Walkthru 14, a rough detailed note
00:05 Early stopping: why you shall not use it, and what to do to not use it
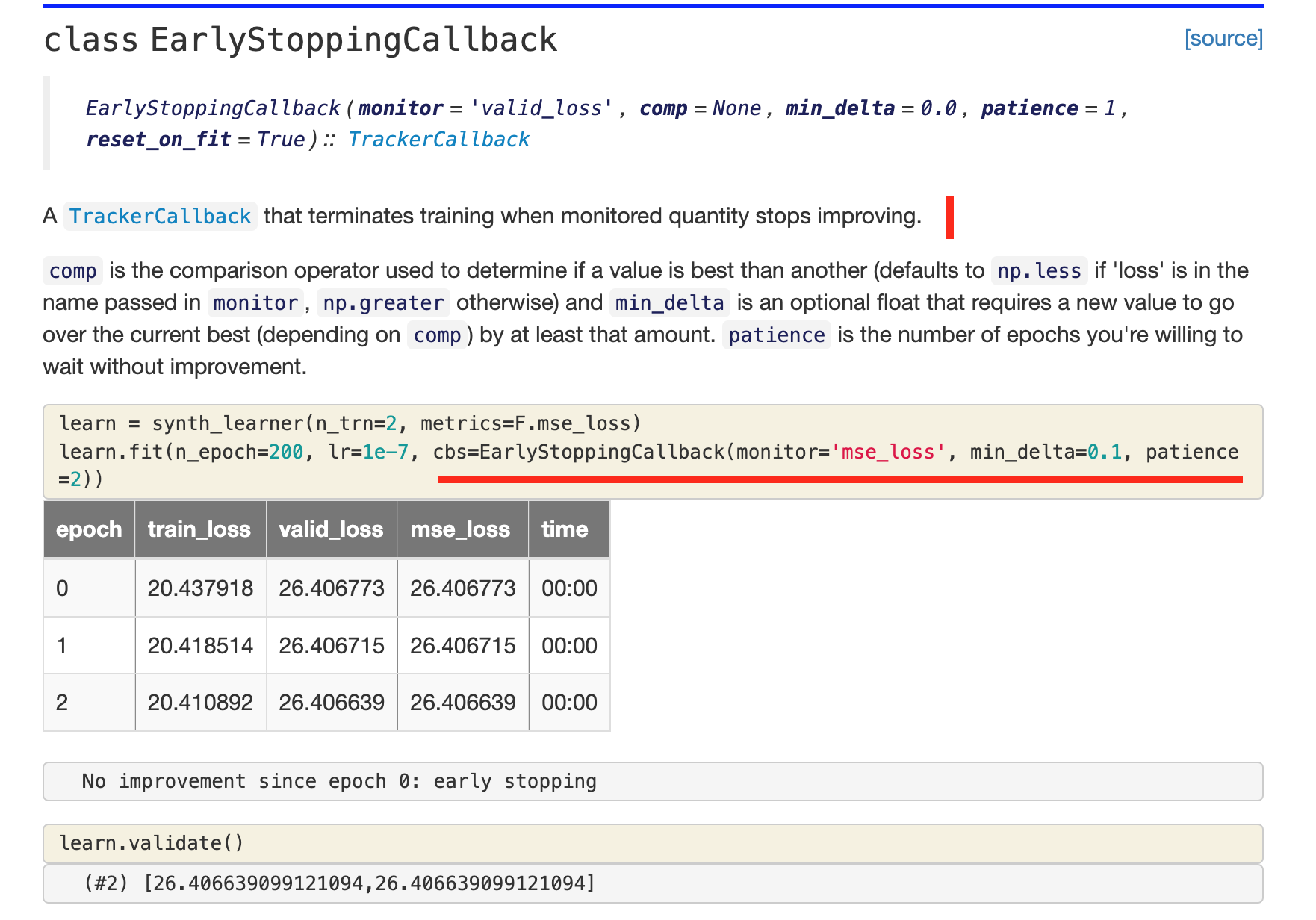
Why does Jeremy not use early-stopping even don’t know whether this callback exists?
Does early stopping play nicely with one cycle training or fine-tuning?
Does learning-rate have a chance to go down when early stopping?
Without learning-rate settles down, can early epochs give us better accuracy?
What does it mean when you see better accuracy in early epochs during one cycle training? 01:53
What will Jeremy do when he sees better accuracy in early epochs during one cycle training?
How does it help?
02:23 what if the last second epoch gives a better accuracy?
Why we can’t trust the model in the second last epoch to have the best weights during the training?
or why we should not use early stopping to get the model at the last second epoch?
hint: significant?
What can be the cause of the better accuracy at the second last epoch?
hint: not settled down
03:17 What’s Radek’s reason for why we should not read much into the better accuracy
hint: validation set, distribution
03:46 How much better of the accuracy should get our attention? and by what most likely?
hint: 4-500% better? architecture
03:59 Why ensembling a lot of neural nets models can easily overfit and does not help much?
hint: neuralnet is flexible enough
Why Jeremy not recommend to do ensemble on totally different types of models even though they have a better chance than similar types? 06:34
hint: mostly one type is much better than other types
When to try these ensembles may be justified?
hint: super tiny improvement to win a medal on Kaggle
07:25 Jeremy talked about AutoML tools on Lecture 6
I have not watched yet
07:50 Why Kaggle competition winners usually talking about complex ensembling methods?
hint: no more low hanging fruits
If ensembling is the top hanging fruit, then what are the low hanging fruits?
What can beat ensembling?
hint: a new novel architecture
08:54 Why Test Time Augmentation can practically improve accuracy?
hint: see it better when taking different angles
How does the final target get picked from 5 different predictions?
dig in
docs of tta

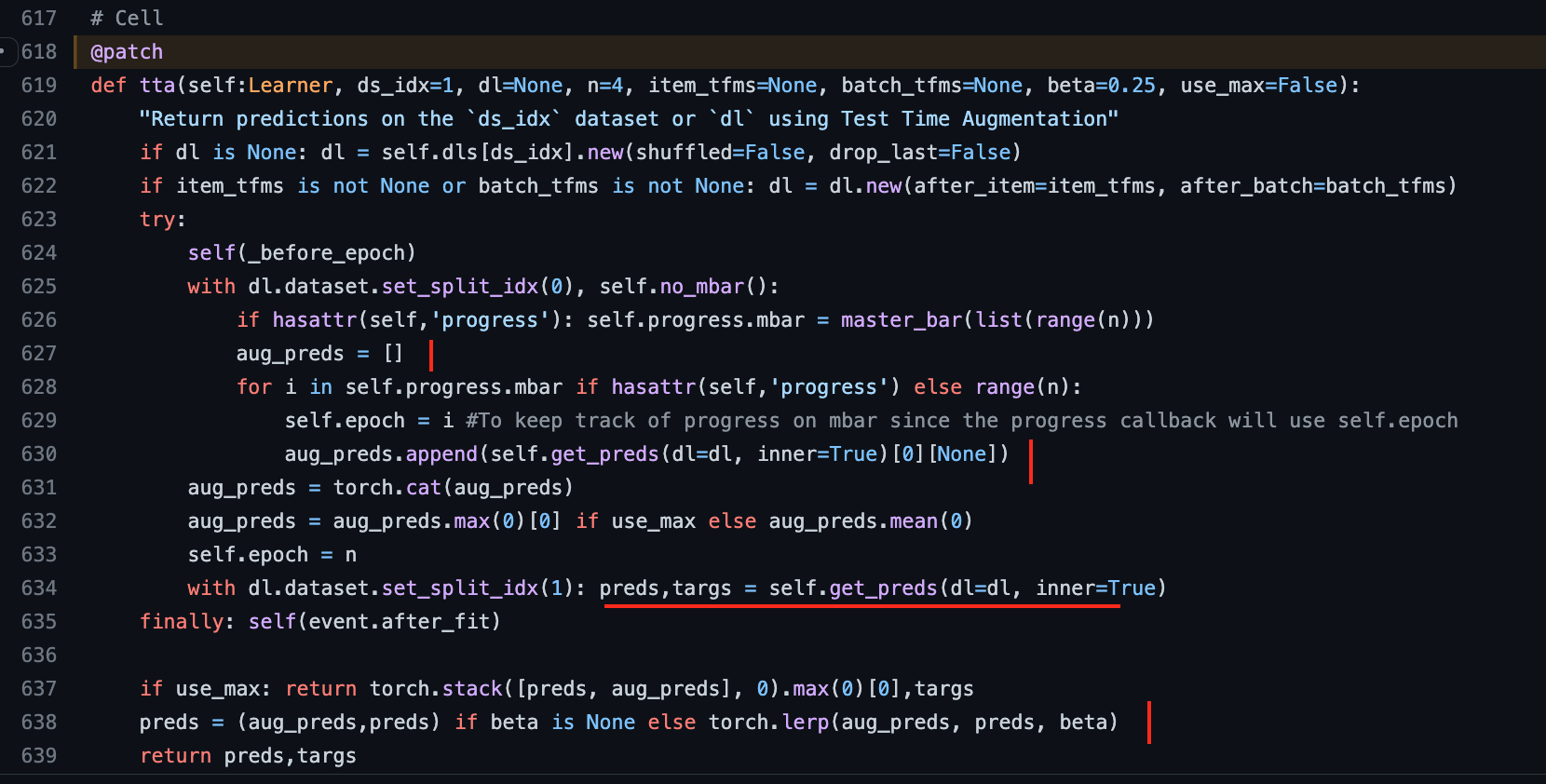
However, Jeremy did explain how tta work in previous walkthru 9, check the notes here
10:53 Why average out all the predictions from Test-time augmentation can improve the accuracy?
hint: manage the overconfidence of the model to do no/less harm
How do you know our model get overconfident?
hint: training accuracy vs validation accuracy
Is overconfident acceptable as long as it is not overfitting?
When do we need to manage overconfidence, during training vs during testing?
13:50 When dataset is unbalanced, should you ever throw away some from highly represented class?
hint: never
Should we over sample some less represented class? How to do it? 15:20
docs on WeightedDL
Why Jeremy think this over-sampling technique won’t help? 16:19
hint: training vs test data distributions, how highly unbalanced the datasets are
Tanishq shared experience of using over-sampling or unbalanced dataset to improve performance 17:57
20:54 Getting started with Jeremy’s multitask notebook
How to use one of your local multi-GPU?
Get started 22:49
debugging: why the notebook is not working this time 23:36
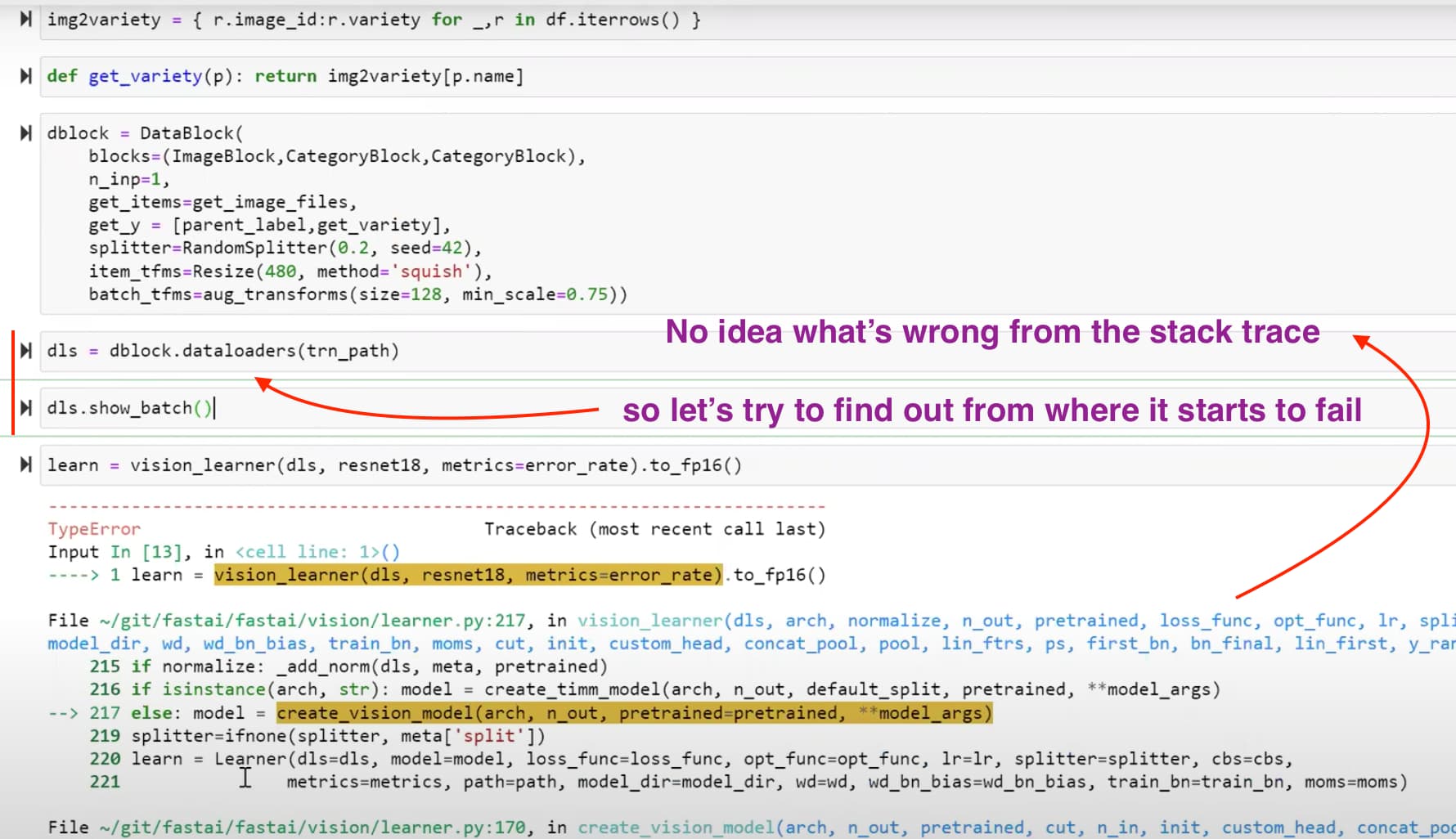
Reminder: what we have built previously into the multitask model 24:43
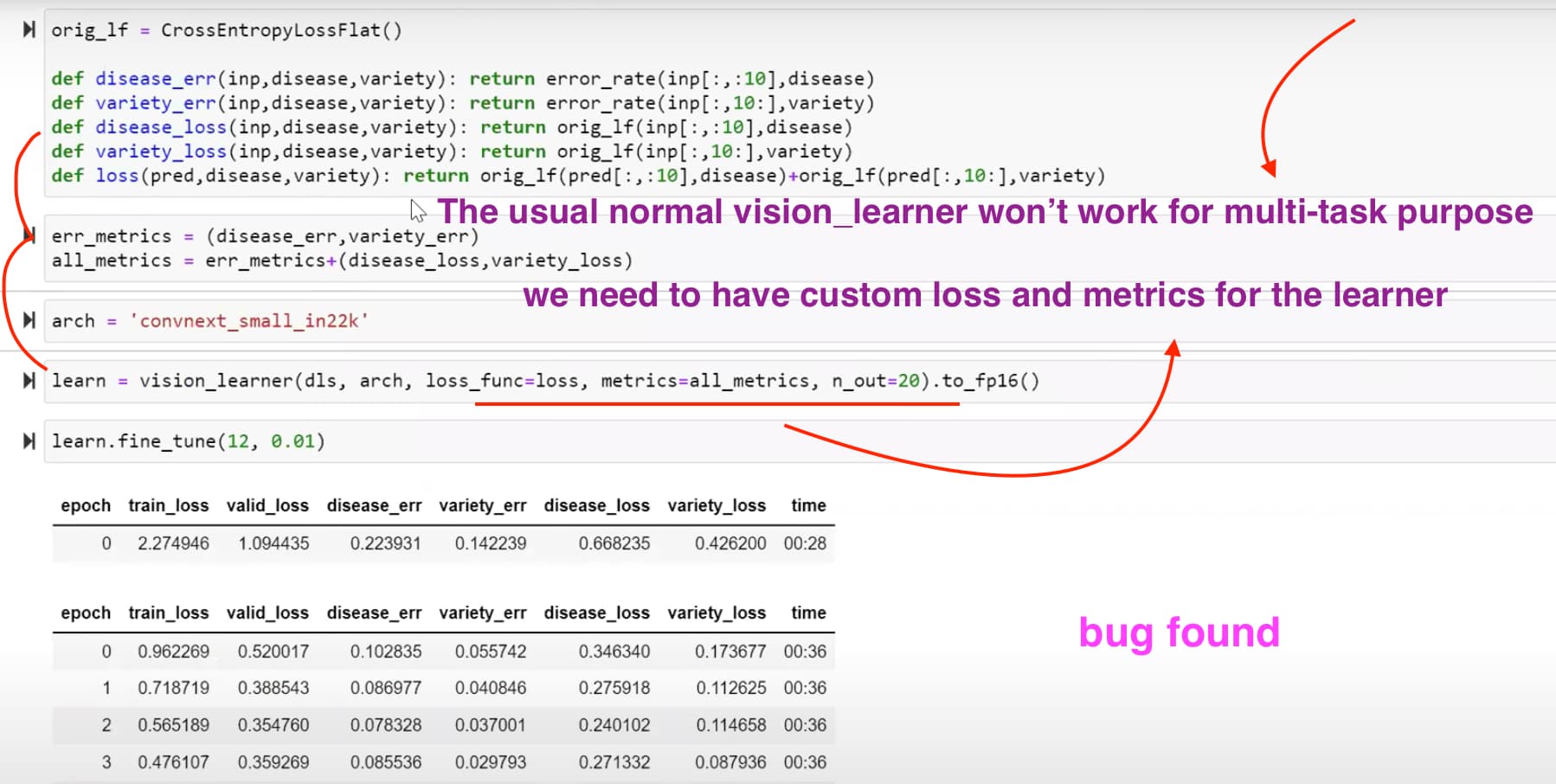
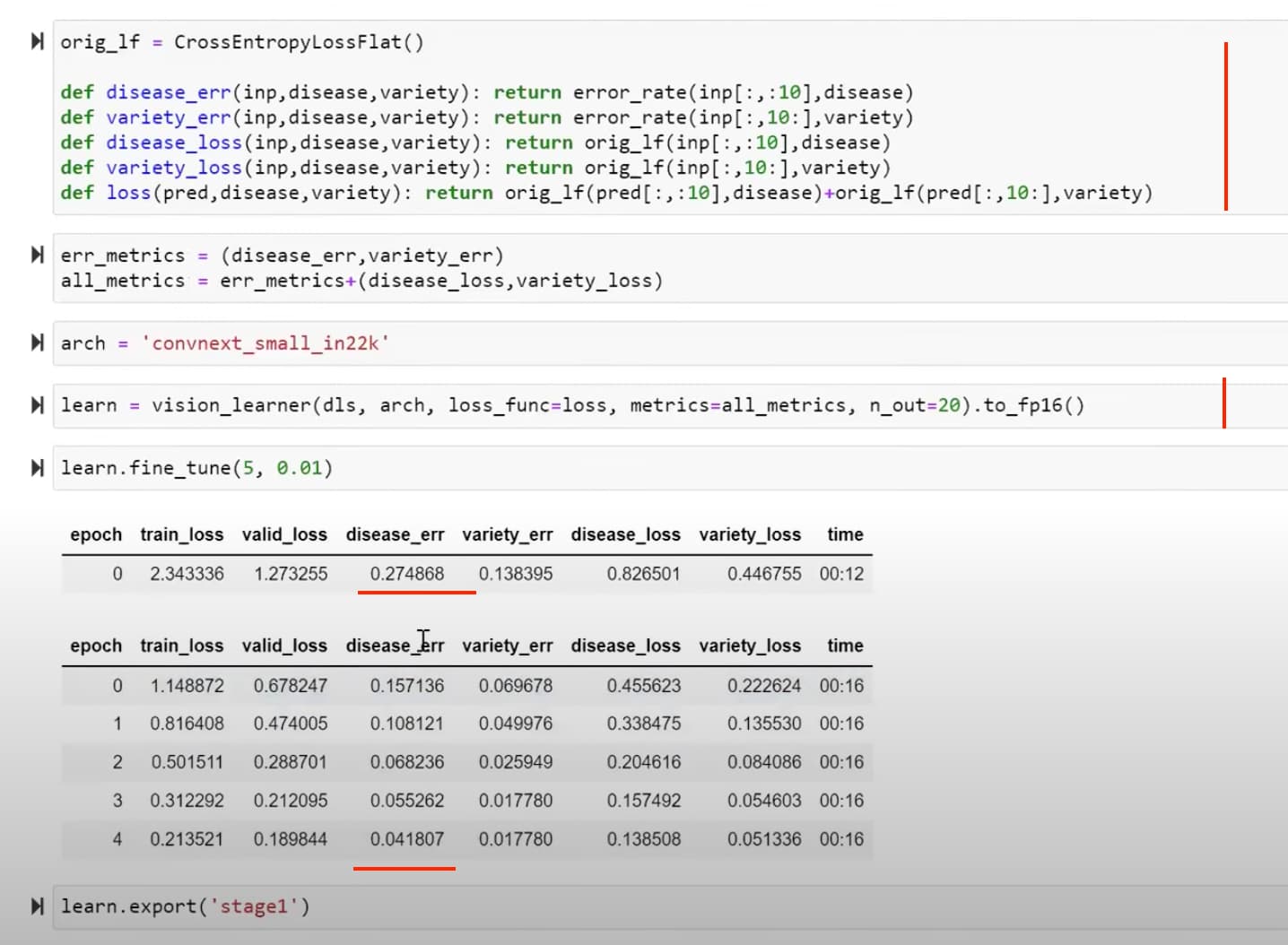
25:11 Get our base multitask model running to compare with the base model in kaggle notebook
What does Jeremy’s kaggle base model look like?
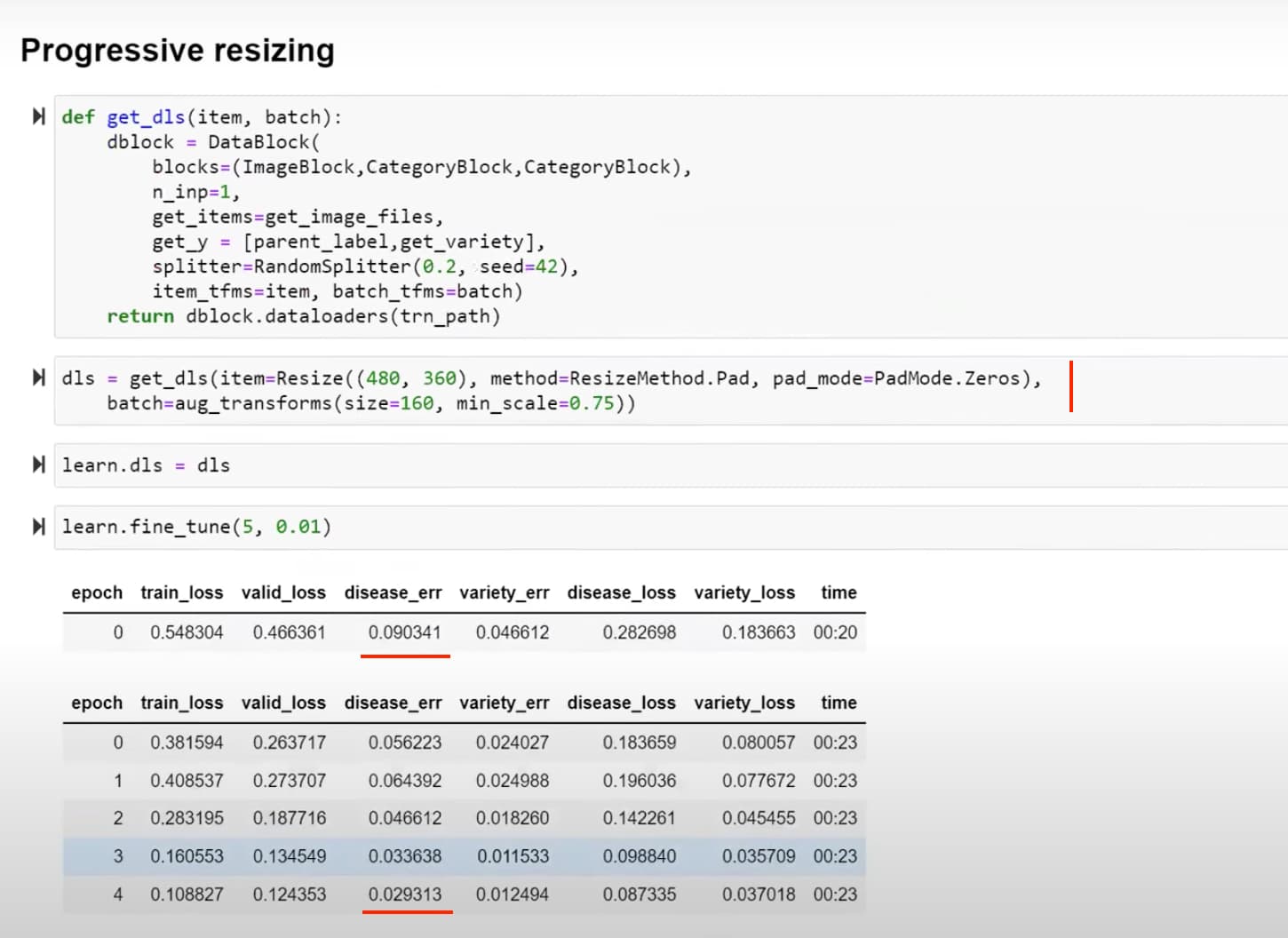
27:54 Progressive resizing
When will we usually move on from models with smaller images to ones with larger images? 28:58
33:52 How Jeremy evaluate multi-task model with the base model? Why should multi-task model be better with 20 than just 5 epochs
hint: multi-task models design (give more signals) enable more epochs without overfitting
Another interesting approach: Why use the same model and continue to train with larger images? 29:09
hint: 1. fast even with larger paddy images; 2. kind of added data aug as different sized images
30:36 How Jeremy built a progressive resize model based on padding and larger images 160 vs 128 in previous model?
continued from 34:30
How to build such progressive resizing model properly
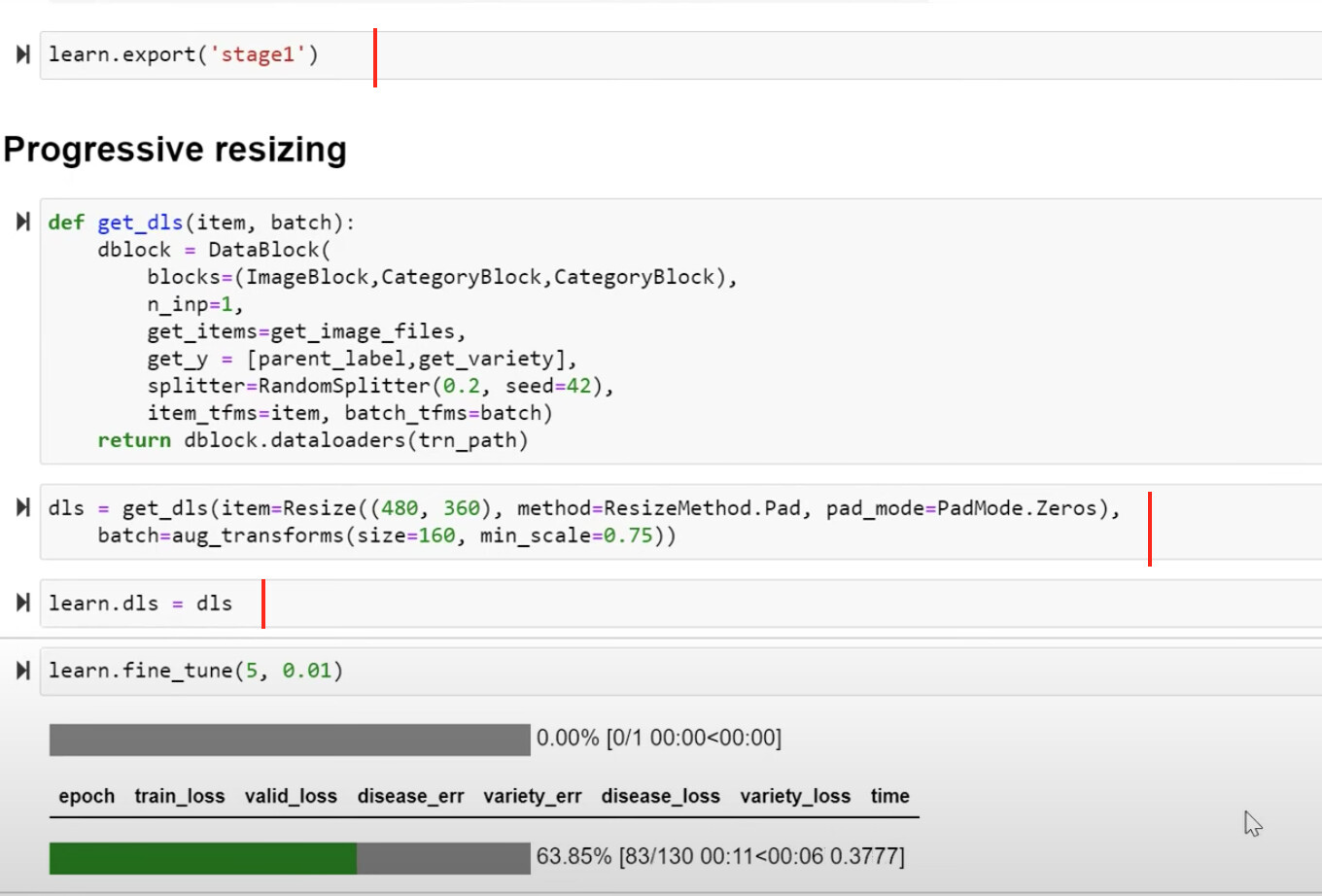
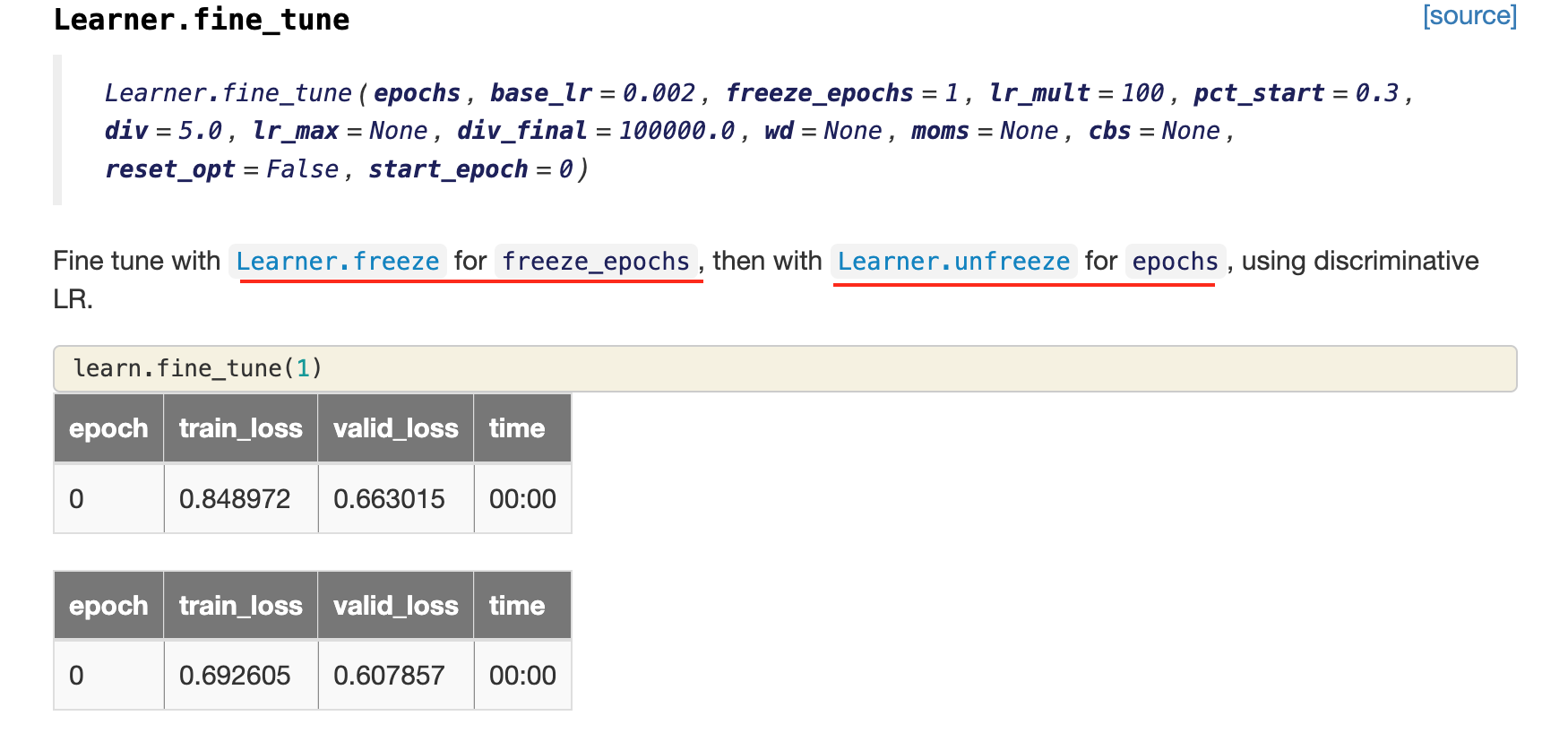
Why Jeremy want to freeze the pretrained model and train the last layer first?
Does fine_tune call freeze first?
Does progressive mean keep changing image sizes? 36:56
hint: without changing the learner, keep changing image sizes
37:27 Why the accuracy of the first epoch of the first progressive resizing model is not as good as its previous model?
The first epoch accuracy of this progressive resizing model is better than its previous model after its first epoch. Can you guess why?
but it is worse than the previous model after its 5 epochs. Can you guess why?
38:01 A very very brief story of progressive resizing
invented by Jeremy in a Kaggle competition and took it a step further by google with a paper
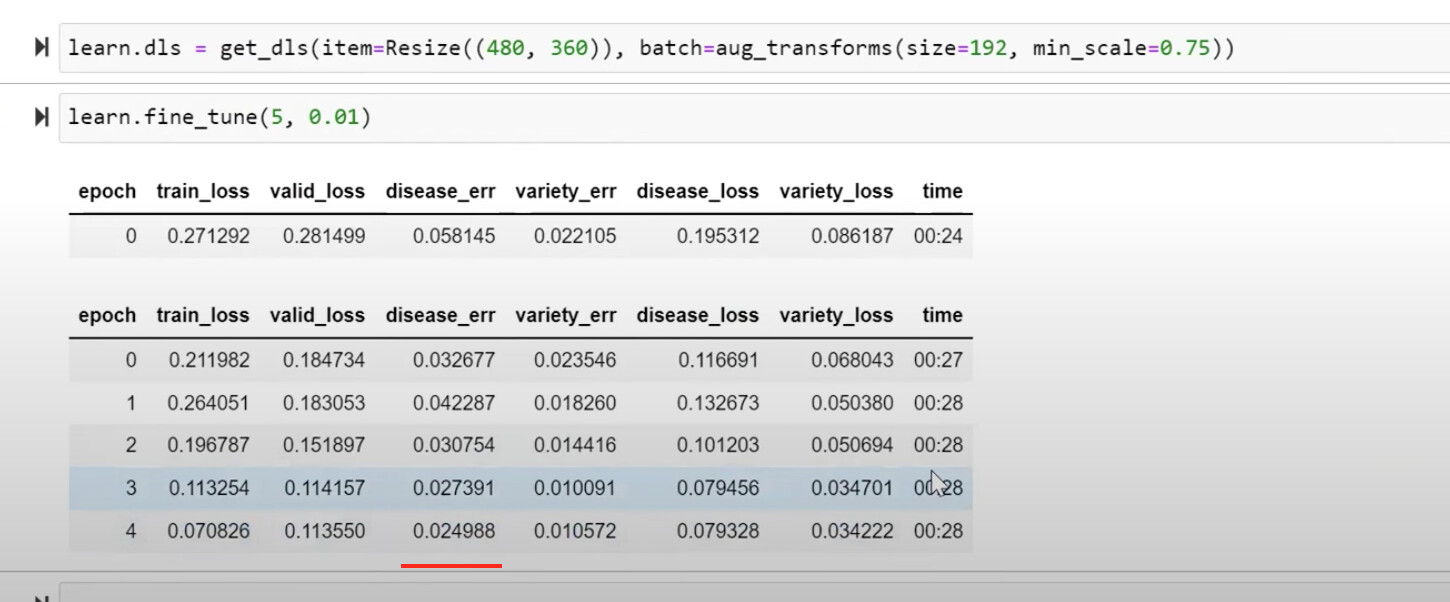
39:09 Did our first progressive resizing model beat its predecessor?
a lot better: 0.029 vs 0.041
40:04 How did Jeremy invent progressive resizing?
hint: 1. why use large images to train weights when small images can do; 2. inspriation from changing learning rate during training, why not image size
42:34 Potential comparison experiment: which one is better, models training on 224 and predicting on 360 vs models training first on 360, then on 224, and finally predicting on 360
On the paper Fixing the train-test resolution discrepancy 2
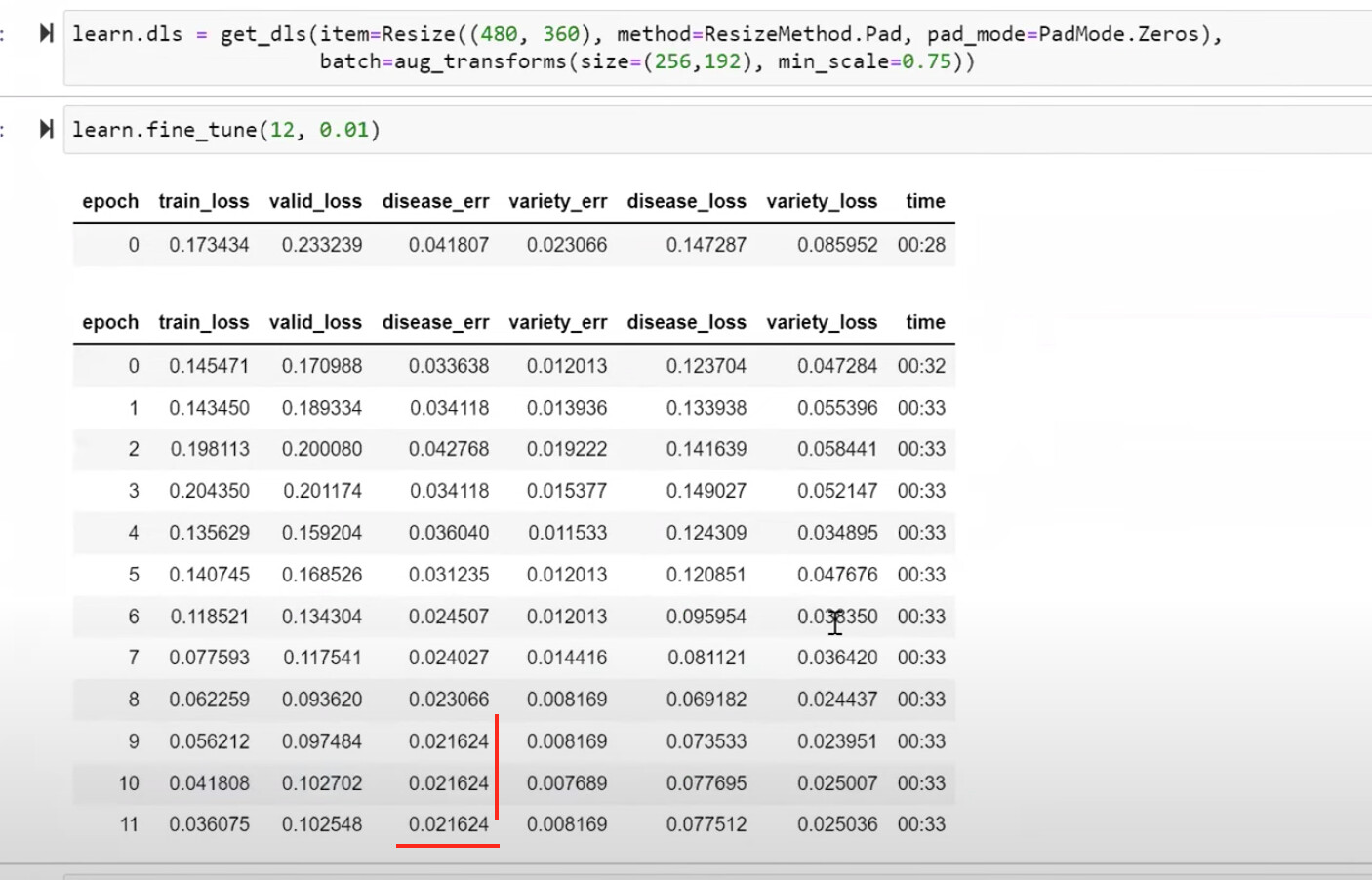
44:05 Build a second progressive resizing (pr) model with even larger images without the item_tfms of first pr model above
46:10 pinboard and other app to manage papers and ‘oh, shit’ on a finding on long covid
48:25 Build and train on larger and rectangular images with padding transforms
49:34 How to use your local second GPU to work on a second notebook?
50:29 How does WeightedDataLoader work?
How to use WeightedDataLoaders according to its docs and source? 51:00
59:13 How to save model during training? Why we should not do it neither?
About SaveModelCallback
1:00:56 How to document fastai lib with just comments, and why should you do it?
fastcore’s document
1:03:47 Why Jeremy doesn’t use lr_find any more?
1:04:49 What would happen and what to do if you want to keep training after 12 epochs?
If the error-rate gets better but validation loss worse, is it overfitting?
no, it is just overconfident
What would happen to your learning rate if you continue to train with fit_one_cycle or fine_tune?
hint: learning rate up and down in cycles, so reduce learning rate by 4-5 times to keep training
What would Jeremy do to learning rate when he re-run the code above?
hint: halve lr each time/model
1:06:16 Does any layer of the model get reinitialized when doing progressive resizing due to different image sizes? No
Is convnext model resolution independent? what does it mean?
it means the model works for any image input resolution
Why convnext model can be resolution independent? 1:07:21
hint: it’s just a matter of more or less matrix patches
1:07:49 Is there a trick we can turn resolution dependent models resolution independent with timm? Interesting to see whether this trick can also work with progressive resizing
1:08:58 Why Jeremy does not train models on the entire training set (without splitting data to validation set)? and what does Jeremy do about it?
hint: ensembling, all dataset is seen, validating