It is so intringing that one excel workbook can let you experiment on the foundations (forward, backward propogation or gradient descent) and essential techniques on improving gradient descent (e.g., momentum, Adam etc) of deep learning on a single neuron architecture (i.e., a simplest linear function y = a*x + b).
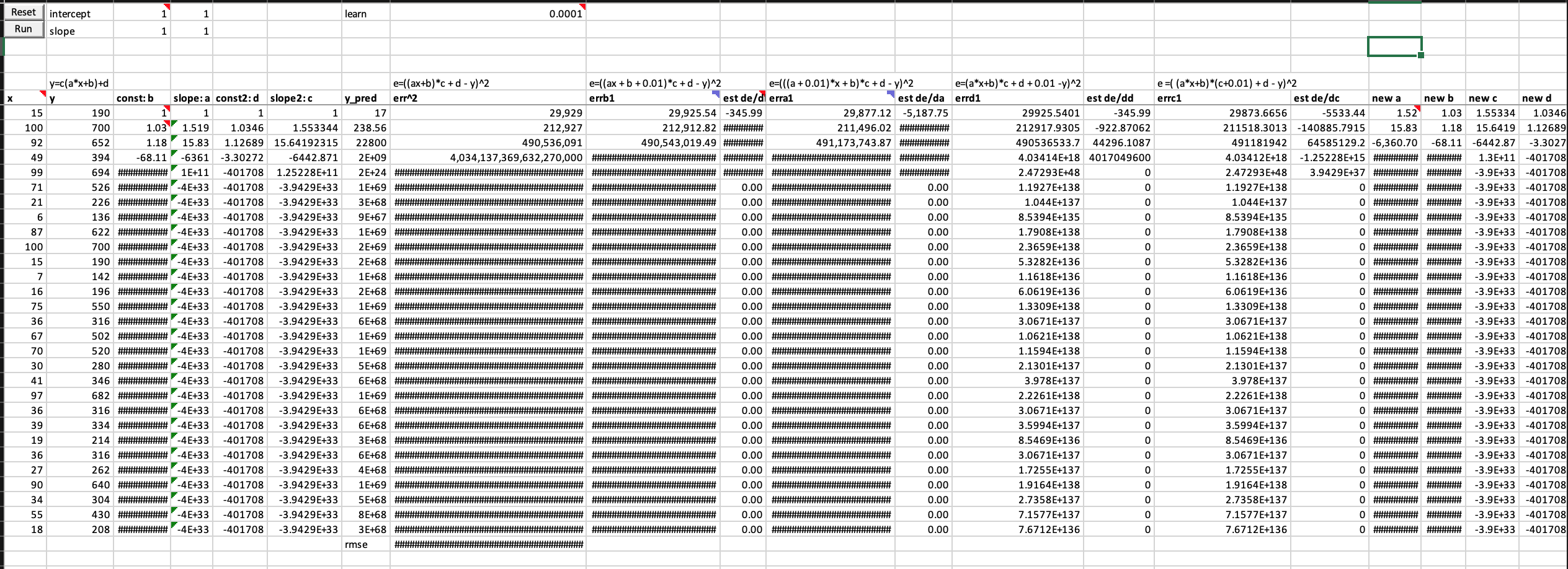
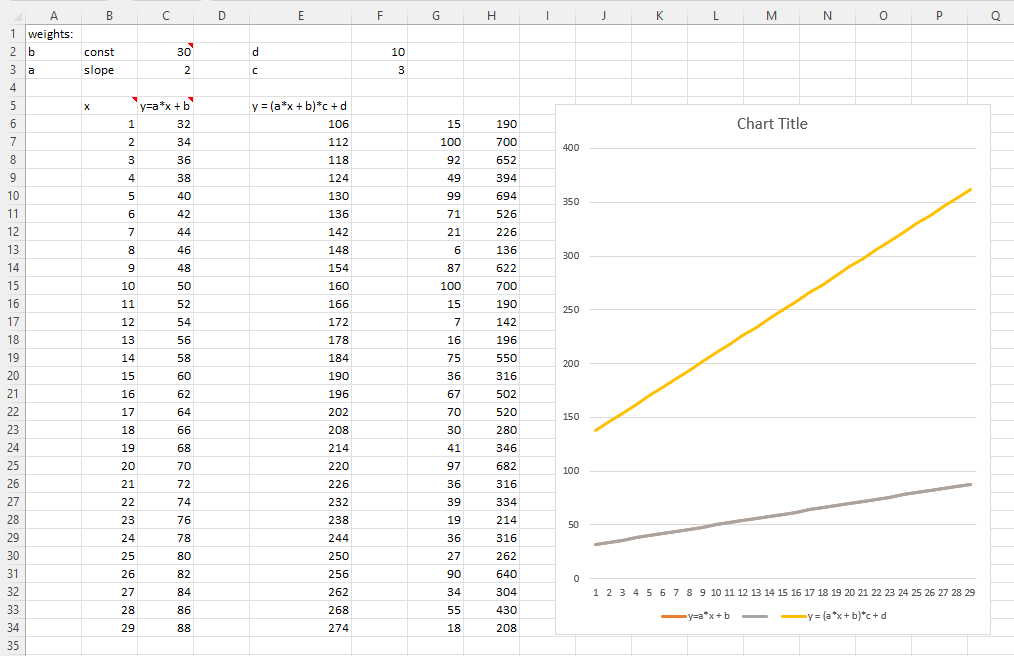
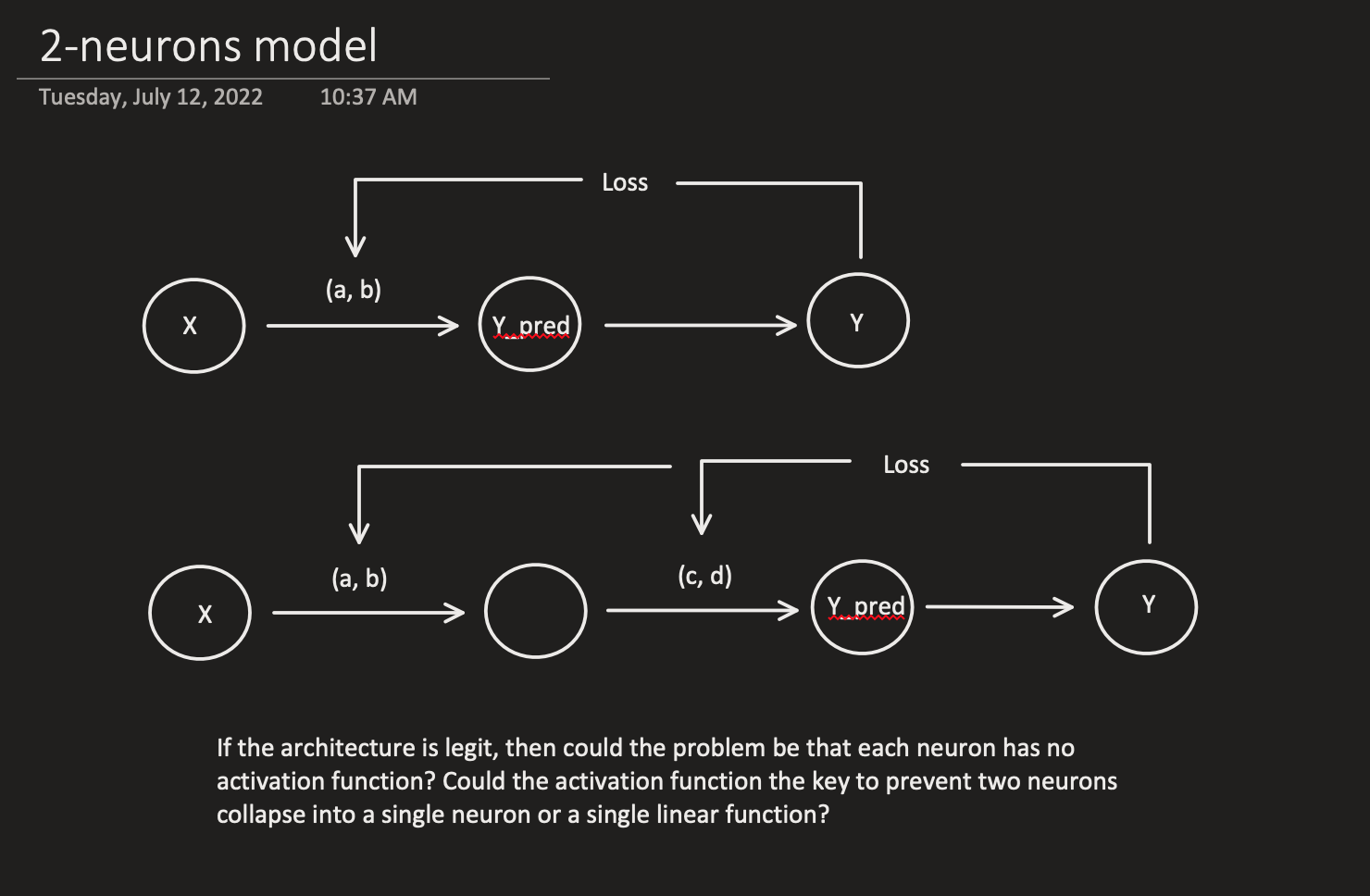
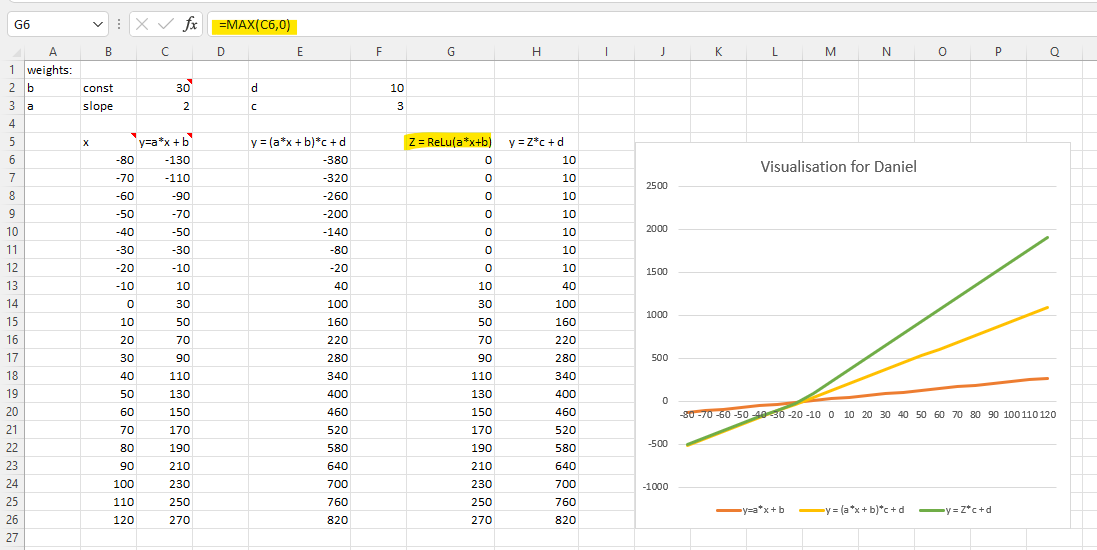
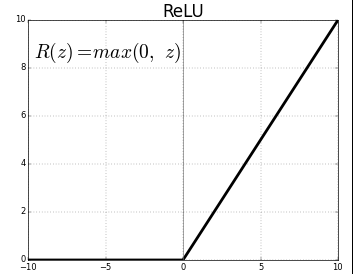
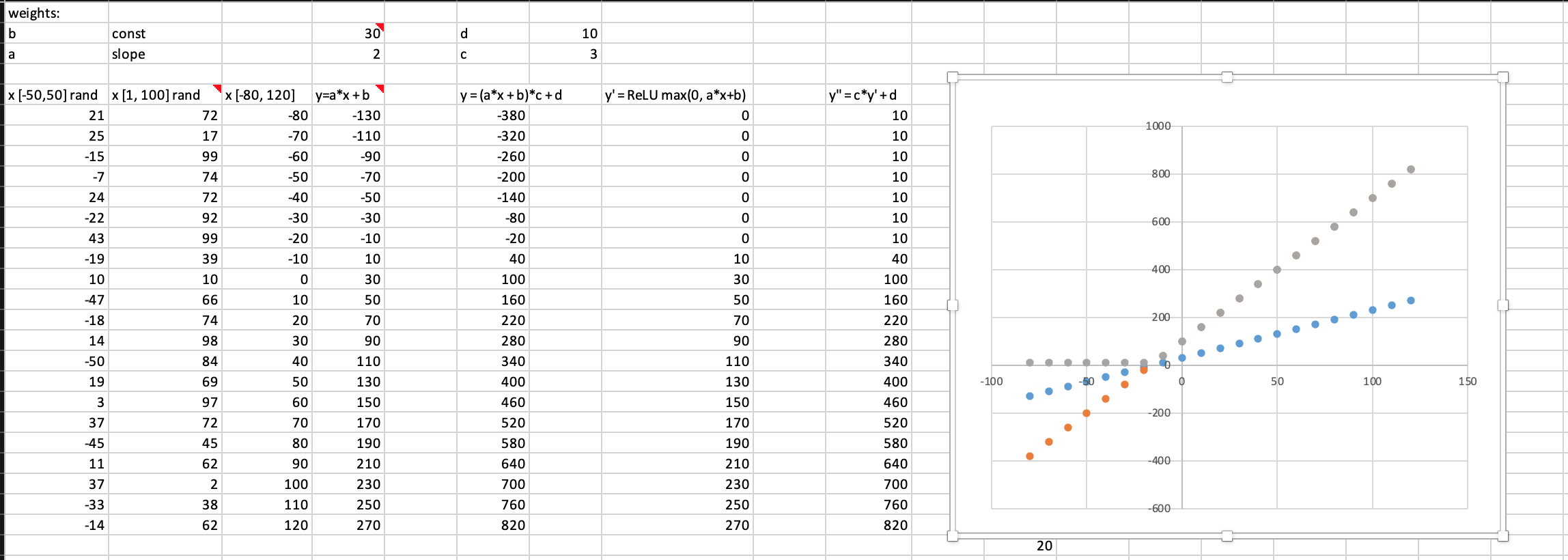
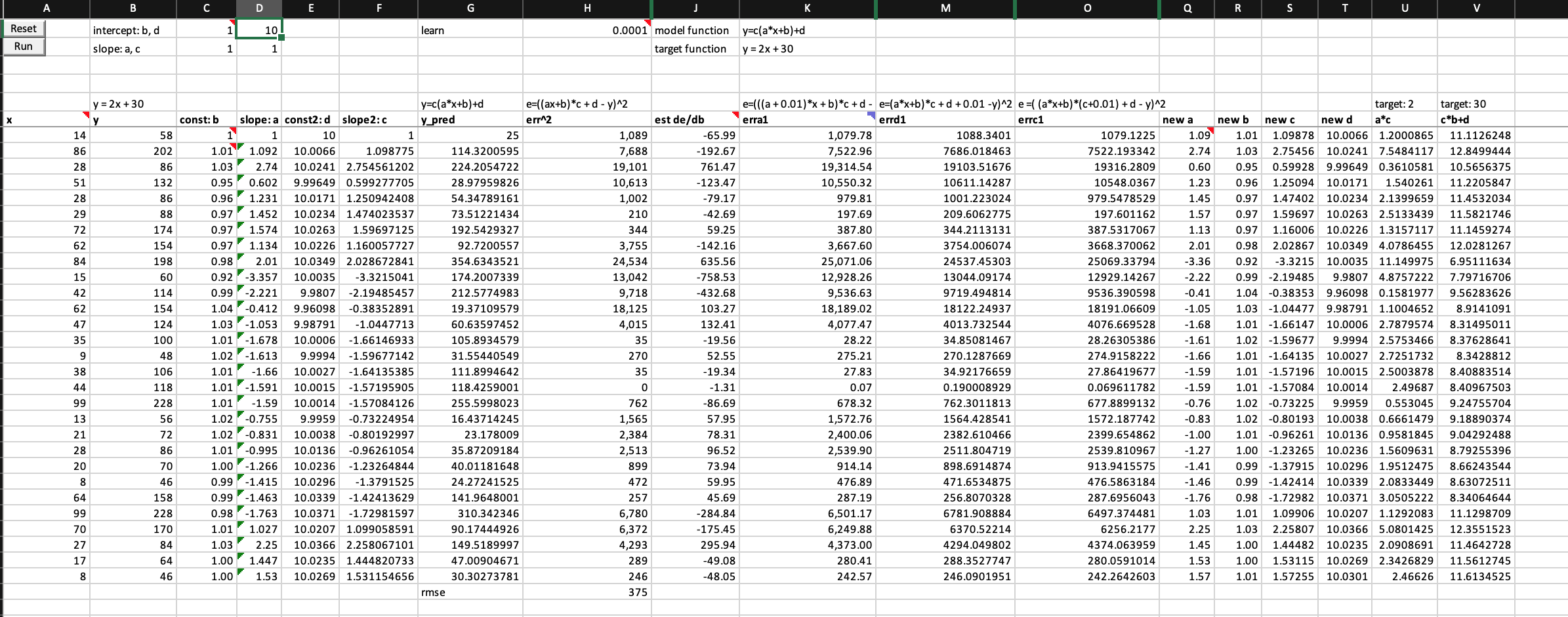
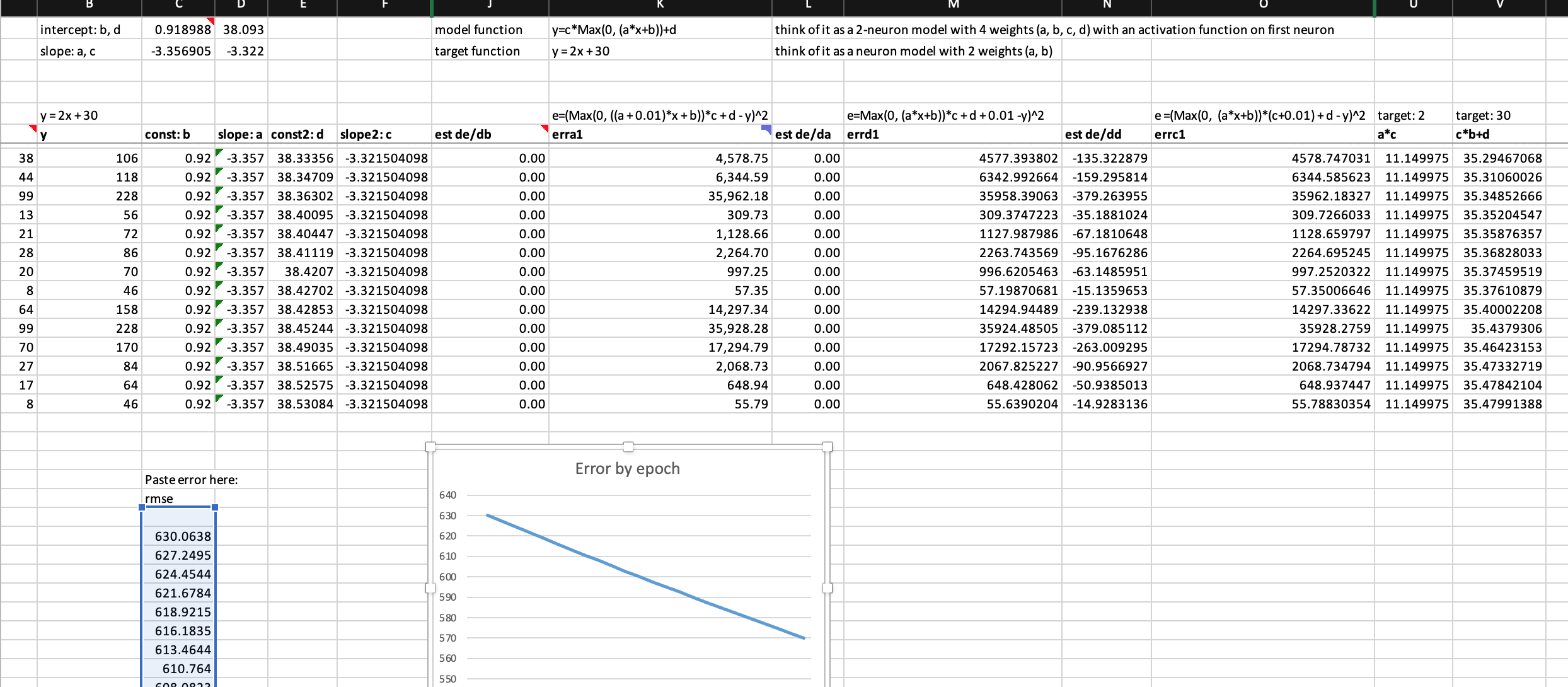
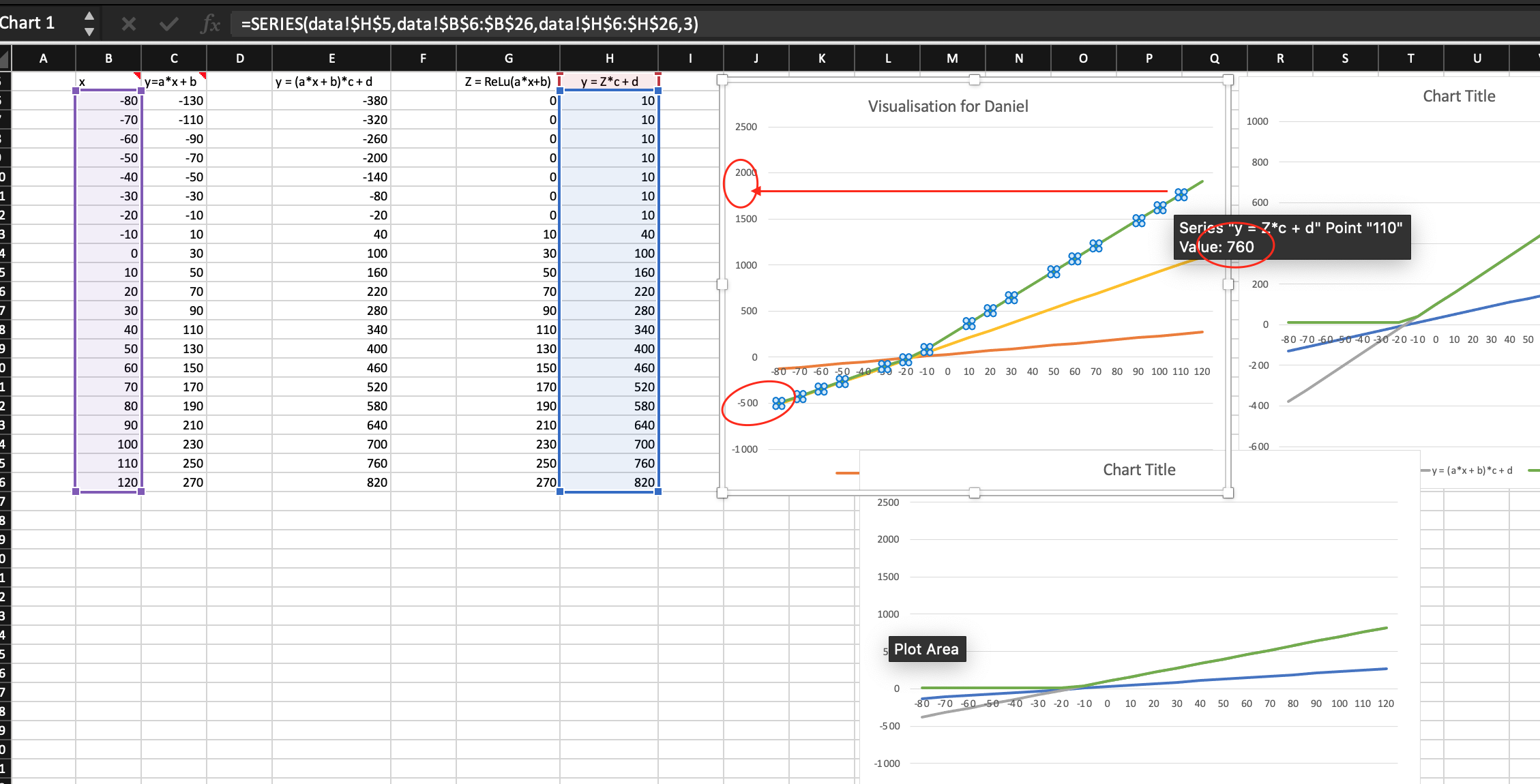
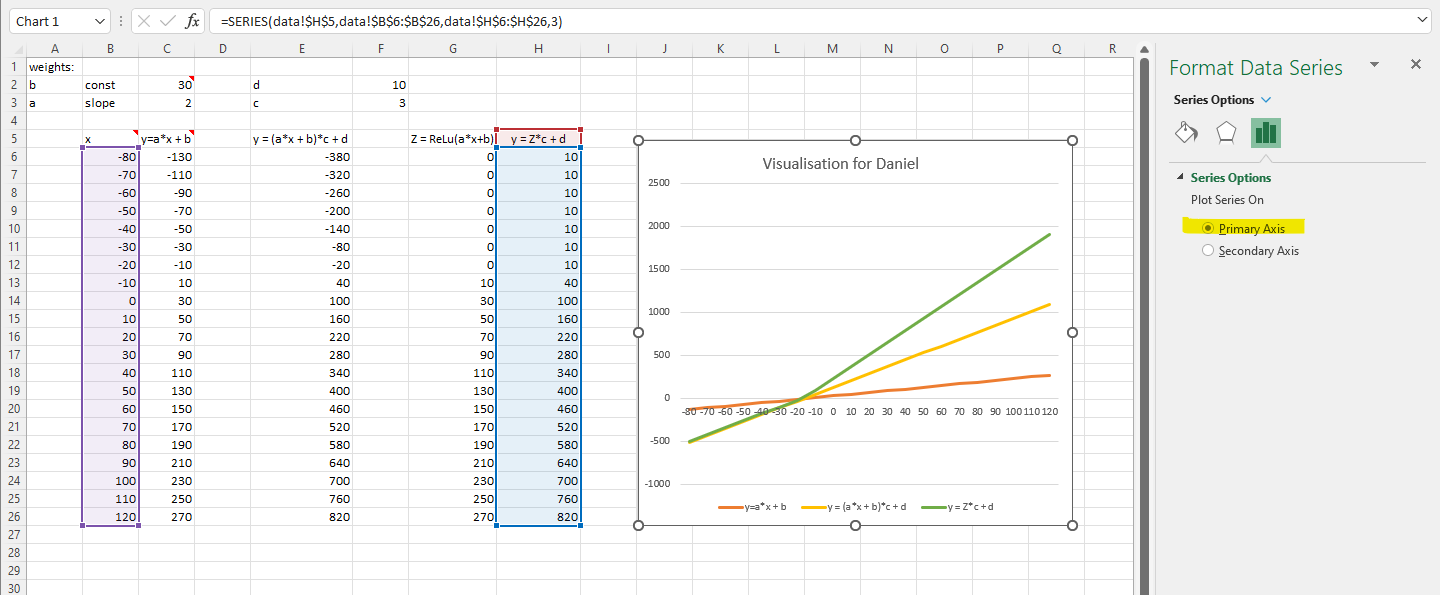
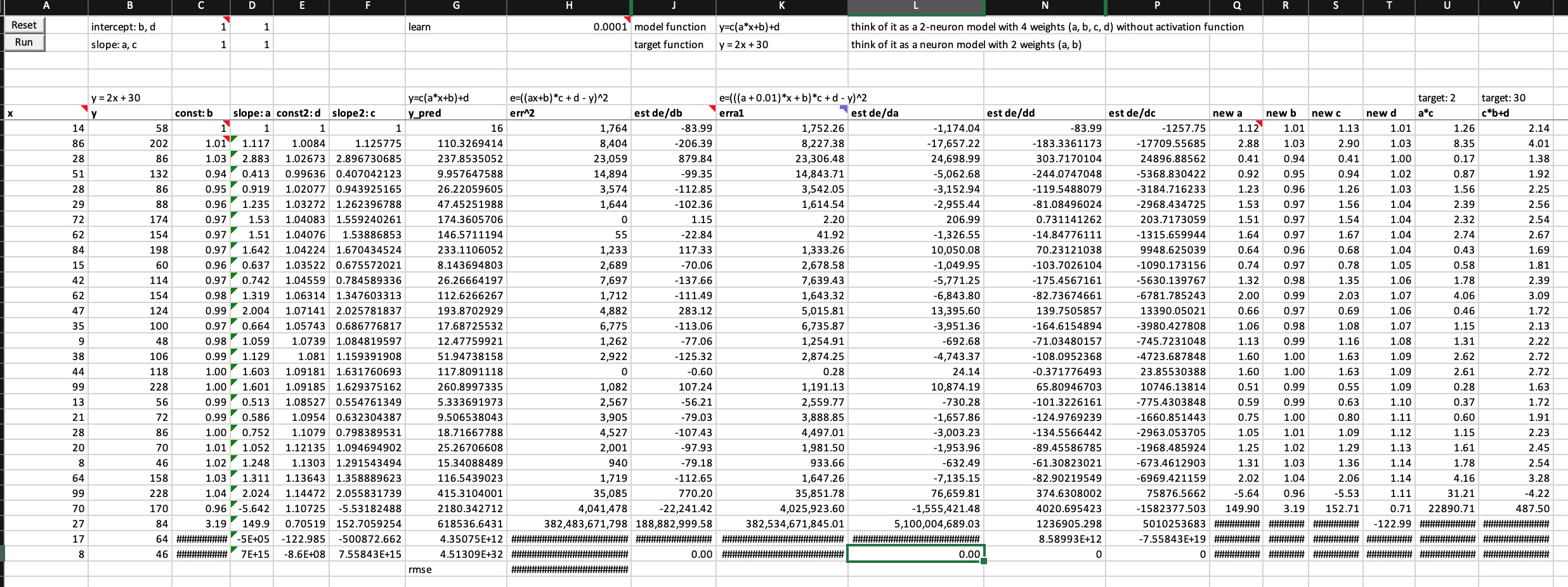
The first thing I want to experiment in the excel spreadsheet is to build a two-neuron architecture y = c*(a*x+b)+d (one linear function on top of another) instead of one neuron y = a*x + b in the excel. I don’t know much calculus, but what Jeremy showed us in the excel and lecture 5 2018 1:34:00 makes me willing to try.
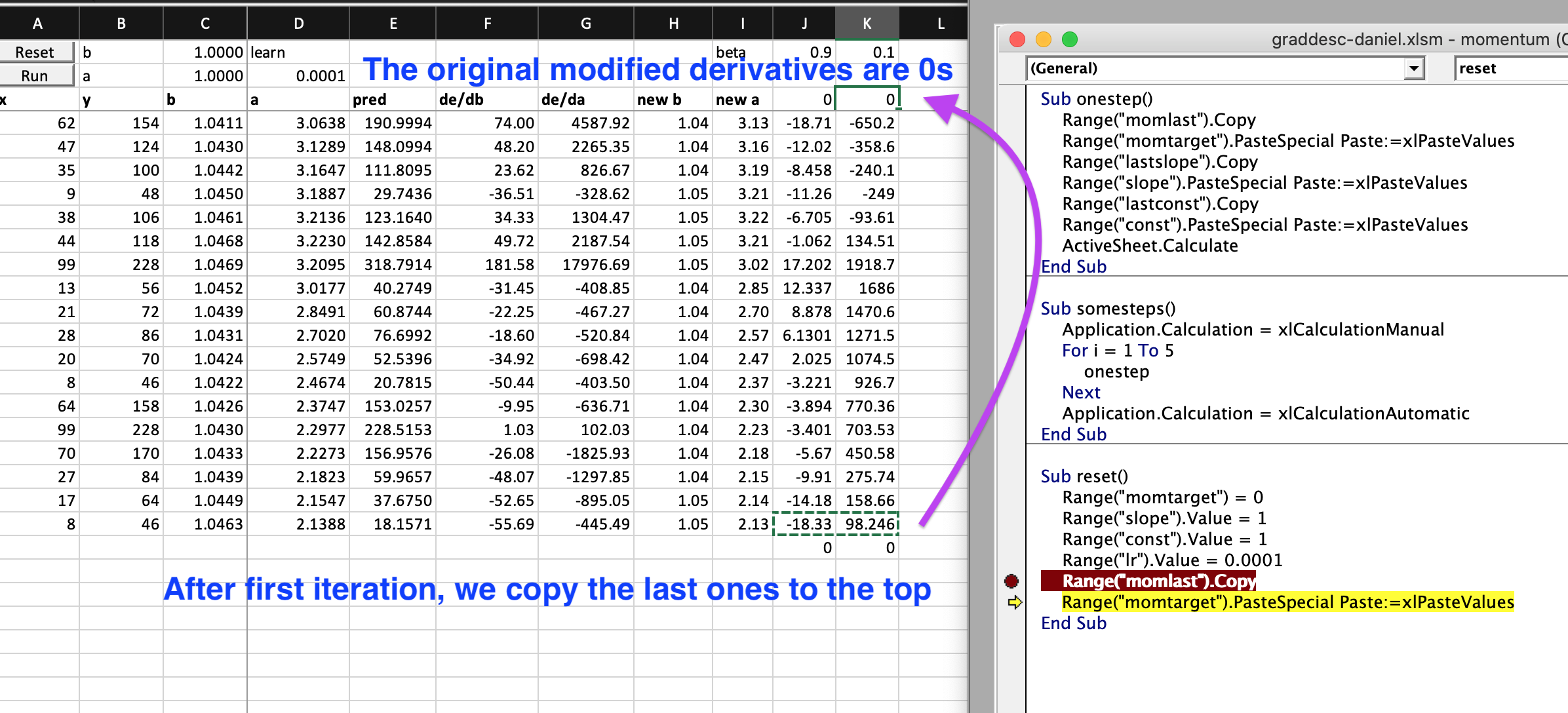
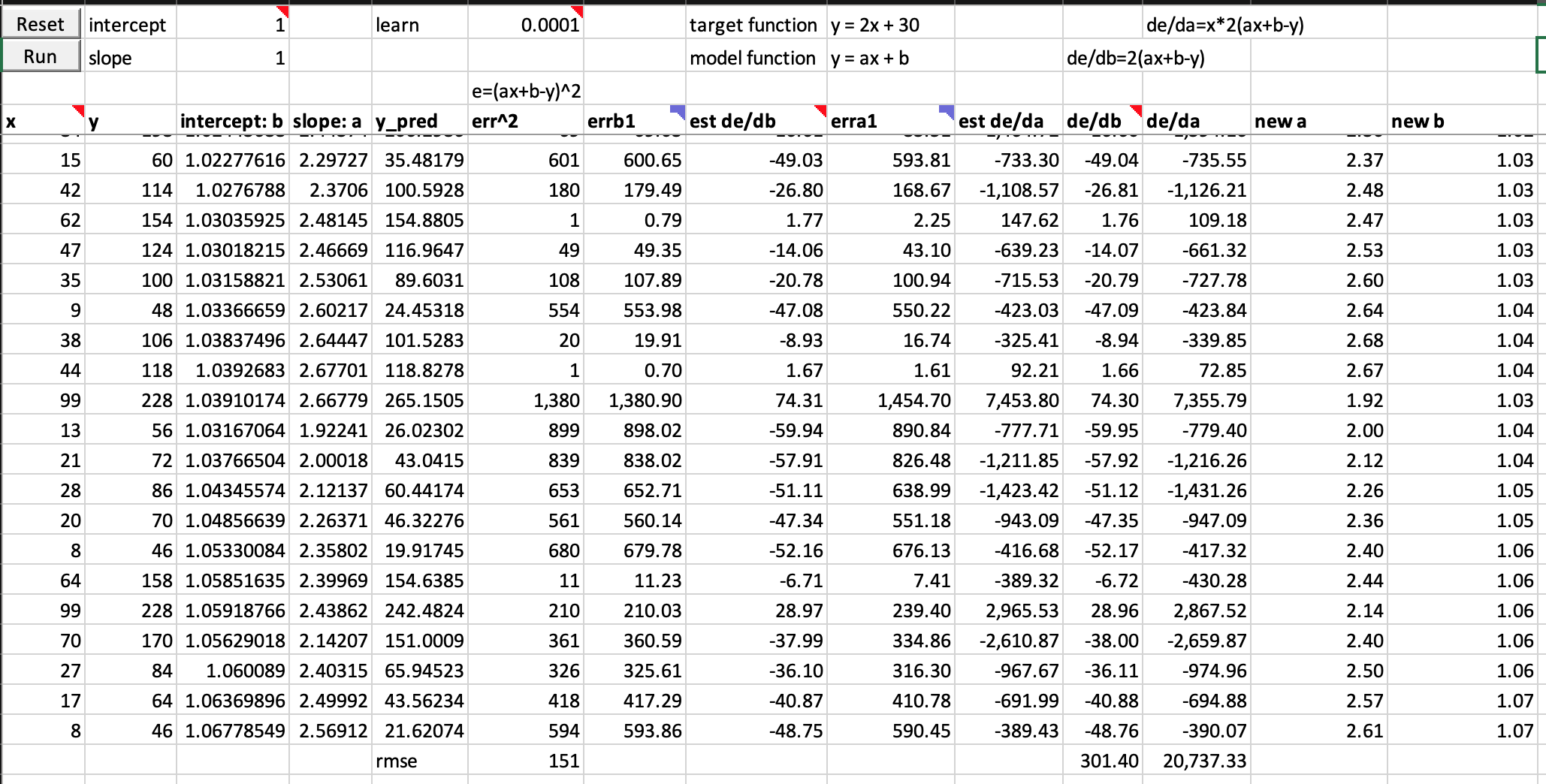
I have no school learning in calculus, but I sort of understand the basics of derivative through fastai videos and Ng’s videos. So, I am really thrilled to see that Jeremy put both numerical and analytical derivatives of a and b with respect to error in the excel and showed that there is not much difference between these two types of derivatives in the example. (I further tested that running SGD with estimated/numerical derivatives of a and b, the error rate going down with very similar values to using analytical derivatives.) This way, even with 4 weights in 2 neuron architecture, I don’t need to worry about searching online for 4 analytical derviative formula, instead I can calculate their numerical/finite derivatives with almost a single formula.
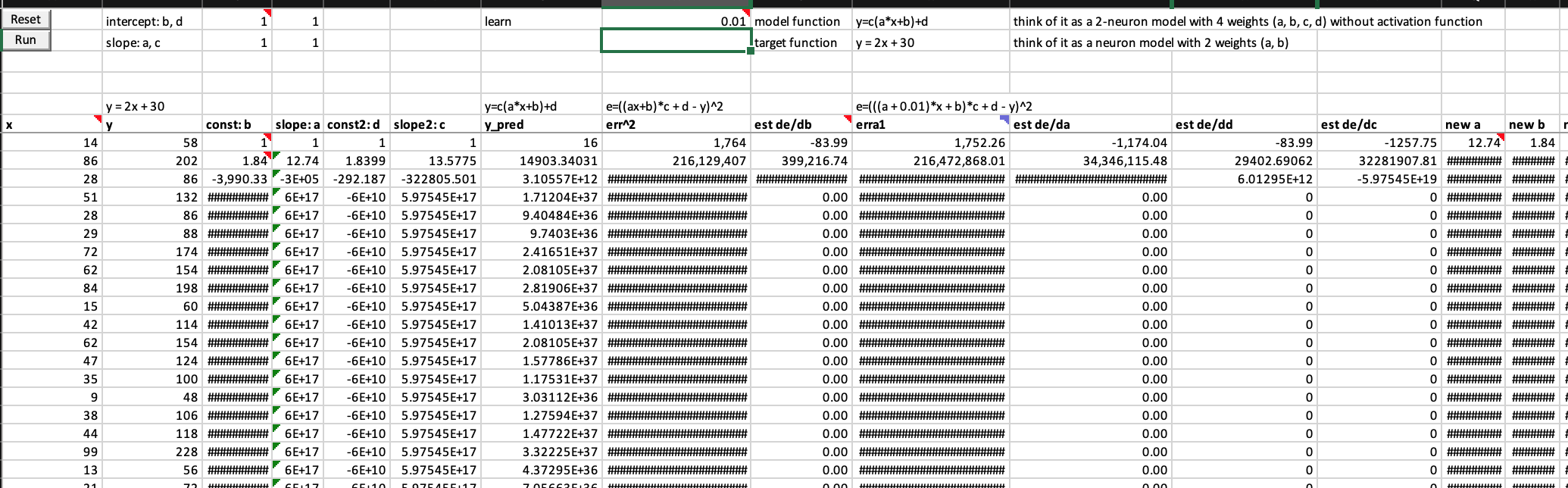
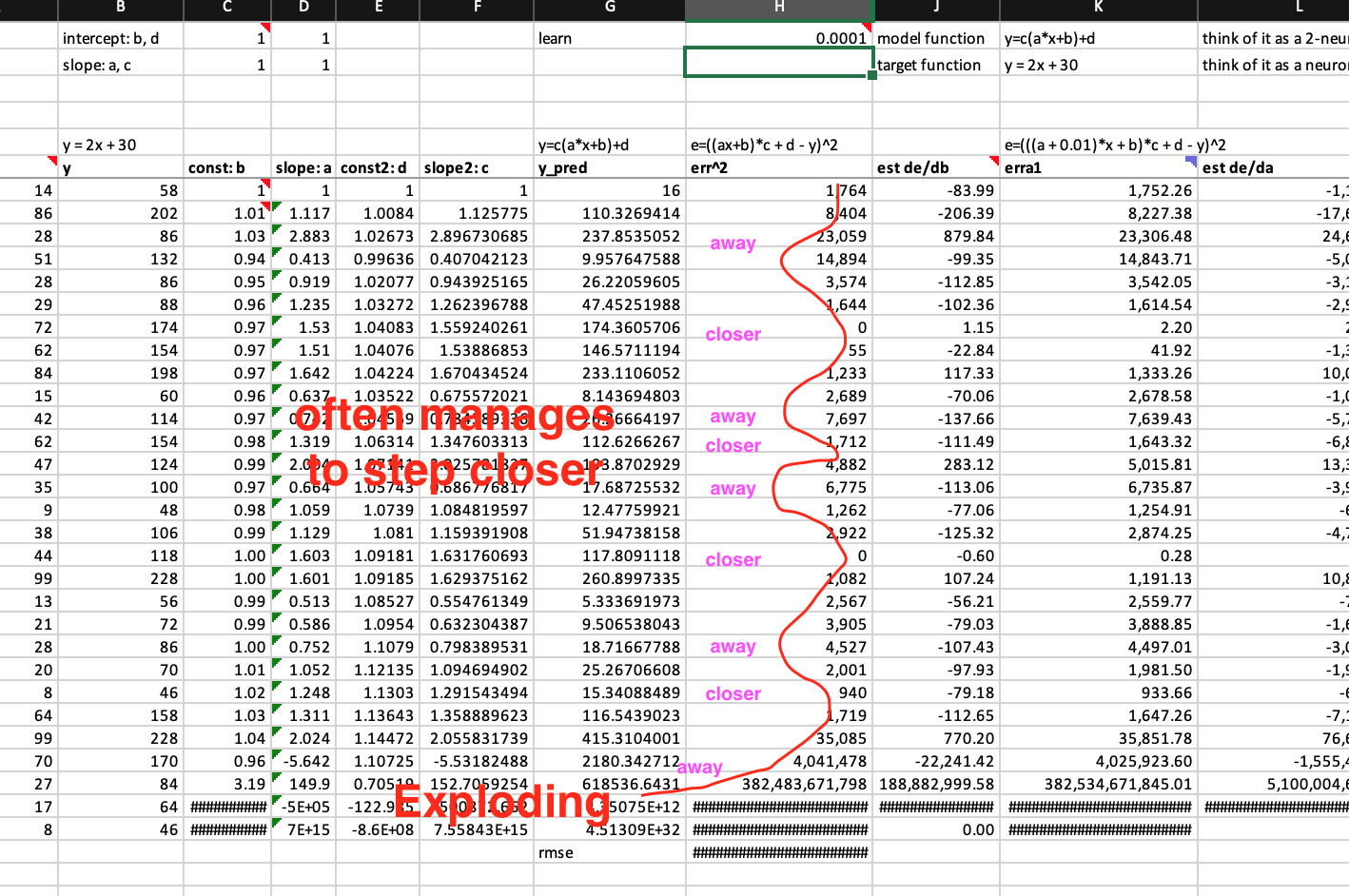
Are these correct numerical/finite derivatives of y = c*(a*x+b)+d? If not, what are the correct formula? I am not confident about it because error get exploded too fast.
Below is my worksheet named “basic SGD 2 neurons” in the workbook you can download from here