radek, do you mean that whenever Jeremy uses micromamba we can use mamba instead, for example to install unzip in walkthru 7 Jeremy had to use micromamba, we now can use mamba install -c conda-forge -p ~/conda unzip to install unzip.
You could, but I don’t recommend it, since it uses a lot more space and ends up with a dupe copy of python in your homedir.
Instead I’d suggest using micromamba.
There is a trade off between number of workers and the communication to run them that hinders the progress. Sorry a bit vague I know
Just recording what the default Paperspace home folder looks like before any pre-run.sh customisation:
~# pwd
/root
~# ls -la
total 28
drwx------ 1 root root 4096 Jun 15 23:20 .
drwxr-xr-x 1 root root 4096 Jun 15 23:20 ..
-rw-r--r-- 1 root root 3220 May 9 20:53 .bashrc
drwxr-xr-x 1 root root 4096 Nov 12 2021 .cache
drwxr-xr-x 2 root root 4096 May 9 20:53 .fastai
drwxr-xr-x 3 root root 4096 Jun 15 23:20 .local
-rw-r--r-- 1 root root 148 Aug 17 2015 .profile
~# find .local
.local
.local/share
.local/share/jupyter
.local/share/jupyter/runtime
.local/share/jupyter/runtime/jpserver-36-open.html
.local/share/jupyter/runtime/jupyter_cookie_secret
.local/share/jupyter/runtime/jpserver-36.json
~# find .fastai
.fastai
.fastai/config.ini
~# du -sh .cache/*
411M .cache/pip
I’m seeking critical review of the pre-run.sh I’ve ended up with following walkthru 6. I noticed a lot of similar code, so I’ve tried to make it generic.
It is designed to be implemented before any manual action to move existing folders. If a user folder (like .local seen above) is missing from storage, it copies the user folder to storage before removing the user folder. The “mkdir -p” ensures a folder exists, and “touch” ensures a file exists.
The push/pop takes care of returning to /notebooks folder expected by jupyter.
#!/usr/bin/env bash
pushd ~
for dir in .local .ssh conda
do
[ ! -d /storage/cfg/$dir ] && mv $dir /storage/cfg/$dir
rm -rf $dir
mkdir -p /storage/cfg/$dir
ln -s /storage/cfg/$dir
done
chmod 700 /storage/cfg/.ssh
for file in .bash.history .git.config
do
rm -f $file
touch /storage/cfg/$file
ln -s /storage/cfg/$file
done
popd
It all looks fine to me, but I’d suggest removing that bit. I don’t really see how it helps.
My thinking was that we already have our “good configuration” in /storage/cfg and what we want to do is make that active. This is predicated on the fact that there has to have been a “configuration session” prior to this instance of paperspace machine coming into existence (a session in which we did all the jiggery pokery, and the .ssh , .local, and conda directories were created and stashed away in /storage/cfg/ )
So, by the time this pre-run.sh is executed as the new paperspace instance comes into being and wakes up, it should first of all get rid of all the stuff that exists in its current environment (the ~ or home directory) because we are going to use stuff we stashed away in /storage/cfg (the .local , .ssh and conda directories).
So, with that background, I don’t think we need to check if /storage/cfg/$dir (where dir in blah1 blah2 blah3) exists because if it doesn’t we have a bigger problem; which is that our configuration is lost and that is the baseline assumption. So, I think we don’t need lines 1 and 3 in the first loop. Just removing the directory in ~ and sym-linking the one from /storage/cfg/$dir to . ( current directory ) would suffice.
Similarly, in the second loop , touching the file ( touch /storage/cfg/$file ) would probably just update the time on that file because it already exists (and it should, from the time when the configuration was done and the file was stashed away in /storage/cfg/ before this instance came into being)
I like the fact that it’s using loops so, if there are more files they just need to be added to the list. We could probably just loop through two variables containing these dir names and file names, and set those at the top of the script, and it would make it easier to edit as it’d be closer to the top.
Hey Mike. Thanks for your great feedback.
Sorry I wasn’t clear in my aim, which is my script packs in all that jiggery pokery, so I don’t need to remember everything for a separate configuration session, and it might be useful to others starting a fresh Paperspace account (although of course, it reduces their practice with the walkthroughs.)
Regarding Line 1 of the loop, this really only needs to be done once, so perhaps I should have been more explicit…
#!/usr/bin/env bash
# Once only, manually run... pre-run.sh steup
# These are the directories and files moved to persistant storage
DIRS=" .local .ssh conda"
FILES=" .bash.history .git.config"
mkdir -p /storage/cfg
pushd ~
for dir in $DIRS
do
[ "$1" = "setup" ] && [ ! -d /storage/cfg/$dir ] && mv $dir /storage/cfg/$dir
mkdir -p /storage/cfg/$dir
rm -rf $dir
ln -s /storage/cfg/$dir
done
chmod 700 /storage/cfg/.ssh
for file in $FILES
do
[ "$1" = "setup" ] && [ ! -f /storage/cfg/$file ] && mv $file /storage/cfg/$file
touch /storage/cfg/$file
rm -f $file
ln -s /storage/cfg/$file
done
popd
Regarding Line 3 of the loop, consider the script may be run before ssh-keygen is run so there is no .ssh folder to move, and so no /storage/cfg/.ssh directory to link to. The mkdir -p ensures there is a directory to link, so that when ssh-keygen is first run, the keys are stored directly to /storage/cfg/.ssh.
The touch is similar to mkdir -p as a safety to ensure it exist before linking, covering the case in Walkthru8@1:22 where Jeremy explains how the .bash_history file doesn’t exist until terminal is closed, you can’t symlink to it until it exists.
Or an alternative grouping, I’m not sure if makes it clearer…
#!/usr/bin/env bash
# Once only, manually run... pre-run.sh steup
# These are the directories and files moved to persistant storage
DIRS=" .local .ssh conda"
FILES=" .bash.history .git.config"
mkdir -p /storage/cfg
pushd ~
if [ "$1" = "setup" ]
then
for dir in $DIRS
do
[ ! -d /storage/cfg/$dir ] && mv $dir /storage/cfg/$dir
mkdir -p /storage/cfg/$dir
done
chmod 700 /storage/cfg/.ssh
for file in $FILES
do
[ ! -f /storage/cfg/$file ] && mv $file /storage/cfg/$file
touch /storage/cfg/$file
done
fi
for x in $DIRS $FILES
do
rm -rf $x
ln -s /storage/cfg/$x
done
popd
Ah!!! Ok, this makes more sense now! I was not thinking that it’s part of a bigger piece of code that does the initial setup (conditionally) prior to that. And yes you’re right it makes sense for ‘touching’ that file for that edge case. Again, I was thinking of a previous session where all this would’ve been done and things stashed away (or created initially)
I know it’s personal preference, but I kinda like the 2nd version, and taking into account the setup option is a nice touch! I didn’t think of that. ![]()