Verify a warning message of fastai library through experiment in Excel
I have implemented weight_decay, l2_reg plus previously momentum_step and average_grad in Excel to prove a warning message (see below) from fastai doc
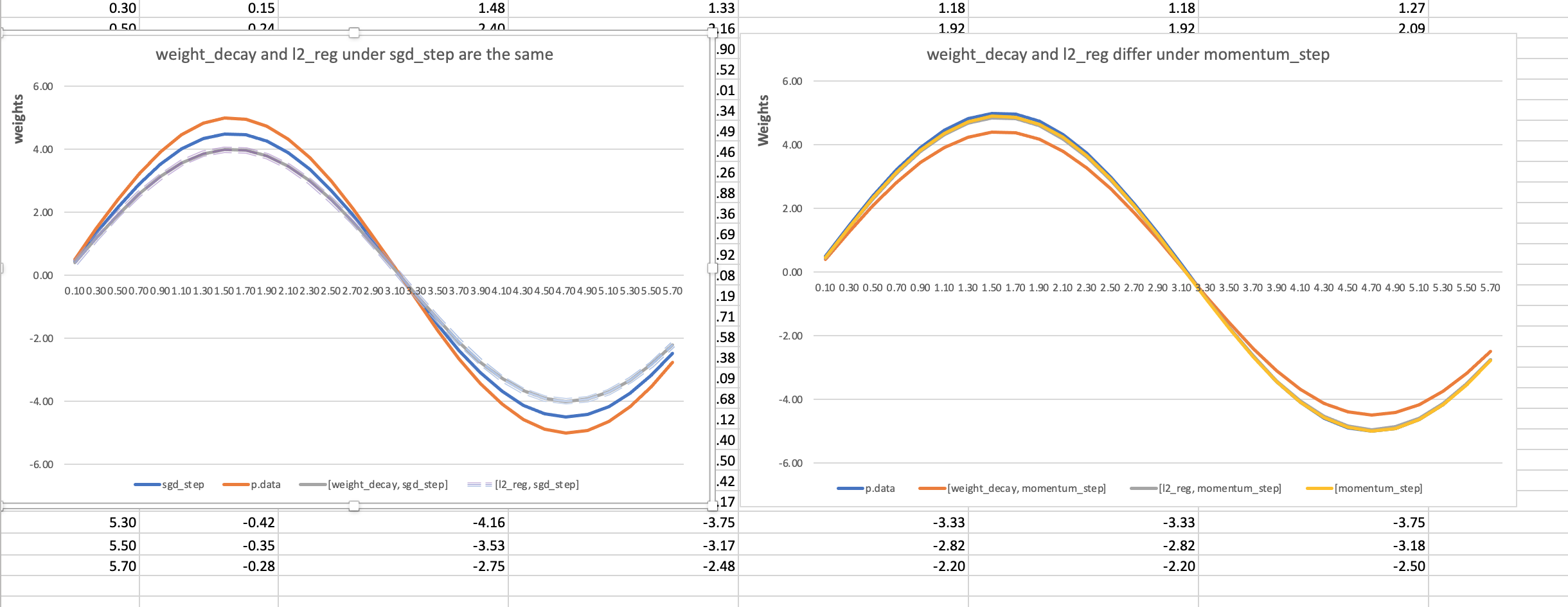
Here is the graph from the Excel experiment to prove the warning message above. The plot on the right shows that [weight_decay, momentum_step] is visually different from [l2_reg, momentum_step].
However, as you said this could be done in jupyter notebook. I suspect the calculation process could be less messy in jupyter notebook with python. Also using fastai in Jupyter notebook directly can verify the experiment of Excel.
Next steps:
I will try to make the experiment in Excel tidier and try to make it equivalent to fastai in python as much as possible. As for verification, I can simply compare the data generated by Excel and Jupyter notebook .